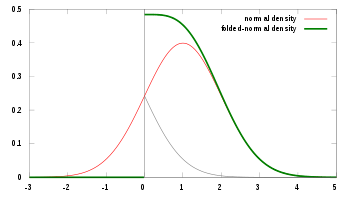
The složené normální rozdělení je rozdělení pravděpodobnosti související s normální distribuce. Vzhledem k normálně distribuované náhodné proměnné X s znamenatμ a rozptylσ2, náhodná proměnnáY = |X| má složené normální rozdělení. Takový případ lze narazit, pokud je zaznamenána pouze velikost nějaké proměnné, ale ne její znaménko. Distribuce se nazývá „složená“, protože hmotnost pravděpodobnosti nalevo od X = 0 je přeložen převzetím absolutní hodnota. Ve fyzice vedení tepla, složené normální rozdělení je základním řešením rovnice tepla na polovičním prostoru; odpovídá perfektnímu izolátoru na a nadrovina přes původ.
Jak průměr (μ) a rozptyl (σ2) z X v původním normálním rozdělení lze interpretovat jako parametry umístění a měřítka Y ve složené distribuci.
Vlastnosti
Režim
Režim distribuce je hodnota pro které je hustota maximalizována. Abychom našli tuto hodnotu, vezmeme první derivaci hustoty vzhledem k a nastavte ji na nulu. Bohužel neexistuje žádná uzavřená forma. Můžeme však derivaci napsat lépe a skončit s nelineární rovnicí
.
Tsagris a kol. (2014) viděli z numerického šetření, že když , maximum je splněno, když , a kdy se stává větší než , maximální přístupy . To je samozřejmě něco, co lze očekávat, protože v tomto případě složená normální konverguje k normálnímu rozdělení. Aby se předešlo problémům se zápornými odchylkami, doporučuje se umocnění parametru. Alternativně můžete přidat omezení, například pokud optimalizátor jde o zápornou odchylku, hodnota log-likelihood je NA nebo něco velmi malého.
Charakteristická funkce a další související funkce
K dispozici je bivariantní verze vyvinutá Psarakisem a Panaretosem (2001), stejně jako multivariační verze vyvinutá Chakraborty a Moutushi (2013).
The Rozdělení rýže je vícerozměrné zobecnění složeného normálního rozdělení.
Statistická inference
Odhad parametrů
Existuje několik způsobů odhadu parametrů složeného normálu. Všechny jsou v zásadě procedurou odhadu maximální pravděpodobnosti, ale v některých případech se provádí numerická maximalizace, zatímco v jiných případech se hledá kořen rovnice. Pravděpodobnost logaritmu skládaného normálu, když je vzorek velikosti je k dispozici lze zapsat následujícím způsobem
v R (programovací jazyk), pomocí balíčku Rfast jeden může získat MLE opravdu rychle (příkaz foldnorm.mle). Případně příkaz optim nebo nlm se vejde do této distribuce. Maximalizace je snadná, protože dva parametry ( a ) jsou zapojeny. Všimněte si, že pozitivní i negativní hodnoty pro jsou přijatelné, protože patří do reálné řady čísel, proto není znaménko důležité, protože rozdělení je vzhledem k němu symetrické. Další kód je napsán v R.
složený<-funkce(y){## y je vektor s kladnými datyn<-délka(y)## velikost vzorkusy2<-součet(y ^ 2)sam<-funkce(odst,n,sy2){mě<-odstavec [1];se<-exp(odstavec [2])F<--n/2*log(2/pi/se)+n*já ^ 2/2/se+sy2/2/se-součet(log(hovno(mě*y/se)))F}mod<-optim(C(znamenat(y),sd(y)),n=n,sy2=sy2,sam,řízení=seznam(max=2000))mod<-optim(mod$odst,sam,n=n,sy2=sy2,řízení=seznam(max=20000))výsledek<-C(-mod$hodnota,mod$par [1],exp(mod$par [2]))jména(výsledek)<-C("log-likelihood","mu","sigma na druhou")výsledek}
Dílčí deriváty logaritmické pravděpodobnosti se zapisují jako
.
Vyrovnáním první parciální derivace logaritmické pravděpodobnosti na nulu získáme pěkný vztah
.
Všimněte si, že výše uvedená rovnice má tři řešení, jedno na nule a dvě další s opačným znaménkem. Nahrazením výše uvedené rovnice částečnou derivací logaritmické pravděpodobnosti w.r.t. a rovnicí na nulu dostaneme následující výraz pro rozptyl
,
což je stejný vzorec jako v normální distribuce. Hlavní rozdíl je v tom a nejsou statisticky nezávislé. Výše uvedené vztahy lze použít k získání maximálních odhadů pravděpodobnosti efektivním rekurzivním způsobem. Začínáme s počáteční hodnotou pro a najděte pozitivní kořen () poslední rovnice. Poté získáme aktualizovanou hodnotu . Postup se opakuje, dokud není změna hodnoty log-likelihood zanedbatelná. Další jednodušší a efektivnější způsob je provést vyhledávací algoritmus. Napíšeme poslední rovnici elegantnějším způsobem
.
Je zřejmé, že optimalizace logaritmické pravděpodobnosti s ohledem na dva parametry se změnila v kořenové hledání funkce. To je samozřejmě totožné s předchozím kořenovým vyhledáváním. Tsagris a kol. (2014) zjistili, že pro tuto rovnici existují tři kořeny , tj. existují tři možné hodnoty které splňují tuto rovnici. The a , což jsou odhady maximální věrohodnosti a 0, což odpovídá minimální věrohodnosti protokolu.
Johnson NL (1962). "Skládané normální rozdělení: přesnost odhadu maximální pravděpodobností". Technometrics. 4 (2): 249–256. doi:10.2307/1266622. JSTOR1266622.
Nelson LS (1980). "Skládané normální rozdělení". J Qual Technol. 12 (4): 236–238.
Elandt RC (1961). "Skládané normální rozdělení: dvě metody odhadu parametrů z momentů". Technometrics. 3 (4): 551–562. doi:10.2307/1266561. JSTOR1266561.
Lin PC (2005). "Aplikace zobecněného rozložení složeného normálu na opatření způsobilosti procesu". Int J Adv Manuf Technol. 26 (7–8): 825–830. doi:10.1007 / s00170-003-2043-x.
Psarakis, S .; Panaretos, J. (1990). "Skládané t rozdělení". Komunikace ve statistice - teorie a metody. 19 (7): 2717–2734.
Psarakis, S .; Panaretos, J. (2001). "Na některých dvojrozměrných rozšířeních složeného normálu a složeného t rozdělení". Journal of Applied Statistical Science. 10 (2): 119–136.
Chakraborty, A. K .; Moutushi, C. (2013). "Na vícerozměrném složeném normálním rozdělení". Sankhya B.. 75 (1): 1–15.
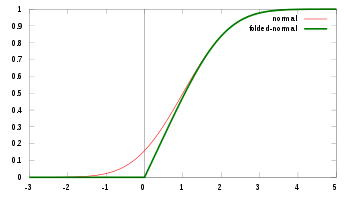

![{frac {1} {2}} vlevo [{mbox {erf}} vlevo ({frac {x + mu} {sigma {sqrt {2}}}} vpravo) + {mbox {erf}} vlevo ({frac { x-mu} {sigma {sqrt {2}}}} hned) hned]](https://wikimedia.org/api/rest_v1/media/math/render/svg/ad88ca4e426758e5b8472945b7562acc5db7d03b)




![{displaystyle F_ {Y} (x; mu, sigma ^ {2}) = {frac {1} {2}} vlevo [{mbox {erf}} vlevo ({frac {x + mu} {sqrt {2sigma ^ { 2}}}} ight) + {mbox {erf}} vlevo ({frac {x-mu} {sqrt {2sigma ^ {2}}}} ight) ight]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bbf74023157cbecf10c9340dd9a0bfe09e3f4f1b)

![{displaystyle mu _ {Y} = {sqrt {frac {2} {pi}}} sigma e ^ {- {frac {mu ^ {2}} {2sigma ^ {2}}}} + mu left [1-2Phi left (- {frac {mu} {sigma}} ight) ight]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fd5bfcd3dc54605d03817a06f63bebc3a87ca556)

![{displaystyle Phi (x); =; {frac {1} {2}} vlevo [1 + operatorname {erf} vlevo ({frac {x} {sqrt {2}}} vpravo) přesně].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1d4a69ed96ae507f5766a6d5b8a23da4eeec1109)



![{displaystyle xleft [e ^ {- {frac {1} {2}} {frac {left (x-mu ight) ^ {2}} {sigma ^ {2}}}} + e ^ {- {frac {1 } {2}} {frac {left (x + mu ight) ^ {2}} {sigma ^ {2}}}} ight] -mu left [e ^ {- {frac {1} {2}} {frac {left (x-mu ight) ^ {2}} {sigma ^ {2}}}} - e ^ {- {frac {1} {2}} {frac {left (x + mu ight) ^ {2} } {sigma ^ {2}}}} ight] = 0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/69f19ceec33ed5147ed745256c7244c5cb468364)









![{displaystyle K_ {x} left (tight) = log {M_ {x} left (tight)} = left ({frac {sigma ^ {2} t ^ {2}} {2}} + mu tight) + log { leftlbrace 1-Phi left (- {frac {mu} {sigma}} - sigma tight) + e ^ {{frac {sigma ^ {2} t ^ {2}} {2}} - mu t} left [1- Phi left ({frac {mu} {sigma}} - těsné sigma) ight] ightbrace}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/18260983046f5c9d546d518542872acee9d90678)
![{displaystyle Eleft (e ^ {- tx} ight) = e ^ {{frac {sigma ^ {2} t ^ {2}} {2}} - mu t} vlevo [1-Phi vlevo (- {frac {mu } {sigma}} + sigma tight) ight] + e ^ {{frac {sigma ^ {2} t ^ {2}} {2}} + mu t} vlevo [1-Phi vlevo ({frac {mu} { sigma}} + sigma tight) ight]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bcf88b418505cfad95c727604e731d1801bfa53d)
![{displaystyle {hat {f}} left (tight) = phi _ {x} left (-2pi tight) = e ^ {{frac {-4pi ^ {2} sigma ^ {2} t ^ {2}} {2 }} - i2pi mu t} vlevo [1-Phi vlevo (- {frac {mu} {sigma}} - i2pi sigma těsně) ight] + e ^ {- {frac {4pi ^ {2} sigma ^ {2} t ^ {2}} {2}} + i2pi mu t} left [1-Phi left ({frac {mu} {sigma}} - i2pi sigma tight) ight]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ea9915664db6c8d360efec8ee9b94e9d45e8408c)


![{displaystyle l = - {frac {n} {2}} log {2pi sigma ^ {2}} + součet _ {i = 1} ^ {n} log {left [e ^ {- {frac {left (x_ { i} -mu ight) ^ {2}} {2sigma ^ {2}}}} + e ^ {- {frac {left (x_ {i} + mu ight) ^ {2}} {2sigma ^ {2}} }} hned]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/38356615fcbbd3459fa6208500c4f7510f58abc3)
![{displaystyle l = - {frac {n} {2}} log {2pi sigma ^ {2}} + součet _ {i = 1} ^ {n} log {left [e ^ {- {frac {left (x_ { i} -mu ight) ^ {2}} {2sigma ^ {2}}}} vlevo (1 + e ^ {- {frac {vlevo (x_ {i} + mu ight) ^ {2}} {2sigma ^ { 2}}}} e ^ {frac {left (x_ {i} -mu ight) ^ {2}} {2sigma ^ {2}}} ight) ight]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e73ea6fa7d9c0d187340912c1cb8aeb4f5ac8676)











