Distribuce chí-kvadrát - Chi-square distribution
Funkce hustoty pravděpodobnosti  | |||
Funkce kumulativní distribuce 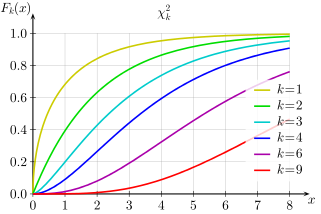 | |||
| Zápis | nebo | ||
|---|---|---|---|
| Parametry | (známé jako „stupně volnosti“) | ||
| Podpěra, podpora | -li , v opačném případě | ||
| CDF | |||
| Znamenat | |||
| Medián | |||
| Režim | |||
| Rozptyl | |||
| Šikmost | |||
| Př. špičatost | |||
| Entropie | |||
| MGF | |||
| CF | [1] | ||
| PGF | |||


















v teorie pravděpodobnosti a statistika, distribuce chí-kvadrát (taky chi-kvadrát nebo χ2-rozdělení) s k stupně svobody je distribuce součtu čtverců k nezávislý standardní normální náhodné proměnné. Distribuce chí-kvadrát je zvláštním případem gama distribuce a je jedním z nejpoužívanějších rozdělení pravděpodobnosti v inferenční statistiky, zejména v testování hypotéz a ve výstavbě intervaly spolehlivosti.[2][3][4][5] Tato distribuce se někdy nazývá centrální distribuce chí-kvadrát, speciální případ obecnější necentrální distribuce chí-kvadrát.
Distribuce chí-kvadrát se používá běžně testy chí-kvadrát pro dobrota fit pozorované distribuce na teoretickou, nezávislost dvou kritérií klasifikace kvalitativní údaje a odhad intervalu spolehlivosti pro populaci standardní odchylka normálního rozdělení od standardní směrodatné odchylky. Mnoho dalších statistických testů také používá tuto distribuci, jako například Friedmanova analýza rozptylu podle řad.
Definice
Li Z1, ..., Zk jsou nezávislý, standardní normální náhodné proměnné, pak součet jejich čtverců,

je distribuován podle chí-kvadrát distribuce s k stupně svobody. To se obvykle označuje jako

Distribuce chí-kvadrát má jeden parametr: kladné celé číslo k který určuje počet stupně svobody (počet Zi s).
Úvod
Distribuce chí-kvadrát se používá především při testování hypotéz a v menší míře pro intervaly spolehlivosti pro rozptyl populace, když je základní distribuce normální. Na rozdíl od více známých distribucí, jako je normální distribuce a exponenciální rozdělení „distribuce chí-kvadrát se při přímém modelování přírodních jevů tak často nepoužívá. Vzniká mimo jiné v následujících testech hypotéz:
- Test chí-kvadrát nezávislosti v kontingenční tabulky
- Test chí-kvadrát dobré shody pozorovaných dat s hypotetickým rozdělením
- Test poměru pravděpodobnosti pro vnořené modely
- Log-rank test v analýze přežití
- Cochran – Mantel – Haenszelův test pro stratifikované pohotovostní tabulky
Je to také součást definice t-distribuce a F-distribuce použitý v t-testech, analýze rozptylu a regresní analýze.
Primárním důvodem, proč se při testování hypotéz ve velké míře používá rozdělení chí-kvadrát, je jeho vztah k normálnímu rozdělení. Mnoho testů hypotéz používá statistiku testů, například t-statistika v t-testu. U těchto testů hypotéz, jak se zvyšuje velikost vzorku, n, se zvyšuje Distribuce vzorků zkušební statistiky se blíží normálnímu rozdělení (teorém centrálního limitu ). Protože statistika testu (například t) je asymptoticky normálně rozdělena, za předpokladu, že velikost vzorku je dostatečně velká, může být distribuce použitá pro testování hypotéz aproximována normálním rozdělením. Testování hypotéz pomocí normálního rozdělení je dobře srozumitelné a relativně snadné. Nejjednodušší rozdělení chí-kvadrát je čtverec standardního normálního rozdělení. Takže kdekoli lze pro test hypotézy použít normální rozdělení, lze použít rozdělení chí-kvadrát.
Předpokládejme to je náhodná proměnná vzorkovaná ze standardního normálního rozdělení, kde se střední hodnota rovná a rozptyl se rovná : . Nyní zvažte náhodnou proměnnou . Rozdělení náhodné proměnné je příklad rozdělení chí-kvadrát: Dolní index 1 naznačuje, že toto konkrétní rozdělení chí-kvadrát je konstruováno pouze z 1 standardního normálního rozdělení. O rozdělení chí-kvadrát vytvořeném druhou mocninou normálního normálního rozdělení se říká, že má 1 stupeň volnosti. Jak se tedy zvyšuje velikost vzorku pro test hypotézy, distribuce statistik testu se blíží normálnímu rozdělení. Stejně jako extrémní hodnoty normálního rozdělení mají nízkou pravděpodobnost (a dávají malé hodnoty p), extrémní hodnoty rozdělení chí-kvadrát mají nízkou pravděpodobnost.







Dalším důvodem, proč je distribuce chí-kvadrát široce používána, je to, že se ukazuje jako velká distribuce vzorku generalizované testy poměru pravděpodobnosti (LRT).[6] LRT mají několik žádoucích vlastností; zejména jednoduché LRT obvykle poskytují nejvyšší sílu k odmítnutí nulové hypotézy (Neymanovo – Pearsonovo lemma ) a to také vede k optimálním vlastnostem generalizovaných LRT. Normální aproximace chí-kvadrát jsou však platné pouze asymptoticky. Z tohoto důvodu je pro malou velikost vzorku výhodnější použít t rozdělení než normální aproximaci nebo chí-kvadrátovou aproximaci. Podobně v analýzách kontingenčních tabulek bude chí-kvadrátová aproximace špatná pro malou velikost vzorku a je vhodnější použít Fisherův přesný test. Ramsey ukazuje, že přesně binomický test je vždy silnější než normální aproximace.[7]
Lancaster ukazuje spojení mezi binomickým, normálním a chí-kvadrátovým rozdělením následujícím způsobem.[8] De Moivre a Laplace zjistili, že binomické rozdělení lze aproximovat normálním rozdělením. Konkrétně ukázaly asymptotickou normalitu náhodné proměnné

kde je pozorovaný počet úspěchů v pokusy, kde je pravděpodobnost úspěchu , a .




Srovnání obou stran rovnice dává

Použitím , , a , tato rovnice se zjednodušuje na



Výraz vpravo má tvar Karl Pearson by zobecnit do formy:

kde
- = Pearsonova kumulativní statistika testu, která se asymptoticky blíží a rozdělení.
- = počet pozorování typu .
- = očekávaná (teoretická) frekvence typu , tvrdil nulovou hypotézou, že zlomek typu v populaci je
- = počet buněk v tabulce.






V případě binomického výsledku (převrácení mince) lze binomické rozdělení aproximovat normálním rozdělením (pro dostatečně velké ). Protože druhou mocninou standardního normálního rozdělení je rozdělení chí-kvadrát s jedním stupněm volnosti, lze pravděpodobnost výsledku, jako je 1 hlava v 10 pokusech, aproximovat buď přímým použitím normální distribuce, nebo normalizovaný čtvercový rozdíl mezi pozorovanou a očekávanou hodnotou. Mnoho problémů však zahrnuje více než dva možné výsledky binomia a místo toho vyžaduje 3 nebo více kategorií, což vede k multinomiální distribuci. Stejně jako de Moivre a Laplace hledali a našli normální aproximaci k binomii, Pearson hledal a našel zdegenerovanou vícerozměrnou normální aproximaci k multinomickému rozdělení (čísla v každé kategorii se sčítají s celkovou velikostí vzorku, která se považuje za pevnou) . Pearson ukázal, že rozdělení chí-kvadrát vzniklo z takového vícerozměrného normálního přiblížení k multinomickému rozdělení, přičemž pečlivě zohlednil statistickou závislost (negativní korelace) mezi počty pozorování v různých kategoriích. [8]
Funkce hustoty pravděpodobnosti
The funkce hustoty pravděpodobnosti (pdf) distribuce chí-kvadrát je

kde označuje funkce gama, který má hodnoty uzavřeného formuláře pro celé číslo .

Pro odvození souboru PDF v případě jedné, dvou a stupně volnosti, viz Důkazy týkající se distribuce chí-kvadrát.
Funkce kumulativní distribuce

Své kumulativní distribuční funkce je:

kde je nižší neúplná funkce gama a je regularizovaná funkce gama.


Ve zvláštním případě = 2 tato funkce má jednoduchý tvar:[Citace je zapotřebí ]

a celočíselné opakování funkce gama usnadňuje výpočet pro jiné malé sudé .
Tabulky kumulativní distribuční funkce chí-kvadrát jsou široce dostupné a tato funkce je zahrnuta v mnoha tabulky a všechno statistické balíčky.
Pronájem , Černoffovy hranice na dolním a horním konci CDF.[9] Pro případy, kdy (které zahrnují všechny případy, kdy je tento CDF menší než polovina):



Ocas vázán pro případy, kdy podobně je


Pro další přiblížení pro CDF po vzoru krychle Gaussian, viz pod Noncentral chi-square distribucí.
Vlastnosti
Součet čtverců normálů i.i.d minus jejich průměr
Li Z1, ..., Zk jsou nezávislý, standardní normální náhodné proměnné

kde

Aditivita
Z definice rozdělení chí-kvadrát vyplývá, že součet nezávislých proměnných chí-kvadrát je také distribuován na chí-kvadrát. Konkrétně pokud jsou nezávislé chí-kvadrát proměnné s , stupně volnosti je chi-square distribuován s stupně svobody.





Průměrný vzorek
Průměr vzorku z i.i.d. chí-kvadrát proměnné stupně je distribuován podle gama rozdělení s tvarem a měřítko parametry:



Asymptoticky, vzhledem k tomu, že pro parametr měřítka jde do nekonečna, rozdělení gama konverguje k normálnímu rozdělení s očekáváním a rozptyl , vzorkový průměr konverguje k:



Všimněte si, že bychom získali stejný výsledek vyvoláním místo teorém centrálního limitu s tím, že pro každou chí-kvadrát proměnnou stupně očekávání je a jeho rozptyl (a tudíž rozptyl průměru vzorku bytost ).



Entropie
The diferenciální entropie darováno
![{ displaystyle h = int _ {0} ^ { infty} f (x; , k) ln f (x; , k) , dx = { frac {k} {2}} + ln left [2 , Gamma left ({ frac {k} {2}} right) right] + left (1 - { frac {k} {2}} right) , psi ! vlevo [{ frac {k} {2}} vpravo],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d6e76f96bba0f22fdb613c4dc8c6730942ee3a79)
kde ψ(X) je Funkce digamma.
Distribuce chí-kvadrát je maximální rozdělení pravděpodobnosti entropie pro náhodnou variaci pro který a jsou opraveny. Vzhledem k tomu, že chí-kvadrát je v rodině gama distribucí, lze to odvodit nahrazením příslušných hodnot v Očekávání log momentu gama. Pro odvození od více základních principů viz odvození v momentotvorná funkce dostatečné statistiky.



Noncentral momenty
Momenty o nule distribuce chí-kvadrát s stupně volnosti jsou dány[10][11]

Kumulanty
The kumulanty jsou snadno získány (formálním) rozšířením výkonové řady logaritmu charakteristické funkce:

Asymptotické vlastnosti

Podle teorém centrálního limitu, protože rozdělení chí-kvadrát je součet nezávislé náhodné proměnné s konečným průměrem a rozptylem, konverguje k normálnímu rozdělení pro velké . Pro mnoho praktických účelů, pro distribuce je dostatečně blízká a normální distribuce rozdíl bude ignorován.[12] Konkrétně pokud , pak jako inklinuje k nekonečnu, distribuce inklinuje na standardní normální rozdělení. Konvergence je však pomalá šikmost je a nadměrná špičatost je .





Distribuce vzorkování konverguje k normálnosti mnohem rychleji než distribuce vzorkování ,[13] protože logaritmus odstraňuje velkou část asymetrie.[14] Další funkce distribuce chí-kvadrát konvergují rychleji k normálnímu rozdělení. Některé příklady jsou:

- Li pak je přibližně normálně distribuován se střední hodnotou a jednotková odchylka (1922, podle R. A. Fisher, viz (18.23), s. 426 Johnson.[4]
- Li pak je přibližně normálně distribuován se střední hodnotou a rozptyl [15] Toto se nazývá Wilsonova-Hilfertyova transformace, viz (18.24), str. 426 Johnson.[4]
- Tato normalizační transformace vede přímo k běžně používané střední aproximaci zpětnou transformací ze střední hodnoty normálního rozdělení, což je také medián.


![{ displaystyle { sqrt [{3}] {X / k}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8bcdb470ed5d9bcbb3a64104d190a9ff620f4048)



Související distribuce
Tato sekce potřebuje další citace pro ověření. (Září 2011) (Zjistěte, jak a kdy odstranit tuto zprávu šablony) |
- Tak jako , (normální distribuce )
- (necentrální distribuce chí-kvadrát s parametrem necentrality )
- Li pak má distribuci chí-kvadrát







- Jako zvláštní případ, pokud pak má distribuci chí-kvadrát



- (Na druhou norma z k standardní normálně distribuované proměnné je distribuce chí-kvadrát s k stupně svobody )
- Li a , pak . (gama distribuce )
- Li pak (distribuce chi )
- Li , pak je exponenciální rozdělení. (Vidět gama distribuce více.)
- Li , pak je Erlang distribuce.
- Li , pak
- Li (Rayleighova distribuce ) pak
- Li (Maxwellova distribuce ) pak
- Li pak (Distribuce inverzně-chi-kvadrát )
- Distribuce chí-kvadrát je speciální případ typu III Pearsonova distribuce
- Li a jsou pak nezávislé (beta distribuce )
- Li (rovnoměrné rozdělení ) pak
- je transformace Laplaceova distribuce
- Li pak
- Li následuje zobecněné normální rozdělení (verze 1) s parametry pak [16]
- chi-square distribuce je transformace Paretova distribuce
- Studentova t-distribuce je transformace distribuce chí-kvadrát
- Studentova t-distribuce lze získat z distribuce chí-kvadrát a normální distribuce
- Noncentrální beta distribuce lze získat jako transformaci chí-kvadrát distribuce a Noncentrální distribuce chí-kvadrát
- Noncentrální t-distribuce lze získat z normálního rozdělení a rozdělení chí-kvadrát





























Chí-kvadrát proměnná s stupně volnosti jsou definovány jako součet čtverců nezávislý standardní normální náhodné proměnné.
Li je -rozměrný Gaussův náhodný vektor se středním vektorem a pořadí kovarianční matice , pak je chi-square distribuován s stupně svobody.




Součet čtverců statisticky nezávislé unit-variance Gaussovské proměnné, které ano ne mít střední nulové výnosy zobecnění distribuce chí-kvadrátu zvané necentrální distribuce chí-kvadrát.
Li je vektorem i.i.d. standardní normální náhodné proměnné a je symetrický, idempotentní matice s hodnost , pak kvadratická forma je chi-square distribuován s stupně svobody.




Li je pozitivně semidefinitní kovarianční matice s přísně pozitivními diagonálními položkami, pak pro a náhodný -vektor nezávislý na takhle a to platí







Distribuce chí-kvadrát také přirozeně souvisí s jinými distribucemi vyplývajícími z Gaussian. Zejména,
- je F-distribuováno, -li , kde a jsou statisticky nezávislé.
- Li a jsou tedy statisticky nezávislé . Li a nejsou tedy nezávislí není distribuován chí-kvadrát.








Zobecnění
Distribuce chí-kvadrát se získá jako součet čtverců z k nezávislé gaussovské náhodné proměnné s nulovou střední hodnotou a jednotkovou variací. Zevšeobecnění tohoto rozdělení lze získat sečtením čtverců jiných typů Gaussových náhodných proměnných. Několik takových distribucí je popsáno níže.
Lineární kombinace
Li jsou chi kvadrát náhodné proměnné a , pak uzavřený výraz pro distribuci není známo. Lze jej však efektivně aproximovat pomocí vlastnost charakteristických funkcí chí-kvadrát náhodných proměnných.[17]



Distribuce chí-kvadrát
Noncentrální distribuce chí-kvadrát
Noncentrální rozdělení chí-kvadrát se získá ze součtu čtverců nezávislých Gaussových náhodných proměnných, které mají jednotkovou rozptyl a nenulové prostředek.
Zobecněná distribuce chí-kvadrát
Zobecněné rozdělení chí-kvadrát se získá z kvadratické formy z'Az kde z je nulový průměr Gaussova vektoru s libovolnou kovarianční maticí a A je libovolná matice.
Distribuce chí-kvadrát je zvláštní případ gama distribuce, v tomto pomocí parametrizace rychlosti distribuce gama (nebo pomocí parametrizace měřítka rozdělení gama) kde k je celé číslo.


Protože exponenciální rozdělení je také speciální případ distribuce gama, máme také to, pokud , pak je exponenciální rozdělení.


The Erlang distribuce je také speciální případ distribuce gama, a tedy máme také to, pokud se sudým , pak je Erlang distribuován s parametrem tvaru a měřítko parametru .




Výskyt a aplikace
Distribuce chí-kvadrát má četné aplikace inferenciální statistika, například v testy chí-kvadrát a při odhadování odchylky. Zadává problém odhadu průměru normálně distribuované populace a problém odhadu sklonu a regrese linka prostřednictvím své role v Studentova t-distribuce. Vstupuje do všeho analýza rozptylu problémy prostřednictvím své role v EU F-distribuce, což je rozdělení poměru dvou nezávislých chí-kvadrátů náhodné proměnné, každý děleno příslušnými stupni volnosti.
Následuje několik nejběžnějších situací, ve kterých distribuce chí-kvadrátu vychází z Gaussova distribuovaného vzorku.
- -li jsou i.i.d. náhodné proměnné, pak kde .
- Pole níže ukazuje některé statistika na základě nezávislé náhodné proměnné, které mají rozdělení pravděpodobnosti související s distribucí chí-kvadrát:





| název | Statistický |
|---|---|
| distribuce chí-kvadrát | |
| necentrální distribuce chí-kvadrát | |
| distribuce chi | |
| necentrální distribuce chi |




S distribucí chí-kvadrát se také často setkáváme magnetická rezonance.[18]
Výpočtové metody
Tabulka χ2 hodnoty vs. p-hodnoty
The p-hodnota je pravděpodobnost dodržení statistiky testu alespoň jako extrém v distribuci chí-kvadrát. Proto, protože kumulativní distribuční funkce (CDF) pro příslušné stupně volnosti (df) udává pravděpodobnost získání hodnoty méně extrémní než tento bod, odečtením hodnoty CDF od 1 získá p-hodnota. Nízká phodnota označuje pod zvolenou úrovní významnosti statistická významnost, tj. dostatečné důkazy pro odmítnutí nulové hypotézy. Hladina významnosti 0,05 se často používá jako mezní hodnota mezi významnými a nevýznamnými výsledky.
Níže uvedená tabulka uvádí řadu p-hodnoty odpovídající pro prvních 10 stupňů volnosti.
| Stupně svobody (df) | hodnota[19] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.004 | 0.02 | 0.06 | 0.15 | 0.46 | 1.07 | 1.64 | 2.71 | 3.84 | 6.63 | 10.83 |
| 2 | 0.10 | 0.21 | 0.45 | 0.71 | 1.39 | 2.41 | 3.22 | 4.61 | 5.99 | 9.21 | 13.82 |
| 3 | 0.35 | 0.58 | 1.01 | 1.42 | 2.37 | 3.66 | 4.64 | 6.25 | 7.81 | 11.34 | 16.27 |
| 4 | 0.71 | 1.06 | 1.65 | 2.20 | 3.36 | 4.88 | 5.99 | 7.78 | 9.49 | 13.28 | 18.47 |
| 5 | 1.14 | 1.61 | 2.34 | 3.00 | 4.35 | 6.06 | 7.29 | 9.24 | 11.07 | 15.09 | 20.52 |
| 6 | 1.63 | 2.20 | 3.07 | 3.83 | 5.35 | 7.23 | 8.56 | 10.64 | 12.59 | 16.81 | 22.46 |
| 7 | 2.17 | 2.83 | 3.82 | 4.67 | 6.35 | 8.38 | 9.80 | 12.02 | 14.07 | 18.48 | 24.32 |
| 8 | 2.73 | 3.49 | 4.59 | 5.53 | 7.34 | 9.52 | 11.03 | 13.36 | 15.51 | 20.09 | 26.12 |
| 9 | 3.32 | 4.17 | 5.38 | 6.39 | 8.34 | 10.66 | 12.24 | 14.68 | 16.92 | 21.67 | 27.88 |
| 10 | 3.94 | 4.87 | 6.18 | 7.27 | 9.34 | 11.78 | 13.44 | 15.99 | 18.31 | 23.21 | 29.59 |
| Hodnota P (pravděpodobnost) | 0.95 | 0.90 | 0.80 | 0.70 | 0.50 | 0.30 | 0.20 | 0.10 | 0.05 | 0.01 | 0.001 |
Tyto hodnoty lze vypočítat na základě vyhodnocení kvantilová funkce (také známý jako „inverzní CDF“ nebo „ICDF“) distribuce chí-kvadrát;[20] E. např χ2 ICDF pro p = 0.05 a df = 7 výnosy 14.06714 ≈ 14.07 jako v tabulce výše.
Dějiny
Toto rozdělení poprvé popsal německý statistik Friedrich Robert Helmert v novinách 1875–6,[21][22] kde vypočítal rozdělení vzorkování rozptylu vzorků normální populace. V němčině to tedy bylo tradičně známé jako Helmert'sche („Helmertian“) nebo „Helmertova distribuce“.
Distribuci nezávisle znovu objevil anglický matematik Karl Pearson v kontextu dobrota fit, pro které vyvinul svůj Pearsonův test chí-kvadrát, publikované v roce 1900, s vypočítanou tabulkou hodnot publikovanou v (Elderton 1902 ), shromážděné v (Pearson 1914, s. xxxi – xxxiii, 26–28, tabulka XII)Název „chí-square“ se nakonec odvozuje od Pearsonovy zkratky pro exponenta v a vícerozměrné normální rozdělení s řeckým dopisem Chi, psaní − ½χ2 protože to, co by se v moderní notaci objevilo jako −½XTΣ−1X (Σ být kovarianční matice ).[23] Myšlenka rodiny „distribucí chí-kvadrát“ však není způsobena Pearsonem, ale vznikla jako další vývoj díky Fisherovi ve 20. letech 20. století.[21]
Viz také
- Distribuce Chi
- Cochranova věta
- F-rozdělení
- Fisherova metoda pro kombinování nezávislý testy významnosti
- Distribuce gama
- Zobecněná distribuce chí-kvadrát
- Hotelling's T- čtvercová distribuce
- Noncentrální distribuce chí-kvadrát
- Pearsonův test chí-kvadrát
- Snížená statistika chí-kvadrát
- Studentské t-rozdělení
- Wilksova distribuce lambda
- Wishart distribuce
Reference
- ^ M.A. Sanders. "Charakteristická funkce centrálního rozdělení chí-kvadrátu" (PDF). Archivovány od originál (PDF) dne 15.7.2011. Citováno 2009-03-06.
- ^ Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [červen 1964]. „Kapitola 26“. Příručka matematických funkcí se vzorci, grafy a matematickými tabulkami. Řada aplikované matematiky. 55 (Devátý dotisk s dalšími opravami desátého originálu s opravami (prosinec 1972); první vydání.). Washington DC.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. str. 940. ISBN 978-0-486-61272-0. LCCN 64-60036. PAN 0167642. LCCN 65-12253.
- ^ NIST (2006). Příručka technické statistiky - distribuce chí-kvadrát
- ^ A b C Johnson, N.L .; Kotz, S .; Balakrishnan, N. (1994). "Chi-Square Distribuce včetně Chi a Rayleigh". Kontinuální jednorozměrné distribuce. 1 (Druhé vydání.). John Wiley and Sons. 415–493. ISBN 978-0-471-58495-7.
- ^ Mood, Alexander; Graybill, Franklin A .; Boes, Duane C. (1974). Úvod do teorie statistiky (Třetí vydání.). McGraw-Hill. str. 241–246. ISBN 978-0-07-042864-5.
- ^ Westfall, Peter H. (2013). Porozumění pokročilým statistickým metodám. Boca Raton, FL: CRC Press. ISBN 978-1-4665-1210-8.
- ^ Ramsey, PH (1988). "Hodnocení normální aproximace na binomický test". Journal of Educational Statistics. 13 (2): 173–82. doi:10.2307/1164752. JSTOR 1164752.
- ^ A b Lancaster, H.O. (1969), Distribuce chí-kvadrátWiley
- ^ Dasgupta, Sanjoy D. A .; Gupta, Anupam K. (leden 2003). „Základní důkaz věty o Johnsonovi a Lindenstraussovi“ (PDF). Náhodné struktury a algoritmy. 22 (1): 60–65. doi:10.1002 / rsa.10073. Citováno 2012-05-01.
- ^ Distribuce chí-kvadrát, z MathWorld, vyvoláno 11. února 2009
- ^ M. K. Simon, Pravděpodobnostní rozdělení zahrnující Gaussovské náhodné proměnné, New York: Springer, 2002, ekv. (2,35), ISBN 978-0-387-34657-1
- ^ Box, Hunter and Hunter (1978). Statistiky pro experimentátory. Wiley. str.118. ISBN 978-0471093152.
- ^ Bartlett, M. S .; Kendall, D. G. (1946). „Statistická analýza variační-heterogenity a logaritmická transformace“. Dodatek k věstníku Královské statistické společnosti. 8 (1): 128–138. doi:10.2307/2983618. JSTOR 2983618.
- ^ A b Pillai, Natesh S. (2016). „Nečekané setkání s Cauchym a Lévym“. Annals of Statistics. 44 (5): 2089–2097. arXiv:1505.01957. doi:10.1214 / 15-aos1407.
- ^ Wilson, E. B .; Hilferty, M. M. (1931). „Distribuce chí-kvadrát“. Proc. Natl. Acad. Sci. USA. 17 (12): 684–688. Bibcode:1931PNAS ... 17..684W. doi:10.1073 / pnas.17.12.684. PMC 1076144. PMID 16577411.
- ^ Bäckström, T .; Fischer, J. (leden 2018). „Rychlá randomizace pro distribuované kódování řeči a zvuku s nízkou bitrate“. Transakce IEEE / ACM na zpracování zvuku, řeči a jazyka. 26 (1): 19–30. doi:10.1109 / TASLP.2017.2757601.
- ^ Bausch, J. (2013). "O efektivním výpočtu lineární kombinace náhodných proměnných chí-kvadrát s aplikací pro počítání strunové vakua". J. Phys. A: Math. Teor. 46 (50): 505202. arXiv:1208.2691. Bibcode:2013JPhA ... 46X5202B. doi:10.1088/1751-8113/46/50/505202.
- ^ den Dekker A. J., Sijbers J., (2014) „Distribuce dat v obrazech magnetické rezonance: recenze“, Physica Medica, [1]
- ^ Chi-kvadrát test Tabulka B.2. Dr. Jacqueline S. McLaughlin na Pensylvánské státní univerzitě. Dále citují: R. A. Fisher a F. Yates, Statistické tabulky pro biologický zemědělský a lékařský výzkum, 6. vydání, Tabulka IV. Byly opraveny dvě hodnoty, 7,82 se 7,81 a 4,60 se 4,61
- ^ Výukový program R: Distribuce chí-kvadrát
- ^ A b Hald 1998, str. 633–692, 27. Vzorkování distribucí za normálnosti.
- ^ F. R. Helmert, "Ueber die Wahrscheinlichkeit der Potenzsummen der Beobachtungsfehler und über einige damit im Zusammenhange stehende Fragen ", Zeitschrift für Mathematik und Physik 21, 1876, s. 102–219
- ^ R. L. Plackett, Karl Pearson a test chí-kvadrát, International Statistical Review, 1983, 61f. Viz také Jeff Miller, Nejstarší známá použití některých slov matematiky.
Další čtení
- Hald, Andersi (1998). Historie matematické statistiky od roku 1750 do roku 1930. New York: Wiley. ISBN 978-0-471-17912-2.
- Elderton, William Palin (1902). „Tabulky pro testování správnosti přizpůsobení teorie pozorování“. Biometrika. 1 (2): 155–163. doi:10.1093 / biomet / 1.2.155.
- "Chi-kvadrát distribuce", Encyclopedia of Mathematics, Stiskněte EMS, 2001 [1994]
externí odkazy
- Nejčasnější použití některých slov matematiky: vstup do Chi na druhou má krátkou historii
- Poznámky k kurzu na téma Chi-Squared Goodness of Fit Testing ze třídy statistiky Yale University 101.
- Mathematica demonstrace ukazující distribuci vzorkování chí-kvadrát různých statistik, např. G. ΣX², pro normální populaci
- Jednoduchý algoritmus pro aproximaci CDF a inverzní CDF pro distribuci chí-kvadrát pomocí kapesní kalkulačky
- Hodnoty distribuce chí-kvadrát