Bioinformatika - Bioinformatics


| Část série na |
| Biochemie |
|---|
 |
| Klíčové komponenty |
| Dějiny biochemie |
| Glosáře |
| Portály: Biochemie |
Bioinformatika /ˌbaɪ.oʊˌɪnF.rˈm…tɪks/ (![]() poslouchat) je mezioborové obor, který vyvíjí metody a softwarové nástroje pro pochopení biologický data, zejména jsou-li datové soubory velké a složité. Jako interdisciplinární vědní obor se bioinformatika kombinuje biologie, počítačová věda, informační inženýrství, matematika a statistika analyzovat a interpretovat biologická data. Byla použita bioinformatika in silico analýzy biologických dotazů pomocí matematických a statistických technik.[je zapotřebí objasnění ]
poslouchat) je mezioborové obor, který vyvíjí metody a softwarové nástroje pro pochopení biologický data, zejména jsou-li datové soubory velké a složité. Jako interdisciplinární vědní obor se bioinformatika kombinuje biologie, počítačová věda, informační inženýrství, matematika a statistika analyzovat a interpretovat biologická data. Byla použita bioinformatika in silico analýzy biologických dotazů pomocí matematických a statistických technik.[je zapotřebí objasnění ]
Bioinformatika zahrnuje biologické studie, které využívají programování jako součást své metodiky i specifické analytické "potrubí", které se opakovaně používají, zejména v oblasti genomika. Mezi běžná použití bioinformatiky patří identifikace kandidátů geny a svobodný nukleotid polymorfismy (SNP ). Často se taková identifikace provádí s cílem lepšího pochopení genetického základu nemoci, jedinečných adaptací, žádoucích vlastností (zejména u zemědělských druhů) nebo rozdílů mezi populacemi. Méně formálním způsobem se bioinformatika také snaží pochopit organizační principy uvnitř nukleová kyselina a protein sekvence, tzv proteomika.[1]
Úvod
Bioinformatika se stala důležitou součástí mnoha biologických oblastí. V experimentální molekulární biologie, bioinformatické techniky, jako je obraz a zpracování signálu umožňuje extrakci užitečných výsledků z velkého množství nezpracovaných dat. V oblasti genetiky pomáhá při sekvenování a anotaci genomů a jejich pozorování mutace. Hraje roli v dolování textu biologické literatury a vývoj biologické a genové ontologie organizovat a dotazovat se na biologická data. Hraje také roli v analýze genové a proteinové exprese a regulace. Nástroje bioinformatiky pomáhají srovnávat, analyzovat a interpretovat genetická a genomická data a obecněji porozumět evolučním aspektům molekulární biologie. Na integrační úrovni pomáhá analyzovat a katalogizovat biologické cesty a sítě, které jsou důležitou součástí biologie systémů. v strukturní biologie, pomáhá při simulaci a modelování DNA,[2] RNA,[2][3] bílkoviny[4] stejně jako biomolekulární interakce.[5][6][7][8]
Dějiny
Historicky termín bioinformatika neznamenalo to, co to znamená dnes. Paulien Hogeweg a Ben Hesper vytvořil v roce 1970 odkaz na studium informačních procesů v biotických systémech.[9][10][11] Tato definice postavila bioinformatiku jako pole paralelní s biochemie (studium chemických procesů v biologických systémech).[9]
Sekvence

Když se počítače staly nezbytnými v molekulární biologii proteinové sekvence byly k dispozici po Frederick Sanger určil posloupnost inzulín na počátku 50. let. Ruční porovnání více sekvencí se ukázalo jako nepraktické. Průkopníkem v oboru byl Margaret Oakley Dayhoff.[12] Sestavila jednu z prvních databází proteinových sekvencí, původně publikovaných jako knihy[13] a průkopnické metody sekvenčního zarovnání a molekulární evoluce.[14] Dalším časným přispěvatelem do bioinformatiky byl Elvin A. Kabat, který byl průkopníkem biologické sekvenční analýzy v roce 1970 svými komplexními objemy sekvencí protilátek uvolněných s Tai Te Wu v letech 1980 až 1991.[15]V 70. letech byly na bakteriofág MS2 a ř174 aplikovány nové techniky sekvenování DNA a rozšířené nukleotidové sekvence byly poté analyzovány informačními a statistickými algoritmy. Tyto studie ukázaly, že dobře známé funkce, jako jsou kódovací segmenty a tripletový kód, jsou odhaleny v přímých statistických analýzách, a byly tak důkazem konceptu, že bioinformatika by měla být vhledná.[16][17]
Cíle
Abychom mohli studovat, jak se normální buněčné aktivity mění v různých chorobných stavech, musí být kombinována biologická data, aby se vytvořil komplexní obraz těchto aktivit. Proto se oblast bioinformatiky vyvinula tak, že nejnaléhavější úkol nyní zahrnuje analýzu a interpretaci různých typů dat. To zahrnuje nukleotid a aminokyselinové sekvence, proteinové domény, a proteinové struktury.[18] Samotný proces analýzy a interpretace dat je označován jako výpočetní biologie. Mezi důležité dílčí disciplíny v bioinformatice a výpočetní biologii patří:
- Vývoj a implementace počítačových programů, které umožňují efektivní přístup k různým typům informací, jejich správu a používání.
- Vývoj nových algoritmů (matematické vzorce) a statistických opatření, která hodnotí vztahy mezi členy velkých souborů dat. Například existují metody k vyhledání a gen v sekvenci, k předpovědi struktury a / nebo funkce proteinu a k shluk proteinové sekvence do rodin příbuzných sekvencí.
Primárním cílem bioinformatiky je zvýšit porozumění biologickým procesům. Co ho však odlišuje od ostatních přístupů, je jeho zaměření na vývoj a aplikaci výpočetně náročných technik k dosažení tohoto cíle. Mezi příklady patří: rozpoznávání vzorů, dolování dat, strojové učení algoritmy a vizualizace. Mezi hlavní výzkumné snahy v této oblasti patří zarovnání sekvence, nález genů, shromáždění genomu, design léku, objev drog, zarovnání proteinové struktury, predikce proteinové struktury, predikce genová exprese a interakce protein-protein, genomové asociační studie, modelování vývoj a buněčné dělení / mitóza.
Bioinformatika nyní zahrnuje vytváření a zdokonalování databází, algoritmů, výpočetních a statistických technik a teorie k řešení formálních a praktických problémů vyplývajících ze správy a analýzy biologických dat.
Během několika posledních desetiletí došlo k rychlému vývoji genomových a dalších technologií molekulárního výzkumu a vývoji v roce 2006 informační technologie spojili dohromady a vytvořili obrovské množství informací souvisejících s molekulární biologií. Bioinformatika je název pro tyto matematické a výpočetní přístupy, které se používají k získání porozumění biologickým procesům.
Mezi běžné činnosti v bioinformatice patří mapování a analýza DNA a proteinové sekvence, sladění DNA a proteinových sekvencí k jejich porovnání a vytváření a prohlížení 3-D modelů proteinových struktur.
Vztah k jiným polím
Bioinformatika je vědní obor, který je podobný, ale odlišný od biologický výpočet, i když se často považuje za synonymum výpočetní biologie. Využití biologických výpočtů bioinženýrství a biologie budovat biologické počítače vzhledem k tomu, že bioinformatika využívá výpočty k lepšímu porozumění biologii. Bioinformatika a výpočetní biologie zahrnují analýzu biologických dat, zejména sekvencí DNA, RNA a proteinů. Od poloviny 90. let 20. století došlo v oblasti bioinformatiky k prudkému růstu, který byl způsoben zejména Projekt lidského genomu a rychlým pokrokem v technologii sekvenování DNA.
Analýza biologických dat za účelem získání smysluplných informací zahrnuje psaní a spouštění softwarových programů, které používají algoritmy z teorie grafů, umělá inteligence, soft computing, dolování dat, zpracování obrazu, a počítačová simulace. Algoritmy zase závisí na teoretických základech, jako je diskrétní matematika, teorie řízení, teorie systémů, teorie informace, a statistika.
Sekvenční analýza
Protože Fág Φ-X174 byl seřazeno v roce 1977,[19] the DNA sekvence tisíce organismů byly dekódovány a uloženy v databázích. Tato informace o sekvenci je analyzována za účelem určení genů, které kódují bílkoviny, Geny RNA, regulační sekvence, strukturní motivy a opakující se sekvence. Srovnání genů v rámci a druh nebo mezi různými druhy mohou vykazovat podobnosti mezi funkcemi bílkovin nebo vztahy mezi druhy (použití molekulární systematika konstruovat fylogenetické stromy ). S rostoucím množstvím dat se již dávno stalo nepraktickým analyzovat sekvence DNA ručně. Počítačové programy jako VÝBUCH se běžně používají k vyhledávání sekvencí - od roku 2008 z více než 260 000 organismů, které obsahují více než 190 miliard nukleotidy.[20]
Sekvenování DNA
Než mohou být sekvence analyzovány, musí být získány z příkladu banky datových úložišť Genbank. Sekvenování DNA je stále non-triviální problém, protože nezpracovaná data mohou být hlučná nebo ovlivněna slabými signály. Algoritmy byly vyvinuty pro základní volání pro různé experimentální přístupy k sekvenování DNA.
Sekvenční sestava
Většina technik sekvenování DNA produkuje krátké fragmenty sekvence, které je třeba sestavit, aby se získaly úplné sekvence genu nebo genomu. Takzvaný sekvenování brokovnice technika (kterou použil např Institut pro genomický výzkum (TIGR) k sekvenci prvního bakteriálního genomu, Haemophilus influenzae )[21] generuje sekvence mnoha tisíců malých fragmentů DNA (v rozmezí od 35 do 900 nukleotidů, v závislosti na technologii sekvenování). Konce těchto fragmentů se překrývají a pokud jsou správně srovnány programem genomu, mohou být použity k rekonstrukci celého genomu. Sekvenování brokovnic poskytuje rychle data sekvence, ale úkol sestavit fragmenty může být pro větší genomy docela komplikovaný. Pro genom tak velký jako lidský genom, sestavení fragmentů může trvat mnoho dní času CPU na víceprocesorových počítačích s velkou pamětí a výsledná sestava obvykle obsahuje četné mezery, které je třeba později vyplnit. Sekvenování brokovnic je metoda volby pro prakticky všechny dnes sekvenované genomy[když? ]a algoritmy sestavování genomu jsou kritickou oblastí bioinformatického výzkumu.
Anotace genomu
V kontextu genomika, anotace je proces značení genů a dalších biologických znaků v sekvenci DNA. Tento proces je třeba automatizovat, protože většina genomů je příliš velká na to, aby bylo možné je anotovat ručně, nemluvě o touze anotovat co nejvíce genomů, jako je rychlost sekvenování přestal představovat překážku. Anotace je umožněna skutečností, že geny mají rozeznatelné počáteční a koncové oblasti, ačkoli přesná sekvence nalezená v těchto oblastech se může mezi geny lišit.
První popis komplexního anotačního systému genomu byl publikován v roce 1995[21] týmem v Institut pro genomický výzkum který provedl první úplné sekvenování a analýzu genomu volně žijícího organismu, bakterie Haemophilus influenzae.[21] Owen White navrhl a postavil softwarový systém k identifikaci genů kódujících všechny proteiny, přenosu RNA, ribozomálních RNA (a dalších míst) a k provádění počátečních funkčních přiřazení. Většina současných systémů pro anotaci genomu funguje podobně, ale programy dostupné pro analýzu genomové DNA, jako například GeneMark program vyškolen a použit k nalezení genů kódujících proteiny Haemophilus influenzae, se neustále mění a zlepšují.
V návaznosti na cíle, které projekt lidského genomu ponechal k dosažení po jeho uzavření v roce 2003, se objevil nový projekt vyvinutý Národním ústavem pro výzkum lidského genomu ve Spojených státech. Takzvaný ZAKÓDOVAT projekt je společný sběr dat funkčních prvků lidského genomu, který využívá technologie DNA sekvenování příští generace a pole genomických obkladů, technologie schopné automaticky generovat velké množství dat při dramaticky snížených nákladech na bázi, ale se stejnou přesností (chyba základního volání) a věrnost (chyba sestavy).
Výpočetní evoluční biologie
Evoluční biologie je studie o původu a původu druh, jakož i jejich změny v čase. Informatika pomáhal evolučním biologům tím, že umožňoval výzkumným pracovníkům:
- sledovat vývoj velkého počtu organismů měřením změn jejich DNA, spíše než pouze prostřednictvím fyzické taxonomie nebo fyziologických pozorování,
- porovnat celý genomy, což umožňuje studium složitějších evolučních událostí, jako např genová duplikace, horizontální přenos genů a predikce faktorů důležitých u bakterií speciace,
- vytvořit komplexní výpočetní populační genetika modely k předpovědi výsledku systému v průběhu času[22]
- sledovat a sdílet informace o stále větším počtu druhů a organismů
Budoucí práce se snaží rekonstruovat nyní složitější strom života.[podle koho? ]
Oblast výzkumu uvnitř počítačová věda který používá genetické algoritmy je někdy zaměňována s výpočetní evoluční biologií, ale tyto dvě oblasti nemusí nutně souviset.
Srovnávací genomika
Jádrem komparativní genomové analýzy je vytvoření korespondence mezi geny (ortologie analýza) nebo jiné genomové znaky v různých organismech. Právě tyto intergenomické mapy umožňují sledovat evoluční procesy odpovědné za divergenci dvou genomů. Evoluce genomu formuje mnoho evolučních událostí působících na různých organizačních úrovních. Na nejnižší úrovni bodové mutace ovlivňují jednotlivé nukleotidy. Na vyšší úrovni procházejí velké chromozomální segmenty duplikací, postranním přenosem, inverzí, transpozicí, delecí a inzercí.[23] Nakonec jsou celé genomy zapojeny do procesů hybridizace, polyploidizace a endosymbióza, což často vede k rychlé speciaci. Složitost evoluce genomu představuje mnoho vzrušujících výzev pro vývojáře matematických modelů a algoritmů, kteří využívají spektrum algoritmických, statistických a matematických technik, od přesných, heuristika, pevný parametr a aproximační algoritmy pro problémy založené na modelech šetrnosti k Markovský řetězec Monte Carlo algoritmy pro Bayesovská analýza problémů na základě pravděpodobnostních modelů.
Mnoho z těchto studií je založeno na detekci sekvenční homologie přiřadit sekvence proteinové rodiny.[24]
Pan genomika
Pan genomics je koncept představený v roce 2005 Tettelinem a Medinim, který se nakonec zakořenil v bioinformatice. Pan genom je kompletní genový repertoár určité taxonomické skupiny: ačkoli byl původně použit pro blízce příbuzné kmeny druhů, lze jej použít v širším kontextu, jako je rod, kmen atd. Je rozdělen do dvou částí - Základní genom: Sada genů společných pro všechny studované genomy (často se jedná o geny pro udržení životně důležité pro přežití) a The Dispensable / Flexible Genome: Sada genů, které nejsou přítomny ve všech kromě jednoho nebo některých studovaných genomů. K charakterizaci Pan genomu bakteriálních druhů lze použít nástroj bioinformatiky BPGA.[25]
Genetika nemoci
S příchodem sekvenování nové generace získáváme dostatek sekvenčních dat k mapování genů komplexních onemocnění neplodnost,[26] rakovina prsu[27] nebo Alzheimerova choroba.[28] Celogenomové asociační studie jsou užitečným přístupem k určení mutací odpovědných za tak složitá onemocnění.[29] Prostřednictvím těchto studií byly identifikovány tisíce variant DNA, které jsou spojeny s podobnými nemocemi a rysy.[30] Jednou z nejdůležitějších aplikací je dále možnost použití genů při prognóze, diagnostice nebo léčbě. Mnoho studií diskutuje jak o slibných způsobech výběru genů, které mají být použity, tak o problémech a úskalích používání genů k předpovědi přítomnosti nemoci nebo prognózy.[31]
Analýza mutací u rakoviny
v rakovina, jsou genomy postižených buněk přeskupeny složitými nebo dokonce nepředvídatelnými způsoby. K identifikaci dříve neznámých se používají masivní snahy o sekvenování bodové mutace v různých geny při rakovině. Bioinformatici pokračují ve výrobě specializovaných automatizovaných systémů pro správu čistého objemu vyprodukovaných sekvenčních dat a vytvářejí nové algoritmy a software pro srovnání výsledků sekvenování s rostoucí sbírkou lidský genom sekvence a zárodečná linie polymorfismy. Používají se nové technologie fyzické detekce, například oligonukleotid mikročipy k identifikaci chromozomálních zisků a ztrát (tzv komparativní genomová hybridizace ), a jedno-nukleotidový polymorfismus pole pro detekci známých bodové mutace. Tyto detekční metody současně měří několik stovek tisíc míst v celém genomu a při použití s vysokou propustností k měření tisíců vzorků generují terabajtů dat na experiment. Velké množství a nové typy dat opět generují nové příležitosti pro bioinformatiky. Často se zjistí, že údaje obsahují značnou variabilitu, nebo hluk, a tudíž Skrytý Markovův model a metody analýzy bodu změny jsou vyvíjeny tak, aby bylo možné odvodit skutečné číslo kopie Změny.
Při analýze genomů rakoviny bioinformaticky vztahujících se k identifikaci mutací v buňce lze použít dva důležité principy. exome. Za prvé, rakovina je onemocnění nahromaděných somatických mutací v genech. Druhá rakovina obsahuje mutace řidiče, které je třeba odlišit od cestujících.[32]
Díky průlomům, které tato technologie sekvenování nové generace poskytuje v oblasti bioinformatiky, by se genomika rakoviny mohla drasticky změnit. Tyto nové metody a software umožňují bioinformatikům rychle a cenově dostupné sekvenování mnoha genomů rakoviny. To by mohlo vytvořit pružnější proces klasifikace typů rakoviny analýzou mutací vyvolaných rakovinou v genomu. Kromě toho může být v budoucnu možné sledovat pacienty při progresi onemocnění pomocí sekvence vzorků rakoviny.[33]
Dalším typem dat, který vyžaduje vývoj nové informatiky, je analýza léze bylo zjištěno, že se opakuje mezi mnoha nádory.
Genová a proteinová exprese
Analýza genové exprese
The výraz mnoha genů lze určit měřením mRNA úrovně s více technikami včetně mikročipy, exprimovaný tag sekvence cDNA (EST) sekvenování, sériová analýza genové exprese Sekvenování značek (SAGE), masivně paralelní řazení podpisů (MPSS), RNA-sekv, známý také jako „Whole Transcriptome Shotgun Sequencing“ (WTSS), nebo různé aplikace multiplexované hybridizace in-situ. Všechny tyto techniky jsou extrémně náchylné k hluku a / nebo podléhají zkreslení v biologickém měření a hlavní oblast výzkumu ve výpočetní biologii zahrnuje vývoj statistických nástrojů k oddělení signál z hluk ve studiích genové exprese s vysokou propustností.[34] Takové studie se často používají k určení genů, které se podílejí na poruše: dalo by se porovnat údaje z mikročipů z rakovinných onemocnění epiteliální buňky k datům z nerakovinných buněk k určení transkriptů, které jsou up-regulovány a down-regulovány v konkrétní populaci rakovinných buněk.
Analýza exprese proteinu
Proteinové mikročipy a vysoká propustnost (HT) hmotnostní spektrometrie (MS) může poskytnout snímek proteinů přítomných v biologickém vzorku. Bioinformatika se velmi podílí na porozumění proteinové microarray a HT MS dat; první přístup čelí podobným problémům jako u mikročipů zaměřených na mRNA, druhý zahrnuje problém shody velkého množství údajů o hmotnosti s předpokládanými hmotnostmi z databází proteinových sekvencí a komplikovanou statistickou analýzu vzorků, kde je více, ale nekompletních peptidů zjištěno. Lokalizace buněčného proteinu v tkáňovém kontextu lze dosáhnout pomocí afinity proteomika zobrazeny jako prostorová data na základě imunohistochemie a tkáňové mikročipy.[35]
Analýza regulace
Regulace genů je komplexní orchestrace událostí, kterými signál, potenciálně extracelulární signál, jako je a hormon, případně vede ke zvýšení nebo snížení aktivity jednoho nebo více bílkoviny. K prozkoumání různých kroků v tomto procesu byly použity bioinformatické techniky.
Například genová exprese může být regulována blízkými prvky v genomu. Analýza promotorů zahrnuje identifikaci a studium sekvenční motivy v DNA obklopující kódující oblast genu. Tyto motivy ovlivňují rozsah, ve kterém je tato oblast přepsána do mRNA. Vylepšovač prvky daleko od promotoru mohou také regulovat genovou expresi prostřednictvím trojrozměrných smyčkových interakcí. Tyto interakce lze určit bioinformatickou analýzou zachycení konformace chromozomu experimenty.
K odvození genové regulace lze použít údaje o expresi: lze porovnat microarray data z nejrůznějších stavů organismu k vytvoření hypotéz o genech zapojených do každého stavu. V jednobuněčném organismu lze srovnávat stadia buněčný cyklus, spolu s různými stresovými podmínkami (tepelný šok, hladovění atd.). Poté je možné se přihlásit shlukovací algoritmy k těmto datům exprese určit, které geny jsou exprimovány společně. Například nadřazené oblasti (promotory) společně exprimovaných genů lze hledat nadměrně zastoupené regulační prvky. Příklady shlukovacích algoritmů použitých při shlukování genů jsou k-znamená shlukování, samoorganizující se mapy (SOM), hierarchické shlukování, a shoda shlukování metody.
Analýza buněčné organizace
Bylo vyvinuto několik přístupů k analýze umístění organel, genů, proteinů a dalších složek v buňkách. To je relevantní, protože umístění těchto složek ovlivňuje dění v buňce a pomáhá nám tak předvídat chování biologických systémů. A genová ontologie kategorie, buněčná složka, byl vyvinut pro zachycení subcelulární lokalizace v mnoha biologické databáze.
Mikroskopie a analýza obrazu
Mikroskopické obrázky nám umožňují najít obojí organely stejně jako molekuly. Může nám také pomoci rozlišovat mezi normálními a abnormálními buňkami, např. v rakovina.
Lokalizace proteinů
Lokalizace proteinů nám pomáhá vyhodnotit roli proteinu. Například pokud se v proteinu nachází protein jádro může být zapojen do genová regulace nebo sestřih. Naproti tomu, pokud je protein nalezen v mitochondrie, může být zapojen do dýchání nebo jiný metabolické procesy. Lokalizace bílkovin je tedy důležitou součástí predikce funkce proteinu. Jsou dobře vyvinuté predikce subcelulární lokalizace proteinu dostupné zdroje, včetně databází subcelulárních lokalizací proteinů a nástrojů pro predikci.[36][37]
Jaderná organizace chromatinu
Data z vysoké propustnosti zachycení konformace chromozomu experimenty, jako např Hi-C (experiment) a ChIA-PET, může poskytnout informace o prostorové blízkosti lokusů DNA. Analýzou těchto experimentů lze určit trojrozměrnou strukturu a jaderná organizace chromatinu. Bioinformatické výzvy v této oblasti zahrnují rozdělení genomu do domén, jako je např Topologicky sdružující domény (TAD), které jsou organizovány společně v trojrozměrném prostoru.[38]
Strukturální bioinformatika
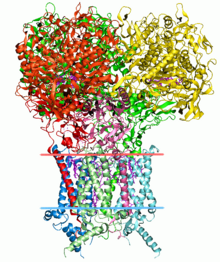
Predikce struktury proteinů je další důležitou aplikací bioinformatiky. The aminokyselina sekvence proteinu, tzv primární struktura lze snadno určit ze sekvence genu, který jej kóduje. Ve velké většině případů tato primární struktura jednoznačně určuje strukturu ve svém nativním prostředí. (Samozřejmě existují výjimky, například bovinní spongiformní encefalopatie (nemoc šílených krav) prion.) Znalost této struktury je zásadní pro pochopení funkce proteinu. Strukturální informace jsou obvykle klasifikovány jako jedna z sekundární, terciární a kvartérní struktura. Životaschopné obecné řešení těchto předpovědí zůstává otevřeným problémem. Většina úsilí byla dosud zaměřena na heuristiku, která funguje většinu času.[Citace je zapotřebí ]
Jednou z klíčových myšlenek v bioinformatice je pojem homologie. V genomové větvi bioinformatiky se homologie používá k předpovědi funkce genu: pokud sekvence genu A, jehož funkce je známá, je homologní se sekvencí gen B, jehož funkce není známa, lze odvodit, že B může sdílet funkci A. Ve strukturální větvi bioinformatiky se používá homologie k určení, které části proteinu jsou důležité při tvorbě struktury a interakci s jinými proteiny. V technice zvané homologické modelování, tato informace se používá k předpovědi struktury proteinu, jakmile je známa struktura homologního proteinu. To v současné době zůstává jediným způsobem, jak spolehlivě předpovědět proteinové struktury.
Jedním z příkladů je hemoglobin u lidí a hemoglobin v luštěninách (leghemoglobin ), což jsou vzdálení příbuzní od stejného proteinová nadčeleď. Oba slouží ke stejnému účelu transportu kyslíku v organismu. Ačkoli oba tyto proteiny mají zcela odlišné aminokyselinové sekvence, jejich proteinové struktury jsou prakticky identické, což odráží jejich téměř identické účely a sdíleného předka.[39]
Další techniky pro predikci struktury proteinů zahrnují proteinové vlákno a de novo (od nuly) modelování založené na fyzice.
Dalším aspektem strukturální bioinformatiky je použití proteinových struktur pro Virtuální promítání modely jako Kvantitativní vztah mezi strukturou a aktivitou modely a proteochemometrické modely (PCM). Kromě toho lze krystalovou strukturu proteinu použít při simulaci například studií vázání ligandů a in silico studie mutageneze.
Síť a biologie systémů
Síťová analýza snaží se pochopit vztahy uvnitř biologické sítě jako metabolické nebo interakční sítě protein – protein. Ačkoli biologické sítě mohou být konstruovány z jednoho typu molekuly nebo entity (například geny), síťová biologie se často pokouší integrovat mnoho různých datových typů, jako jsou proteiny, malé molekuly, údaje o genové expresi a další, které jsou fyzicky propojeny , funkčně, nebo obojí.
Systémová biologie zahrnuje použití počítačové simulace z buněčný subsystémy (např sítě metabolitů a enzymy které obsahují metabolismus, signální transdukce cesty a genové regulační sítě ) jak analyzovat, tak vizualizovat složitá spojení těchto buněčných procesů. Umělý život nebo virtuální evoluce se pokouší porozumět evolučním procesům prostřednictvím počítačové simulace jednoduchých (umělých) forem života.
Sítě molekulární interakce

Byly určeny desítky tisíc trojrozměrných proteinových struktur Rentgenová krystalografie a proteinová nukleární magnetická rezonanční spektroskopie (proteinová NMR) a ústřední otázkou ve strukturální bioinformatice je, zda je praktické předpovídat možné interakce protein - protein pouze na základě těchto 3D tvarů, aniž by interakce protein-protein experimenty. K řešení problému byla vyvinuta řada metod dokování protein – protein problém, i když se zdá, že v této oblasti je ještě mnoho práce.
Mezi další interakce vyskytující se v této oblasti patří Protein-ligand (včetně léku) a protein – peptid. Molekulární dynamická simulace pohybu atomů kolem otočných vazeb je základním principem výpočetní techniky algoritmy, nazývané dokovací algoritmy, pro studium molekulární interakce.
Ostatní
Analýza literatury
Nárůst počtu publikované literatury prakticky znemožňuje přečíst každý článek, což má za následek nesouvislé dílčí oblasti výzkumu. Cílem analýzy literatury je využití výpočetní a statistické lingvistiky k těžbě této rostoucí knihovny textových zdrojů. Například:
- Rozpoznávání zkratek - identifikujte dlouhodobou formu a zkratku biologických termínů
- Rozpoznávání pojmenovaných entit - rozpoznávání biologických termínů, jako jsou názvy genů
- Interakce protein - protein - identifikujte které bílkoviny interagovat s kterými proteiny z textu
Oblast výzkumu čerpá z statistika a výpočetní lingvistika.
Vysoce výkonná analýza obrazu
Výpočetní technologie se používají k urychlení nebo úplné automatizaci zpracování, kvantifikace a analýzy velkého množství obsahu s vysokým obsahem informací biomedicínské snímky. Moderní analýza obrazu systémy zlepšují schopnost pozorovatele provádět měření z velké nebo složité sady obrazů přesnost, objektivnost nebo rychlost. Plně vyvinutý analytický systém může pozorovatele zcela nahradit. Ačkoli tyto systémy nejsou pro biomedicínské snímky jedinečné, biomedicínské zobrazování je pro oba stále důležitější diagnostika a výzkum. Některé příklady jsou:
- vysoce výkonná a vysoce věrná kvantifikace a subcelulární lokalizace (vysoce obsahový screening cytohistopatologie, Bioimage informatika )
- morfometrie
- analýza a vizualizace klinického obrazu
- stanovení vzorů proudění vzduchu v reálném čase v dýchacích plicích živých zvířat
- kvantifikace velikosti okluze v obrazech v reálném čase z vývoje a zotavení během arteriálního poranění
- provádění behaviorálních pozorování z rozšířených videozáznamů laboratorních zvířat
- infračervená měření pro stanovení metabolické aktivity
- inferring clone overlaps in Mapování DNA, např. the Skóre Sulston
Vysoce výkonná analýza dat jedné buňky
Výpočetní techniky se používají k analýze vysoce výkonných a nízko naměřených dat jednotlivých buněk, jako jsou údaje získané z průtoková cytometrie. Tyto metody obvykle zahrnují hledání populací buněk, které jsou relevantní pro konkrétní chorobný stav nebo experimentální stav.
Informatika o biologické rozmanitosti
Informatika o biologické rozmanitosti se zabývá sběrem a analýzou biologická rozmanitost data, jako např taxonomické databáze nebo mikrobiom data. Mezi příklady takových analýz patří fylogenetika, modelování výklenků, druhová bohatost mapování, Čárové kódy DNA nebo druh identifikační nástroje.
Ontologie a integrace dat
Biologické ontologie jsou směrované acyklické grafy z řízené slovníky. Jsou navrženy tak, aby zachytily biologické koncepty a popisy způsobem, který lze snadno kategorizovat a analyzovat pomocí počítačů. Při kategorizaci tímto způsobem je možné získat přidanou hodnotu z holistické a integrované analýzy.
The Slévárna OBO byla snaha standardizovat určité ontologie. Jedním z nejrozšířenějších je Genová ontologie který popisuje genovou funkci. Existují také ontologie, které popisují fenotypy.
Databáze
Databáze jsou nezbytné pro bioinformatický výzkum a aplikace. Existuje mnoho databází, které pokrývají různé typy informací: například DNA a proteinové sekvence, molekulární struktury, fenotypy a biologická rozmanitost. Databáze mohou obsahovat empirická data (získaná přímo z experimentů), predikovaná data (získaná z analýzy) nebo nejčastěji obojí. Mohou být specifické pro konkrétní organismus, cestu nebo sledovanou molekulu. Alternativně mohou začlenit data zkompilovaná z několika dalších databází. Tyto databáze se liší svým formátem, přístupovým mechanismem a tím, zda jsou veřejné nebo ne.
Níže jsou uvedeny některé z nejčastěji používaných databází. Podrobnější seznam najdete na odkazu na začátku podsekce.
- Používá se v biologické sekvenční analýze: Genbank, UniProt
- Používá se ve strukturní analýze: Proteinová datová banka (PDB)
- Používá se při hledání proteinových rodin a Motiv Nález: InterPro, Pfam
- Používá se pro sekvenování nové generace: Archiv čtení sekvence
- Používá se v síťové analýze: databáze metabolických cest (KEGG, BioCyc ), Databáze pro analýzu interakcí, funkční sítě
- Používá se při konstrukci syntetických genetických obvodů: GenoCAD
Software a nástroje
Softwarové nástroje pro bioinformatiku od jednoduchých nástrojů příkazového řádku až po složitější grafické programy a samostatné webové služby dostupné z různých bioinformatické společnosti nebo veřejné instituce.
Open-source bioinformatický software
Mnoho bezplatný open source software nástroje existují a nadále rostou od 80. let.[40] Kombinace přetrvávající potřeby nového algoritmy pro analýzu objevujících se typů biologických odečtů potenciál pro inovace in silico experimenty a volně dostupné otevřený kód základny pomohly vytvořit příležitosti pro všechny výzkumné skupiny, aby přispěly jak k bioinformatice, tak k nabídce dostupného softwaru s otevřeným zdrojem, bez ohledu na jejich financování. Nástroje otevřeného zdroje často fungují jako inkubátory nápadů nebo podporované komunitou zásuvné moduly v komerčních aplikacích. Mohou také poskytnout de facto standardy a modely sdílených objektů pro pomoc s výzvou integrace bioinformací.
The řada softwarových balíků open-source zahrnuje tituly jako Biovodič, BioPerl, Biopython, BioJava, BioJS, BioRuby, Bioclipse, VYTEPAT, .NET Bio, oranžový s doplňkem bioinformatiky, Apache Taverna, UGENE a GenoCAD. Chcete-li zachovat tuto tradici a vytvořit další příležitosti, neziskové Otevřená nadace pro bioinformatiku[40] podpořili výroční Bioinformatics Open Source Conference (BOSC) since 2000.[41]
An alternative method to build public bioinformatics databases is to use the MediaWiki engine with the WikiOpener rozšíření. This system allows the database to be accessed and updated by all experts in the field.[42]
Web services in bioinformatics
SOAP - a ZBYTEK -based interfaces have been developed for a wide variety of bioinformatics applications allowing an application running on one computer in one part of the world to use algorithms, data and computing resources on servers in other parts of the world. The main advantages derive from the fact that end users do not have to deal with software and database maintenance overheads.
Basic bioinformatics services are classified by the EBI into three categories: SSS (Sequence Search Services), MSA (Multiple Sequence Alignment), and BSA (Biological Sequence Analysis).[43] The availability of these service-oriented bioinformatics resources demonstrate the applicability of web-based bioinformatics solutions, and range from a collection of standalone tools with a common data format under a single, standalone or web-based interface, to integrative, distributed and extensible bioinformatics workflow management systems.
Bioinformatics workflow management systems
A bioinformatics workflow management system is a specialized form of a workflow management system designed specifically to compose and execute a series of computational or data manipulation steps, or a workflow, in a Bioinformatics application. Such systems are designed to
- provide an easy-to-use environment for individual application scientists themselves to create their own workflows,
- provide interactive tools for the scientists enabling them to execute their workflows and view their results in real-time,
- simplify the process of sharing and reusing workflows between the scientists, and
- enable scientists to track the původ of the workflow execution results and the workflow creation steps.
Some of the platforms giving this service: Galaxie, Kepler, Taverna, UGENE, Anduril, HIVE.
BioCompute and BioCompute Objects
V roce 2014 US Food and Drug Administration sponsored a conference held at the Národní institut zdraví Bethesda Campus to discuss reproducibility in bioinformatics.[44] Over the next three years, a consortium of stakeholders met regularly to discuss what would become BioCompute paradigm.[45] These stakeholders included representatives from government, industry, and academic entities. Session leaders represented numerous branches of the FDA and NIH Institutes and Centers, non-profit entities including the Human Variome Project a European Federation for Medical Informatics, and research institutions including Stanford, New York Genome Center a Univerzita George Washingtona.
It was decided that the BioCompute paradigm would be in the form of digital 'lab notebooks' which allow for the reproducibility, replication, review, and reuse, of bioinformatics protocols. This was proposed to enable greater continuity within a research group over the course of normal personnel flux while furthering the exchange of ideas between groups. The US FDA funded this work so that information on pipelines would be more transparent and accessible to their regulatory staff.[46]
In 2016, the group reconvened at the NIH in Bethesda and discussed the potential for a BioCompute Object, an instance of the BioCompute paradigm. This work was copied as both a "standard trial use" document and a preprint paper uploaded to bioRxiv. The BioCompute object allows for the JSON-ized record to be shared among employees, collaborators, and regulators.[47][48]
Education platforms
Software platforms designed to teach bioinformatics concepts and methods include Rosalind and online courses offered through the Swiss Institute of Bioinformatics Training Portal. The Canadian Bioinformatics Workshops provides videos and slides from training workshops on their website under a Creative Commons licence. The 4273π project or 4273pi project[49] also offers open source educational materials for free. The course runs on low cost Raspberry Pi computers and has been used to teach adults and school pupils.[50][51] 4273π is actively developed by a consortium of academics and research staff who have run research level bioinformatics using Raspberry Pi computers and the 4273π operating system.[52][53]
MOOC platforms also provide online certifications in bioinformatics and related disciplines, including Coursera 's Bioinformatics Specialization (UC San Diego ) and Genomic Data Science Specialization (Johns Hopkins ) stejně jako EdX 's Data Analysis for Life Sciences XSeries (Harvard ). University of Southern California offers a Masters In Translational Bioinformatics focusing on biomedical applications.
Konference
There are several large conferences that are concerned with bioinformatics. Some of the most notable examples are Intelligent Systems for Molecular Biology (ISMB), European Conference on Computational Biology (ECCB), and Research in Computational Molecular Biology (RECOMB).
Viz také
- Biodiversity informatics
- Bioinformatics companies
- Výpočetní biologie
- Výpočetní biomodeling
- Computational genomics
- Cyberbiosecurity
- Functional genomics
- Health informatics
- International Society for Computational Biology
- Jumping library
- List of bioinformatics institutions
- Seznam open-source bioinformatického softwaru
- List of bioinformatics journals
- Metabolomika
- Sekvence nukleové kyseliny
- Fylogenetika
- Proteomika
- Gene Disease Database
Reference
- ^ Lesk, A. M. (26 July 2013). "Bioinformatics". Encyclopaedia Britannica.
- ^ A b Sim, A. Y. L.; Minary, P.; Levitt, M. (2012). "Modeling nucleic acids". Aktuální názor na strukturní biologii. 22 (3): 273–78. doi:10.1016/j.sbi.2012.03.012. PMC 4028509. PMID 22538125.
- ^ Dawson, W. K.; Maciejczyk, M.; Jankowska, E. J.; Bujnicki, J. M. (2016). "Coarse-grained modeling of RNA 3D structure". Metody. 103: 138–56. doi:10.1016/j.ymeth.2016.04.026. PMID 27125734.
- ^ Kmiecik, S.; Gront, D.; Kolinski, M.; Wieteska, L.; Dawid, A. E.; Kolinski, A. (2016). "Coarse-Grained Protein Models and Their Applications". Chemické recenze. 116 (14): 7898–936. doi:10.1021/acs.chemrev.6b00163. PMID 27333362.
- ^ Wong, K. C. (2016). Computational Biology and Bioinformatics: Gene Regulation. CRC Press/Taylor & Francis Group. ISBN 9781498724975.
- ^ Joyce, A. P.; Zhang, C .; Bradley, P.; Havranek, J. J. (2015). "Structure-based modeling of protein: DNA specificity". Briefings in Functional Genomics. 14 (1): 39–49. doi:10.1093/bfgp/elu044. PMC 4366589. PMID 25414269.
- ^ Spiga, E.; Degiacomi, M. T.; Dal Peraro, M. (2014). "New Strategies for Integrative Dynamic Modeling of Macromolecular Assembly". In Karabencheva-Christova, T. (ed.). Biomolecular Modelling and Simulations. Advances in Protein Chemistry and Structural Biology. 96. Akademický tisk. pp. 77–111. doi:10.1016/bs.apcsb.2014.06.008. ISBN 9780128000137. PMID 25443955.
- ^ Ciemny, Maciej; Kurcinski, Mateusz; Kamel, Karol; Kolinski, Andrzej; Alam, Nawsad; Schueler-Furman, Ora; Kmiecik, Sebastian (4 May 2018). "Protein–peptide docking: opportunities and challenges". Objev drog dnes. 23 (8): 1530–37. doi:10.1016/j.drudis.2018.05.006. ISSN 1359-6446. PMID 29733895.
- ^ A b Hogeweg P (2011). Searls, David B. (ed.). "The Roots of Bioinformatics in Theoretical Biology". PLOS výpočetní biologie. 7 (3): e1002021. Bibcode:2011PLSCB...7E2021H. doi:10.1371/journal.pcbi.1002021. PMC 3068925. PMID 21483479.
- ^ Hesper B, Hogeweg P (1970). "Bioinformatica: een werkconcept". 1 (6). Kameleon: 28–29. Citovat deník vyžaduje
| deník =(Pomoc) - ^ Hogeweg P (1978). "Simulating the growth of cellular forms". Simulace. 31 (3): 90–96. doi:10.1177/003754977803100305. S2CID 61206099.
- ^ Moody, Glyn (2004). Digital Code of Life: How Bioinformatics is Revolutionizing Science, Medicine, and Business. ISBN 978-0-471-32788-2.
- ^ Dayhoff, M.O. (1966) Atlas of protein sequence and structure. National Biomedical Research Foundation, 215 pp.
- ^ Eck RV, Dayhoff MO (1966). "Evolution of the structure of ferredoxin based on living relics of primitive amino Acid sequences". Věda. 152 (3720): 363–66. Bibcode:1966Sci...152..363E. doi:10.1126/science.152.3720.363. PMID 17775169. S2CID 23208558.
- ^ Johnson G, Wu TT (January 2000). "Kabat Database and its applications: 30 years after the first variability plot". Nucleic Acids Res. 28 (1): 214–18. doi:10.1093/nar/28.1.214. PMC 102431. PMID 10592229.
- ^ Erickson, JW; Altman, GG (1979). "A Search for Patterns in the Nucleotide Sequence of the MS2 Genome". Journal of Mathematical Biology. 7 (3): 219–230. doi:10.1007/BF00275725. S2CID 85199492.
- ^ Shulman, MJ; Steinberg, CM; Westmoreland, N (1981). "The Coding Function of Nucleotide Sequences can be Discerned by Statistical Analysis". Journal of Theoretical Biology. 88 (3): 409–420. doi:10.1016/0022-5193(81)90274-5. PMID 6456380.
- ^ Xiong, Jin (2006). Essential Bioinformatics. Cambridge, Velká Británie: Cambridge University Press. str.4. ISBN 978-0-511-16815-4 - prostřednictvím internetového archivu.
- ^ Sanger F, Air GM, Barrell BG, Brown NL, Coulson AR, Fiddes CA, Hutchison CA, Slocombe PM, Smith M (February 1977). "Nucleotide sequence of bacteriophage phi X174 DNA". Příroda. 265 (5596): 687–95. Bibcode:1977Natur.265..687S. doi:10.1038/265687a0. PMID 870828. S2CID 4206886.
- ^ Benson DA, Karsch-Mizrachi I, Lipman DJ, Ostell J, Wheeler DL (January 2008). "GenBank". Nucleic Acids Res. 36 (Database issue): D25–30. doi:10.1093/nar/gkm929. PMC 2238942. PMID 18073190.
- ^ A b C Fleischmann RD, Adams MD, White O, Clayton RA, Kirkness EF, Kerlavage AR, Bult CJ, Tomb JF, Dougherty BA, Merrick JM (July 1995). "Whole-genome random sequencing and assembly of Haemophilus influenzae Rd". Věda. 269 (5223): 496–512. Bibcode:1995Sci...269..496F. doi:10.1126/science.7542800. PMID 7542800.
- ^ Carvajal-Rodríguez A (2012). "Simulation of Genes and Genomes Forward in Time". Current Genomics. 11 (1): 58–61. doi:10.2174/138920210790218007. PMC 2851118. PMID 20808525.
- ^ Brown, TA (2002). "Mutation, Repair and Recombination". Genomes (2. vyd.). Manchester (UK): Oxford.
- ^ Carter, N. P.; Fiegler, H.; Piper, J. (2002). "Comparative analysis of comparative genomic hybridization microarray technologies: Report of a workshop sponsored by the Wellcome trust". Cytometry Part A. 49 (2): 43–48. doi:10.1002/cyto.10153. PMID 12357458.
- ^ Chaudhari Narendrakumar M., Kumar Gupta Vinod, Dutta Chitra (2016). "BPGA-an ultra-fast pan-genome analysis pipeline". Vědecké zprávy. 6: 24373. Bibcode:2016NatSR...624373C. doi:10.1038/srep24373. PMC 4829868. PMID 27071527.CS1 maint: více jmen: seznam autorů (odkaz)
- ^ Aston KI (2014). "Genetic susceptibility to male infertility: News from genome-wide association studies". Andrologie. 2 (3): 315–21. doi:10.1111/j.2047-2927.2014.00188.x. PMID 24574159. S2CID 206007180.
- ^ Véron A, Blein S, Cox DG (2014). "Genome-wide association studies and the clinic: A focus on breast cancer". Biomarkers in Medicine. 8 (2): 287–96. doi:10.2217/bmm.13.121. PMID 24521025.
- ^ Tosto G, Reitz C (2013). "Genome-wide association studies in Alzheimer's disease: A review". Current Neurology and Neuroscience Reports. 13 (10): 381. doi:10.1007/s11910-013-0381-0. PMC 3809844. PMID 23954969.
- ^ Londin E, Yadav P, Surrey S, Kricka LJ, Fortina P (2013). Use of linkage analysis, genome-wide association studies, and next-generation sequencing in the identification of disease-causing mutations. Farmakogenomika. Metody v molekulární biologii. 1015. pp. 127–46. doi:10.1007/978-1-62703-435-7_8. ISBN 978-1-62703-434-0. PMID 23824853.
- ^ Hindorff, L.A.; et al. (2009). "Potential etiologic and functional implications of genome-wide association loci for human diseases and traits". Proc. Natl. Acad. Sci. USA. 106 (23): 9362–67. Bibcode:2009PNAS..106.9362H. doi:10.1073/pnas.0903103106. PMC 2687147. PMID 19474294.
- ^ Hall, L.O. (2010). "Finding the right genes for disease and prognosis prediction". 2010 International Conference on System Science and Engineering. System Science and Engineering (ICSSE),2010 International Conference. s. 1–2. doi:10.1109/ICSSE.2010.5551766. ISBN 978-1-4244-6472-2. S2CID 21622726.
- ^ Vazquez, Miguel; Torre, Victor de la; Valencia, Alfonso (27 December 2012). "Chapter 14: Cancer Genome Analysis". PLOS výpočetní biologie. 8 (12): e1002824. Bibcode:2012PLSCB...8E2824V. doi:10.1371/journal.pcbi.1002824. ISSN 1553-7358. PMC 3531315. PMID 23300415.
- ^ Hye-Jung, E.C.; Jaswinder, K.; Martin, K.; Samuel, A.A; Marco, A.M (2014). "Second-Generation Sequencing for Cancer Genome Analysis". In Dellaire, Graham; Berman, Jason N.; Arceci, Robert J. (eds.). Cancer Genomics. Boston (US): Academic Press. pp. 13–30. doi:10.1016/B978-0-12-396967-5.00002-5. ISBN 9780123969675.
- ^ Grau, J.; Ben-Gal, I.; Posch, S.; Grosse, I. (1 July 2006). "VOMBAT: prediction of transcription factor binding sites using variable order Bayesian trees" (PDF). Výzkum nukleových kyselin. 34 (Web Server): W529–W533. doi:10.1093/nar/gkl212. PMC 1538886. PMID 16845064.
- ^ "The Human Protein Atlas". www.proteinatlas.org. Citováno 2. října 2017.
- ^ "The human cell". www.proteinatlas.org. Citováno 2. října 2017.
- ^ Thul, Peter J.; Åkesson, Lovisa; Wiking, Mikaela; Mahdessian, Diana; Geladaki, Aikaterini; Blal, Hammou Ait; Alm, Tove; Asplund, Anna; Björk, Lars (26 May 2017). "A subcellular map of the human proteome". Věda. 356 (6340): eaal3321. doi:10.1126/science.aal3321. PMID 28495876. S2CID 10744558.
- ^ Ay, Ferhat; Noble, William S. (2 September 2015). "Analysis methods for studying the 3D architecture of the genome". Genome Biology. 16 (1): 183. doi:10.1186/s13059-015-0745-7. PMC 4556012. PMID 26328929.
- ^ Hoy, JA; Robinson, H; Trent JT, 3rd; Kakar, S; Smagghe, BJ; Hargrove, MS (3 August 2007). "Plant hemoglobins: a molecular fossil record for the evolution of oxygen transport". Journal of Molecular Biology. 371 (1): 168–79. doi:10.1016/j.jmb.2007.05.029. PMID 17560601.
- ^ A b "Open Bioinformatics Foundation: About us". Oficiální webové stránky. Otevřená nadace pro bioinformatiku. Citováno 10. května 2011.
- ^ "Open Bioinformatics Foundation: BOSC". Oficiální webové stránky. Otevřená nadace pro bioinformatiku. Citováno 10. května 2011.
- ^ Brohée, Sylvain; Barriot, Roland; Moreau, Yves (2010). "Biological knowledge bases using Wikis: combining the flexibility of Wikis with the structure of databases". Bioinformatika. 26 (17): 2210–11. doi:10.1093/bioinformatics/btq348. PMID 20591906.
- ^ Nisbet, Robert (2009). "Bioinformatics". Handbook of Statistical Analysis and Data Mining Applications. John Elder IV, Gary Miner. Akademický tisk. p. 328. ISBN 978-0080912035.
- ^ Commissioner, Office of the. "Advancing Regulatory Science – Sept. 24–25, 2014 Public Workshop: Next Generation Sequencing Standards". www.fda.gov. Citováno 30. listopadu 2017.
- ^ Simonyan, Vahan; Goecks, Jeremy; Mazumder, Raja (2017). "Biocompute Objects – A Step towards Evaluation and Validation of Biomedical Scientific Computations". PDA Journal of Pharmaceutical Science and Technology. 71 (2): 136–46. doi:10.5731/pdajpst.2016.006734. ISSN 1079-7440. PMC 5510742. PMID 27974626.
- ^ Commissioner, Office of the. "Advancing Regulatory Science – Community-based development of HTS standards for validating data and computation and encouraging interoperability". www.fda.gov. Citováno 30. listopadu 2017.
- ^ Alterovitz, Gil; Dean, Dennis A.; Goble, Carole; Crusoe, Michael R.; Soiland-Reyes, Stian; Bell, Amanda; Hayes, Anais; King, Charles Hadley S.; Johanson, Elaine (4 October 2017). "Enabling Precision Medicine via standard communication of NGS provenance, analysis, and results". bioRxiv 10.1101/191783.
- ^ BioCompute Object (BCO) project is a collaborative and community-driven framework to standardize HTS computational data. 1. BCO Specification Document: user manual for understanding and creating B., biocompute-objects, 3 September 2017
- ^ Barker, D; Ferrier, D.E.K.; Holland, P.W; Mitchell, J.B.O; Plaisier, H; Ritchie, M.G; Smart, S.D. (2013). "4273π : bioinformatics education on low cost ARM hardware". BMC bioinformatika. 14: 243. doi:10.1186/1471-2105-14-243. PMC 3751261. PMID 23937194.
- ^ Barker, D; Alderson, R.G; McDonagh, J.L; Plaisier, H; Comrie, M.M; Duncan, L; Muirhead, G.T.P; Sweeny, S.D. (2015). "University-level practical activities in bioinformatics benefit voluntary groups of pupils in the last 2 years of school". International Journal of STEM Education. 2 (17). doi:10.1186/s40594-015-0030-z.
- ^ McDonagh, J.L; Barker, D; Alderson, R.G. (2016). "Bringing computational science to the public". SpringerPlus. 5 (259): 259. doi:10.1186/s40064-016-1856-7. PMC 4775721. PMID 27006868.
- ^ Robson, J.F.; Barker, D (2015). "Comparison of the protein-coding gene content of Chlamydia trachomatis and Protochlamydia amoebophila using a Raspberry Pi computer". Poznámky k výzkumu BMC. 8 (561): 561. doi:10.1186/s13104-015-1476-2. PMC 4604092. PMID 26462790.
- ^ Wregglesworth, K.M; Barker, D (2015). "A comparison of the protein-coding genomes of two green sulphur bacteria, Chlorobium tepidum TLS and Pelodictyon phaeoclathratiforme BU-1". Poznámky k výzkumu BMC. 8 (565): 565. doi:10.1186/s13104-015-1535-8. PMC 4606965. PMID 26467441.
Další čtení
- Sehgal et al. : Structural, phylogenetic and docking studies of D-amino acid oxidase activator(DAOA ), a candidate schizophrenia gene. Theoretical Biology and Medical Modelling 2013 10 :3.
- Raul Isea The Present-Day Meaning Of The Word Bioinformatics, Global Journal of Advanced Research, 2015
- Achuthsankar S Nair Computational Biology & Bioinformatics – A gentle Overview, Communications of Computer Society of India, January 2007
- Aluru, Srinivas, vyd. Handbook of Computational Molecular Biology. Chapman & Hall/Crc, 2006. ISBN 1-58488-406-1 (Chapman & Hall/Crc Computer and Information Science Series)
- Baldi, P and Brunak, S, Bioinformatics: The Machine Learning Approach, 2nd edition. MIT Press, 2001. ISBN 0-262-02506-X
- Barnes, M.R. and Gray, I.C., eds., Bioinformatics for Geneticists, first edition. Wiley, 2003. ISBN 0-470-84394-2
- Baxevanis, A.D. and Ouellette, B.F.F., eds., Bioinformatics: A Practical Guide to the Analysis of Genes and Proteins, third edition. Wiley, 2005. ISBN 0-471-47878-4
- Baxevanis, A.D., Petsko, G.A., Stein, L.D., and Stormo, G.D., eds., Current Protocols in Bioinformatics. Wiley, 2007. ISBN 0-471-25093-7
- Cristianini, N. and Hahn, M. Introduction to Computational Genomics, Cambridge University Press, 2006. (ISBN 9780521671910 |ISBN 0-521-67191-4)
- Durbin, R., S. Eddy, A. Krogh and G. Mitchison, Biological sequence analysis. Cambridge University Press, 1998. ISBN 0-521-62971-3
- Gilbert D (2004). "Bioinformatics software resources". Briefings in Bioinformatics. 5 (3): 300–304. doi:10.1093/bib/5.3.300. PMID 15383216.
- Keedwell, E., Intelligent Bioinformatics: The Application of Artificial Intelligence Techniques to Bioinformatics Problems. Wiley, 2005. ISBN 0-470-02175-6
- Kohane, et al. Microarrays for an Integrative Genomics. The MIT Press, 2002. ISBN 0-262-11271-X
- Lund, O. et al. Immunological Bioinformatics. The MIT Press, 2005. ISBN 0-262-12280-4
- Pachter, Lior a Sturmfels, Bernd. "Algebraic Statistics for Computational Biology" Cambridge University Press, 2005. ISBN 0-521-85700-7
- Pevzner, Pavel A. Computational Molecular Biology: An Algorithmic Approach The MIT Press, 2000. ISBN 0-262-16197-4
- Soinov, L. Bioinformatics and Pattern Recognition Come Together Journal of Pattern Recognition Research (JPRR ), Vol 1 (1) 2006 p. 37–41
- Stevens, Hallam, Life Out of Sequence: A Data-Driven History of Bioinformatics, Chicago: The University of Chicago Press, 2013, ISBN 9780226080208
- Tisdall, James. "Beginning Perl for Bioinformatics" O'Reilly, 2001. ISBN 0-596-00080-4
- Catalyzing Inquiry at the Interface of Computing and Biology (2005) CSTB report
- Calculating the Secrets of Life: Contributions of the Mathematical Sciences and computing to Molecular Biology (1995)
- Foundations of Computational and Systems Biology MIT Course
- Computational Biology: Genomes, Networks, Evolution Free MIT Course
externí odkazy
| Prostředky knihovny o Bioinformatika |
- Zvuková pomoc
- Více mluvených článků
 Slovníková definice bioinformatika na Wikislovníku
Slovníková definice bioinformatika na Wikislovníku Učební materiály související s Bioinformatika na Wikiversity
Učební materiály související s Bioinformatika na Wikiversity Média související s Bioinformatika na Wikimedia Commons
Média související s Bioinformatika na Wikimedia Commons- Bioinformatics Resource Portal (SIB)
| Genomika | |
|---|---|
| Bioinformatika | |
| Strukturní biologie | |
| Research tools | |
| Organizace | |
| |

Poznámka: Tato šablona zhruba navazuje na rok 2012 ACM Computing Classification System. | ||
| Hardware |  | |
| Počítačové systémy organizace | ||
| Sítě | ||
| Organizace softwaru | ||
| Softwarové notace a nástroje | ||
| Vývoj softwaru | ||
| Teorie výpočtu | ||
| Algoritmy | ||
| Matematika výpočetní techniky | ||
| Informace systémy |
| |
| Bezpečnostní | ||
| Člověk - počítač interakce | ||
| Konkurence | ||
| Umělý inteligence | ||
| Strojové učení | ||
| Grafika | ||
| Aplikovaný výpočetní |
| |
| ||