Limbu skript - Limbu script
| Limbu ᤕᤰᤌᤢᤱ ᤐᤠᤴ | |
|---|---|
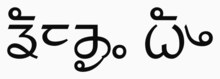 | |
| Typ | |
| Jazyky | Limbu |
Časový úsek | C. 1740 – dosud |
Mateřské systémy | |
| Směr | Zleva do prava |
| ISO 15924 | Končetina, 336 |
Alias Unicode | Limbu |
| U + 1900 – U + 194F | |
[a] Semitský původ Brahmických skriptů není všeobecně dohodnut. | |
| Brahmické skripty |
|---|
| Brahmické písmo a jeho potomci |
Jižní Brahmic |
The Limbu skript (také Sirijanga script)[1] se používá k napsání Limbuština. Je to Brahmic typ abugida.[2]
Dějiny
Podle tradičních dějin byl skript Limbu poprvé vynalezen koncem 9. století autorem Limbu Král Sirijunga Hang, který poté přestal být používán, měl být v 18. století znovu zaveden Limbuským učencem Te-ongsi Sirijunga Xin Thebe v době, kdy byla výuka Limbu skriptu postavena mimo zákon Limbuwan a Sikkim.
Účty se Sirijunga
The Limbuština je jedním z mála Čínsko-tibetský jazyky střední Himaláje vlastnit vlastní skripty. (Sprigg 1959: 590), (Sprigg 1959: 591-592 & MS: 1-4) nám říká, že Limbu nebo Sirijunga skript byl vytvořen během období buddhistické expanze v Sikkim na počátku 18. století, kdy Limbuwan stále představoval část území Sikkimese. The Limbu skript byl pravděpodobně složen zhruba ve stejné době jako Skript Lepchy který vytvořil třetí král Sikkimu, Chakdor Namgyal (asi 1700-1717). The Limbu skript je připisován Limbu hrdina, Te-ongsi Sirijunga Xin Thebe.
Struktura

Jako abugida, základní písmeno představuje souhlásku i inherentní nebo výchozí samohlásku. v Limbu, inherentní samohláska je / ɔ /.
| Transkripce | ko | kho | jít | gho | ngo | co | cho | jo | na | tho | dělat | dho | Ne | po | pho | bo | bho | mo | jo | ro | hle | vo | sho | tak | ho |
| IPA | / kɔ / | / kʰɔ / | / ɡɔ / | / ɡʱɔ / | / ŋɔ / | / cɔ / | / cʰɔ / | / ɟɔ / | / tɔ / | / tʰɔ / | / dɔ / | / dʱɔ / | / nɔ / | / pɔ / | / pʰɔ / | / bɔ / | / bʱɔ / | / mɔ / | / jɔ / | / rɔ / | / lɔ / | / s / | / ʃɔ / | / sɔ / | / hɔ / |
| Dopis | ᤁ | ᤂ | ᤃ | ᤄ | ᤅ | ᤆ | ᤇ | ᤈ | ᤋ | ᤌ | ᤍ | ᤎ | ᤏ | ᤐ | ᤑ | ᤒ | ᤓ | ᤔ | ᤕ | ᤖ | ᤗ | ᤘ | ᤙ | ᤛ | ᤜ |
Chcete-li změnit vlastní samohlásku, diakritika je přidáno:
| Transkripce | -A | -i | -u | -ee | -ai | -oo | -au | -E | -Ó |
| IPA | /A/ | / i / | / u / | /E/ | / ai / | /Ó/ | / au / | / ɛ / | / ɔ / |
| Diakritický | ᤠ | ᤡ | ᤢ | ᤣ | ᤤ | ᤥ | ᤦ | ᤧ | ᤨ |
| Příklad použití ᤁ | ᤁᤠ / ka / | ᤁᤡ / ki / | ᤁᤢ / ku / | ᤁᤣ / ke / | ᤁᤤ / kai / | ᤁᤥ / ko / | ᤁᤦ / kau / | ᤁᤧ / kɛ / | ᤁᤨ / kɔ / |
ᤁᤨ / kɔ / představuje stejnou slabiku jako ᤁ / kɔ /. Někteří autoři se vyhýbají ᤨ diacritic, považovat to za nadbytečné.
Slabiky - počáteční samohlásky používají samohlásku ᤀ s příslušným znakem závislé samohlásky. Používá se samo o sobě, ᤀ představuje počáteční slabiku / ɔ /.
Počáteční shluky souhlásek jsou psány malými značkami za hlavní souhláskou:
| Transkripce | -y- | -r- | -w- |
| IPA | / j / | / r / | / w / |
| Diakritický | ᤪ | ᤫ | ᤩ |
| Příklad použití ᤁ | ᤁᤪ / kjɔ / | ᤁᤫ / krɔ / | ᤁᤩ / kwɔ / |
Konečné souhlásky po krátkých samohláskách jsou psány s jinou sadou značek, s výjimkou některých koncových souhlásek vyskytujících se pouze v půjčkách. Sledují značky pro shluky souhlásek, pokud existují.
| Transkripce | -k | -ng | -t | -n | -p | -m | -r | -l |
| IPA | / k / | / ŋ / | / t / | / n / | / p / | / m / | / r / | / l / |
| Diakritický | ᤰ | ᤱ | ᤳ | ᤴ | ᤵ | ᤶ | ᤷ | ᤸ |
| Příklad použití ᤁ | ᤁᤰ / kɔk / | ᤁᤱ / kɔŋ / | ᤁᤳ / kɔt / | ᤁᤴ / kɔn / | ᤁᤵ / kɔp / | ᤁᤶ / kɔm / | ᤁᤷ / kɔr / | ᤁᤸ / kɔl / |
Dlouhé samohlásky bez následující koncové souhlásky jsou psány s diakritikou kemphreng (᤺). Například, ᤁ᤺ / kɔː /.
Existují dvě metody psaní dlouhých samohlásek se souhláskami slabiky-finále:
- Použijte kemphreng diakritika a poslední souhláska, jako např ᤁ᤺ᤰ / kɔːk /.
- Nahraďte koncovou souhlásku za odpovídající plnou souhlásku a přidejte podtržítko jako diakritiku. To naznačuje, že souhláska je konečná (bez samohlásek) a že předchozí samohláska je prodloužena. Například: ᤁᤁ᤻ / kɔːk /. Stejná diakritika může být použita k označení konečných souhlásek v přejatých slovech, která nemají konečné tvary v Limbu, bez ohledu na délku samohlásky.
První metoda je široce používána v Sikkim; druhá metoda je obhajována určitými autory v Nepál.[2]
Glottalizace je označen značkou zvanou mukphreng (᤹). Například, ᤁ᤹ / kɔʔ /.
Ukázkový text z Limbu Wikipedia
ᤛᤧᤘᤠᤖᤥ᥅ ᤀᤠᤍᤠᤱᤒᤠ ᤜᤠᤍᤠᤱᤔᤠᤛᤣ ᤗᤠᤶᤎᤡᤱᤃᤥ ᤗᤠᤶᤎᤰ ᤕᤠᤰᤌᤢᤱᤐᤠᤴ ᤖᤧ ᤘᤡᤁᤡᤐᤡᤡᤍᤡᤕᤠ ᤀᤥ ||
ᤛᤧᤘᤠᤖ! ᤠᤍᤠᤏᤠᤒ ᤠ ᤠᤍᤠᤏᤠᤔ ᤠᤛᤧᤗᤠᤶᤎ ᤡᤏᤠᤃ ᤗᤠᤶᤎᤠᤁᤠ ᤕᤠᤰᤌᤢᤱ ᤐᤠᤏᤠ ᤖᤧ ᤘᤡᤁᤡᤐᤧᤍᤤ ᤀ।
ᤗᤡᤶᤒ ᤢ ᤓᤠᤛ ᤠᤁᤨ ᤘ ᤡᤁᤡᤐᤡᤍᤡᤕᤠᤔᤠ ᤛᤠᤒᤠᤡᤗᤠᤡ ᤛ ᤩᤃᤳ ᤇᤠ।
ᤗᤡ ᤶᤒᤢ ᤓᤠᤛ ᤠᤁᤨ ᤘ ᤡᤁᤡᤐᤣᤍᤡᤕᤠ ᤀᤜᤡᤗᤧ ᤡᤴᤁᤢᤒᤧᤛᤠᤏᤠ (ᤐᤠᤖ ᤣ ᤰᤙᤠ ᤴ ᤘᤡᤁᤡ) ᤀᤷᤌᤠᤳ ᤁᤨᤁᤨᤫᤔᤠ ᤇᤠ।
ᤕᤠᤛᤠᤗ ᤡᤠ ᤀᤃᤠᤍᤡ ᤒᤎᤦᤏᤠᤁᤠ ᤗᤠᤃᤡ ᤁᤠ ᤶᤋᤡᤔᤠ ᥈ ᤛᤠᤕᤠ ᤗᤧᤰ ᤗᤡᤶᤒᤢ ᤓᤠᤛᤠᤔᤠ ᤜᤢᤏᤠ ᤈᤠᤖᤥᤖᤣ ᤇᤠ। ᤋᤪᤠᤛᤠᤁᤠᤖᤠᤏᤠ ᤗᤡᤶᤒᤢ ᤓᤠᤛᤠᤔᤠ ᤗᤧᤂᤠᤜᤠᤖᤢ ᤗᤧᤰᤏᤠ ᤛᤢᤖᤢᤃᤠᤷᤏᤠ ᤛᤠᤒᤤ ᤗᤡᤶᤒᤢᤓᤠᤛᤡ ᤔᤡᤋᤠᤫᤜᤠᤖᤢᤔᤠ ᤜᤠᤷᤍᤡᤰ ᤠᤏᤢᤖᤨᤎ ᤇᤠ।
Zastaralé postavy
V raných verzích moderního písma byly použity tři další písmena:[2]
- ᤉ / ɟʱɔ /
- ᤊ / ɲɔ /
- ᤚ / ʂɔ /
Pro spojky nepálských souhlásek byly použity dvě ligatury:[3]
- ᤝ jña (pro Devanagari ज्ञ)
- ᤞ tra (pro Devanagari .्र)
Texty z devatenáctého století používaly malé Anusvara (ᤲ) známkovat nasalizace. Toto bylo použito zaměnitelně s ᤱ / ŋ /.
Znamení ᥀ byl použit pro vykřičnou částici ᤗᤥ (/hle/).[2]
Interpunkce
Hlavní interpunkční znaménko používané v Limbu je devanagari double Danda (॥).[2] Má svůj vlastní vykřičník (᥄) a otazník (᥅).
Číslice
Limbu má vlastní sadu číslic:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| ᥆ | ᥇ | ᥈ | ᥉ | ᥊ | ᥋ | ᥌ | ᥍ | ᥎ | ᥏ |
Unicode
Limbu skript byl přidán do Unicode Standard v dubnu 2003 s vydáním verze 4.0.
Blok Unicode pro Limbu je U + 1900 – U + 194F:
| Limbu[1][2] Oficiální tabulka kódů konsorcia Unicode (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U + 190x | ᤀ | ᤁ | ᤂ | ᤃ | ᤄ | ᤅ | ᤆ | ᤇ | ᤈ | ᤉ | ᤊ | ᤋ | ᤌ | ᤍ | ᤎ | ᤏ |
| U + 191x | ᤐ | ᤑ | ᤒ | ᤓ | ᤔ | ᤕ | ᤖ | ᤗ | ᤘ | ᤙ | ᤚ | ᤛ | ᤜ | ᤝ | ᤞ | |
| U + 192x | ᤠ | ᤡ | ᤢ | ᤣ | ᤤ | ᤥ | ᤦ | ᤧ | ᤨ | ᤩ | ᤪ | ᤫ | ||||
| U + 193x | ᤰ | ᤱ | ᤲ | ᤳ | ᤴ | ᤵ | ᤶ | ᤷ | ᤸ | ᤹ | ᤺ | ᤻ | ||||
| U + 194x | ᥀ | ᥄ | ᥅ | ᥆ | ᥇ | ᥈ | ᥉ | ᥊ | ᥋ | ᥌ | ᥍ | ᥎ | ᥏ | |||
| Poznámky | ||||||||||||||||
Reference
- ^ „ScriptSource: Limbu“. Citováno 20. července 2020.
- ^ A b C d E Michailovsky, Boyd; Everson, Michael (2002-02-05). „L2 / 02-055: Revidovaný návrh na kódování skriptu Limbu v UCS“ (PDF).
- ^ Pandey, Anshuman (2011-01-14). „L2 / 11-008: Návrh na zakódování písmen GYAN a TRA pro Limbu v UCS“ (PDF).