Metagenomika - Metagenomics - Wikipedia

Metagenomika je studium genetický materiál získaný přímo z životní prostředí Vzorky. Široká oblast může být také označována jako genomika životního prostředí, ekogenomika nebo komunitní genomika.
Zatímco tradiční mikrobiologie a mikrobiální sekvenování genomu a genomika spoléhat na kultivovaný klonální kultur, časné sekvenování genů prostředí klonovalo specifické geny (často 16S rRNA gen) k vytvoření profilu rozmanitosti v přirozeném vzorku. Taková práce odhalila, že drtivá většina z mikrobiální biologická rozmanitost byl zmeškán kultivačními metodami.[2]
Díky své schopnosti odhalit dříve skrytou rozmanitost mikroskopického života nabízí metagenomika výkonný objektiv pro sledování mikrobiálního světa, který má potenciál převratu v chápání celého živého světa.[3] Vzhledem k tomu, že cena sekvenování DNA stále klesá, metagenomika to nyní umožňuje mikrobiální ekologie být zkoumány v mnohem větším měřítku a podrobněji než dříve. Nedávné studie používají buď „brokovnice „nebo PCR řízené sekvenování k získání do značné míry nezaujatých vzorků všech genů od všech členů vzorkovaných komunit.[4]
Etymologie
Pojem „metagenomika“ poprvé použil Jo Handelsman, Jon Clardy, Robert M. Goodman, Sean F. Brady a další, a poprvé se objevil v publikaci v roce 1998.[5] Termín metagenom odkazoval na myšlenku, že soubor genů sekvenovaných z prostředí lze analyzovat způsobem analogickým ke studiu jediného genom. V roce 2005, Kevin Chen a Lior Pachter (vědci z University of California, Berkeley ) definoval metagenomiku jako „aplikaci moderní genomické techniky bez nutnosti izolace a laboratorní kultivace jednotlivých druhů“.[6]
Dějiny
Konvenční sekvenování začíná kultivací identických buněk jako zdroje DNA. Rané metagenomické studie však odhalily, že v mnoha prostředích pravděpodobně existují velké skupiny mikroorganismů, které nemohou být kultivovaný a nelze je tedy sekvenovat. Tyto rané studie se zaměřily na 16S ribozomální RNA (rRNA) sekvence, které jsou relativně krátké, často konzervovaný v rámci druhu a obecně se liší mezi druhy. Mnoho 16S rRNA byly nalezeny sekvence, které nepatří k žádným známým kultivovaným druh, což naznačuje, že existuje mnoho neizolovaných organismů. Tyto průzkumy genů ribozomální RNA odebrané přímo z prostředí to ukázaly pěstování založené metody naleznou méně než 1% bakteriálních a archaeal druh ve vzorku.[2] Velká část zájmu o metagenomiku pochází z těchto objevů, které ukázaly, že drtivá většina mikroorganismů zůstala dříve bez povšimnutí.
Brzy molekulární práce v terénu provedl Norman R. Pace a kolegové, kteří používali PCR prozkoumat rozmanitost sekvencí ribozomální RNA.[7] Poznatky získané z těchto průlomových studií vedly Pace k myšlence klonovat DNA přímo ze vzorků životního prostředí již v roce 1985.[8] To vedlo k první zprávě o izolaci a klonování objemová DNA ze vzorku prostředí, publikovaná Paceem a kolegy v roce 1991[9] zatímco Pace byl na katedře biologie v Indiana University. Značné úsilí zajistilo, že tomu tak nebylo PCR falešných poplachů a podpořila existenci složitého společenství neprozkoumaných druhů. Ačkoli se tato metodika omezila na zkoumání vysoce konzervativních, neproteinové kódující geny, podpořila časná pozorování založená na mikrobiální morfologii, že rozmanitost byla mnohem složitější, než byla známá kultivačními metodami. Brzy nato Healy ohlásil metagenomickou izolaci funkčních genů ze „zoolibrik“ vytvořených ze složité kultury environmentálních organismů pěstovaných v laboratoři na sušených trávy v roce 1995.[10] Po opuštění laboratoře Pace Edward DeLong pokračoval v této oblasti a vydal práci, která do značné míry položila základy pro ekologické fylogeneze založené na signaturních 16S sekvencích, počínaje konstrukcí jeho skupiny knihoven z námořní Vzorky.[11]
V roce 2002 Mya Breitbart, Forest Rohwer „a kolegové použili sekvenování brokovnic v prostředí (viz níže), aby ukázali, že 200 litrů mořské vody obsahuje více než 5 000 různých virů.[12] Následující studie ukázaly, že jich je více než tisíc virové druhy v lidské stolici a možná milion různých virů na kilogram mořského sedimentu, včetně mnoha bakteriofágy. V podstatě všechny viry v těchto studiích byly nové druhy. V roce 2004 Gene Tyson, Jill Banfield a kolegové z University of California, Berkeley a Společný genomový institut sekvenovaná DNA extrahovaná z kyselý důl odvodnění Systém.[13] Toto úsilí vyústilo v úplné nebo téměř úplné genomy pro několik bakterií a archaea který dříve odolával pokusům o jejich kultivaci.[14]
Počínaje rokem 2003, Craig Venter, vůdce soukromě financované paralely Projekt lidského genomu, vedl Global Ocean Sampling Expedition (GOS), obíhající planetu a sbírat metagenomické vzorky po celou dobu cesty. Všechny tyto vzorky jsou sekvenovány pomocí brokovnicového sekvenování v naději, že budou identifikovány nové genomy (a tedy nové organismy). Pilotní projekt prováděný v EU Sargasové moře, našel DNA z téměř 2 000 různých druh, včetně 148 druhů bakterie nikdy předtím neviděl.[15] Venter obeplul celou planetu a důkladně prozkoumal Západní pobřeží Spojených států a absolvoval dvouletou expedici k prozkoumání Pobaltí, Středomoří a Černá Moře. Analýza metagenomických údajů shromážděných během této cesty odhalila dvě skupiny organismů, jednu složenou z taxonů přizpůsobených podmínkám prostředí „svátku nebo hladomoru“ a druhou složenou z relativně méně, ale hojněji a široce rozšířených taxonů primárně složených z plankton.[16]
V roce 2005 Stephan C. Schuster ve společnosti Penn State University a kolegové publikovali první sekvence vzorku prostředí generovaného pomocí vysoce výkonné sekvenování, v tomto případě masivně paralelní pyrosekvenování vyvinutý uživatelem 454 biologických věd.[17] Další časný příspěvek v této oblasti se objevil v roce 2006 Robertem Edwardsem, Forest Rohwer a kolegové v Státní univerzita v San Diegu.[18]
Sekvenování
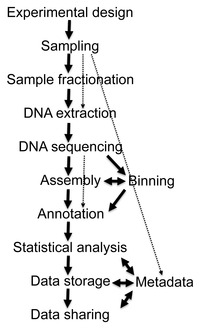
Obnova sekvencí DNA delší než několik tisíc základní páry z prostředí Vzorky bylo velmi obtížné až do nedávných pokroků v molekulárně biologické techniky umožnily konstrukci knihovny v bakteriální umělé chromozomy (BAC), které poskytovaly lepší výsledky vektory pro molekulární klonování.[20]
Brokovnice metagenomika
Pokroky v bioinformatika, zdokonalení amplifikace DNA a šíření výpočetní síly velmi pomohly analýze sekvencí DNA získaných ze vzorků prostředí, což umožnilo adaptaci sekvenování brokovnice na metagenomické vzorky (známé také jako brokovnice celého metagenomu nebo sekvenování WMGS). Tento přístup používaný k sekvenování mnoha kultivovaných mikroorganismů a lidský genom, náhodně stříhá DNA, sekvence mnoho krátkých sekvencí a rekonstruuje je do konsensuální sekvence. Sekvenování brokovnic odhaluje geny přítomné ve vzorcích prostředí. Historicky byly pro usnadnění tohoto sekvenování použity klonové knihovny. S pokrokem v technologiích sekvenování s vysokou propustností však krok klonování již není nutný a bez tohoto pracovně náročného kroku s úzkými místy lze dosáhnout většího výnosu dat sekvenování. Brokovnice metagenomika poskytuje informace o tom, které organismy jsou přítomny a jaké metabolické procesy jsou v komunitě možné.[21] Protože sběr DNA z prostředí je do značné míry nekontrolovaný, jsou ve výsledných sekvenčních datech nejvíce zastoupeny nejhojnější organismy ve vzorku prostředí. K dosažení vysokého pokrytí potřebného k úplnému vyřešení genomů nedostatečně zastoupených členů komunity jsou zapotřebí velké vzorky, často neúnosně. Na druhou stranu náhodná povaha sekvenování brokovnic zajišťuje, že mnoho z těchto organismů, které by jinak zůstaly bez povšimnutí při použití tradičních kultivačních technik, bude představováno alespoň několika malými segmenty sekvence.[13]
Vysoce výkonné sekvenování
Výhodou sekvenování s vysokou propustností je, že tato technika nevyžaduje klonování DNA před sekvenováním, odstranění jedné z hlavních předsudků a úzkých míst při vzorkování prostředí. První metagenomické studie provedené pomocí vysoce výkonné sekvenování používán masivně paralelně 454 pyrosekvenování.[17] Tři další technologie běžně používané při vzorkování životního prostředí jsou: Ion Torrent Personal Genome Machine, Illumina MiSeq nebo HiSeq a Applied Biosystems SOLiD Systém.[22] Tyto techniky pro sekvenování DNA generují kratší fragmenty než Sangerovo sekvenování; Ion Torrent PGM System a 454 pyrosekvenování obvykle produkuje ~ 400 bp čtení, Illumina MiSeq produkuje 400-700 bp čtení (v závislosti na tom, zda jsou použity možnosti spárovaného konce) a SOLiD produkuje 25–75 bp čtení.[23] Historicky byly tyto délky čtení podstatně kratší než typická délka čtení Sangerova sekvenování ~ 750 bp, avšak technologie Illumina se tomuto benchmarku rychle přibližuje. Toto omezení je však kompenzováno mnohem větším počtem přečtených sekvencí. V roce 2009 generovaly pyosekvenované metagenomy 200–500 megabází a platformy Illumina generovaly zhruba 20–50 gigabází, ale tyto výstupy se v posledních letech řádově zvýšily.[24]
Objevující se přístup kombinuje sekvenování brokovnic a zachycení konformace chromozomu (Hi-C), který měří blízkost dvou libovolných sekvencí DNA ve stejné buňce, aby vedl shromáždění mikrobiálního genomu.[25] Technologie sekvenování dlouhého čtení, včetně PacBio RSII a PacBio Sequel od Pacific Biosciences a Nanopore MinION, Grigion, PromotION od Oxford Nanopore Technologies, je další volba, jak získat dlouhé sekvenční čtení brokovnice, které by mělo usnadnit proces montáže.[26]
Bioinformatika
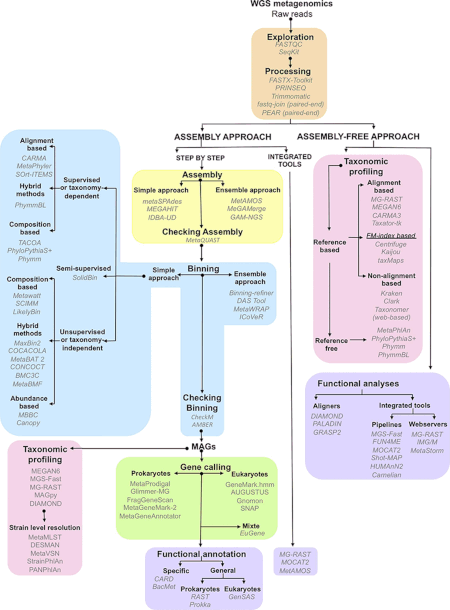
Data generovaná metagenomickými experimenty jsou obrovská a neodmyslitelně hlučná a obsahují fragmentovaná data představující až 10 000 druhů.[1] Sekvenování krávy bachor metagenom generoval 279 gigabáze nebo 279 miliard párů bází dat nukleotidové sekvence,[28] zatímco lidské střevo mikrobiom Katalog genů identifikoval 3,3 milionu genů shromážděných z 567,7 gigabází sekvenčních dat.[29] Shromažďování, kurátorství a extrakce užitečných biologických informací z datových souborů této velikosti představují pro výzkumníky významné výpočetní výzvy.[21][30][31][32]
Sekvenční předfiltrování
První krok analýzy metagenomických dat vyžaduje provedení určitých kroků předfiltrování, včetně odstranění nadbytečných sekvencí nízké kvality a sekvencí pravděpodobných eukaryotický původu (zejména u metagenomů lidského původu).[33][34] Dostupné metody pro odstranění kontaminujících sekvencí eukaryotické genomové DNA zahrnují Eu-Detect a DeConseq.[35][36]
Shromáždění
Data sekvence DNA z genomových a metagenomických projektů jsou v podstatě stejná, ale data genomové sekvence nabízejí vyšší Dosah zatímco metagenomická data jsou obvykle vysoce nepotřebná.[31] Navíc zvýšené používání sekvenčních technologií druhé generace s malými délkami čtení znamená, že velká část budoucích metagenomických dat bude náchylná k chybám. V kombinaci těchto faktorů je obtížné a nespolehlivé sestavení metagenomických sekvenčních čtení do genomů. Nesprávné sestavy jsou způsobeny přítomností opakující se sekvence DNA díky nimž je montáž obzvláště obtížná kvůli rozdílu v relativním množství druhů přítomných ve vzorku.[37] Misassemblies mohou také zahrnovat kombinaci sekvencí z více než jednoho druhu do chimérické kontigy.[37]
Existuje několik montážních programů, z nichž většina může využívat informace z spárované značky za účelem zlepšení přesnosti sestav. Některé programy, jako např Phrap nebo Celera Assembler, byly navrženy tak, aby mohly být použity k sestavení single genomy ale přesto přinášejí dobré výsledky při sestavování souborů metagenomických dat.[1] Jiné programy, jako např Velvet assembler, byly optimalizovány pro kratší čtení produkované sekvenováním druhé generace pomocí de Bruijn grafy.[38][39] Použití referenčních genomů umožňuje vědcům zlepšit seskupení nejhojnějších mikrobiálních druhů, ale tento přístup je omezen malou podskupinou mikrobiálních kmenů, pro které jsou k dispozici sekvenované genomy.[37] Po vytvoření sestavy je další výzvou „metagenomická dekonvoluce“ nebo určení, které sekvence pocházejí z jakéhokoli druhu ve vzorku.[40]
Genová předpověď
Metagenomická analýza potrubí použít dva přístupy v anotaci kódovacích oblastí v sestavených kontigách.[37] Prvním přístupem je identifikace genů na základě homologie s geny, které jsou již veřejně dostupné v sekvenční databáze, obvykle do VÝBUCH vyhledávání. Tento typ přístupu je implementován v programu MEGAN 4.[41] Druhý, ab initio, používá vnitřní rysy sekvence k předpovědi kódujících oblastí na základě genových tréninkových sad od příbuzných organismů. Jedná se o přístup, který zaujímají programy jako GeneMark[42] a ZÁBLESK. Hlavní výhodou ab initio predikce je, že umožňuje detekci kódujících oblastí, které postrádají homology v sekvenčních databázích; je však nejpřesnější, když jsou pro srovnání k dispozici velké oblasti souvislé genomové DNA.[1]
Druhová rozmanitost
Genové anotace poskytují „co“ při měření druhová rozmanitost poskytnout „kdo“.[43] Aby bylo možné propojit složení a funkci komunity v metagenomech, musí být sekvence binovány. Binning je proces přidružení určité sekvence k organismu.[37] V binningu založeném na podobnosti se používají metody jako VÝBUCH se používají k rychlému hledání fylogenetických markerů nebo jinak podobných sekvencí ve stávajících veřejných databázích. Tento přístup je implementován v MEGAN.[44] Další nástroj, PhymmBL, používá interpolované Markovovy modely přiřadit čtení.[1] MetaPhlAn a AMFORA jsou metody založené na jedinečných markerech specifických pro clade pro odhad relativního množství organismů se zlepšenými výpočetními výkony.[45] Jiné nástroje, jako MOTU[46][47] a MetaPhyler,[48] používat univerzální markerové geny k profilování prokaryotických druhů. S mOTUs profiler je možné profilovat druhy bez referenčního genomu, což zlepšuje odhad rozmanitosti mikrobiální komunity.[47] Poslední metody, jako např SLIMM, použijte prostředí pokrytí čtení jednotlivých referenčních genomů k minimalizaci falešně pozitivních zásahů a získání spolehlivých relativních hojností.[49] V binningu založeném na složení používají metody vnitřní znaky sekvence, jako jsou frekvence oligonukleotidů nebo zkreslení použití kodonů.[1] Jakmile jsou sekvence binovány, je možné provést srovnávací analýzu rozmanitosti a bohatosti.
Integrace dat
Obrovské množství exponenciálně rostoucích sekvenčních dat je skličující výzvou, kterou komplikuje složitost metadata spojené s metagenomickými projekty. Metadata zahrnují podrobné informace o trojrozměrné (včetně hloubky nebo výšky) zeměpisné a environmentální vlastnosti vzorku, fyzická data o místě vzorkování a metodiku vzorkování.[31] Tyto informace jsou nezbytné k zajištění replikovatelnost a umožnit následnou analýzu. Z důvodu jeho důležitosti vyžadují metadata a kolaborativní kontrola a kurátorství dat standardizované datové formáty umístěné ve specializovaných databázích, jako je Genomes OnLine Database (GOLD).[50]
Pro integraci metadat a sekvenčních dat bylo vyvinuto několik nástrojů, které umožňují následné komparativní analýzy různých datových sad s využitím řady ekologických indexů. V roce 2007 Folker Meyer a Robert Edwards a tým v Argonne National Laboratory a University of Chicago vydala Metagenomics Rapid Annotation pomocí serveru Subsystem Technology (MG-RAST ) komunitní zdroj pro analýzu datových sad metagenomu.[51] V červnu 2012 přes 14,8 terabáz (14x1012 Byly analyzovány DNA) a více než 10 000 veřejných datových sad je volně k dispozici pro srovnání v rámci MG-RAST. Více než 8 000 uživatelů nyní odeslalo do MG-RAST celkem 50 000 metagenomů. The Integrované mikrobiální geny / metagenomy Systém (IMG / M) také poskytuje sbírku nástrojů pro funkční analýzu mikrobiálních komunit na základě jejich sekvence metagenomu na základě referenčních izolátů genomů zahrnutých z Integrované mikrobiální geny (IMG) a systém Genomická encyklopedie bakterií a archaeí (GEBA) projekt.[52]
Jedním z prvních samostatných nástrojů pro analýzu vysoce výkonných dat brokovnice metagenomu byl MEGAN (ANalyzer MEta Genome).[41][44] První verze programu byla použita v roce 2005 k analýze metagenomického kontextu sekvencí DNA získaných z mamutí kosti.[17] Na základě srovnání BLAST s referenční databází tento nástroj provádí jak taxonomické, tak funkční binningy, a to tak, že umisťuje čtení na uzly taxonomie NCBI pomocí jednoduchého algoritmu nejnižšího společného předka (LCA) nebo na uzly SEMÍNKO nebo KEGG klasifikace, resp.[53]
S příchodem rychlých a levných sekvenčních nástrojů je růst databází sekvencí DNA nyní exponenciální (např. Databáze NCBI GenBank [54]). K udržení kroku s vysoce výkonným sekvenováním jsou potřeba rychlejší a účinnější nástroje, protože přístupy založené na BLAST jako MG-RAST nebo MEGAN běží pomalu, aby anotovaly velké vzorky (např. Několik hodin na zpracování datové sady / vzorku malé / střední velikosti) [55]). Nedávno se tak objevily ultrarychlé klasifikátory díky dostupnějším výkonným serverům. Tyto nástroje mohou provádět taxonomickou anotaci extrémně vysokou rychlostí, například CLARK [56] (podle autorů CLARK dokáže přesně klasifikovat „32 milionů metagenomických krátkých čtení za minutu“). Při takové rychlosti lze zpracovat velmi velkou datovou sadu / vzorek s miliardou krátkých čtení za přibližně 30 minut.
S rostoucí dostupností vzorků obsahujících starodávnou DNA a kvůli nejistotě spojené s povahou těchto vzorků (starodávné poškození DNA),[57] byl k dispozici rychlý nástroj schopný vytvářet konzervativní odhady podobnosti. Podle autorů FALCONu může používat uvolněné prahové hodnoty a upravovat vzdálenosti, aniž by to ovlivnilo výkon paměti a rychlosti.
Srovnávací metagenomika
Srovnávací analýzy mezi metagenomy mohou poskytnout další vhled do funkce komplexních mikrobiálních komunit a jejich role ve zdraví hostitele.[58] Na úrovni složení sekvence lze provést párové nebo vícenásobné srovnání metagenomů (porovnání Obsah GC nebo velikost genomu), taxonomická rozmanitost nebo funkční doplněk. Porovnání struktury populace a fylogenetické rozmanitosti lze provést na základě 16S a jiných genů fylogenetických markerů, nebo - v případě společenstev s nízkou rozmanitostí - rekonstrukcí genomu z metagenomického datového souboru.[59] Funkční srovnání mezi metagenomy lze provést porovnáním sekvencí s referenčními databázemi, jako je OZUBENÉ KOLO nebo KEGG, a tabelace četnosti podle kategorií a vyhodnocení případných rozdílů pro statistickou významnost.[53] Tento přístup zaměřený na geny zdůrazňuje funkční doplněk společenství spíše jako celek než taxonomické skupiny a ukazuje, že funkční doplňky jsou analogické za podobných podmínek prostředí.[59] V důsledku toho jsou metadata o environmentálním kontextu metagenomického vzorku zvláště důležitá ve srovnávacích analýzách, protože poskytuje vědcům schopnost studovat vliv stanoviště na strukturu a funkci komunity.[1]
Několik studií navíc využilo vzorce využití oligonukleotidů k identifikaci rozdílů mezi různými mikrobiálními komunitami. Mezi příklady takových metodik patří přístup relativní hojnosti dinukleotidů Willner et al.[60] a přístup HabiSign od Ghosh et al.[61] Tato druhá studie také naznačila, že rozdíly ve vzorcích použití tetranukleotidů lze použít k identifikaci genů (nebo metagenomických čtení) pocházejících ze specifických stanovišť. Navíc některé metody jako TriageTools[62] nebo porovnává[63] detekovat podobná čtení mezi dvěma sadami čtení. The opatření podobnosti platí při čtení je založeno na řadě identických slov délky k sdílené dvojicemi čtení.
Klíčovým cílem srovnávací metagenomiky je identifikovat mikrobiální skupiny, které jsou odpovědné za propůjčení konkrétních charakteristik danému prostředí. Kvůli problémům se sekvenčními technologiemi je však třeba počítat s artefakty jako v metagenomeSeq.[30] Jiní charakterizovali inter-mikrobiální interakce mezi rezidentními mikrobiálními skupinami. A GUI Kuntal a kol. vyvinuli aplikaci pro komparativní metagenomickou analýzu založenou na komunitě nazvanou Community-Analyzer. [64] který implementuje algoritmus rozložení grafů založený na korelaci, který nejen usnadňuje rychlou vizualizaci rozdílů v analyzovaných mikrobiálních společenstvích (z hlediska jejich taxonomického složení), ale také poskytuje vhled do v nich se vyskytujících inter-mikrobiálních interakcí. Je pozoruhodné, že tento algoritmus rozložení také umožňuje seskupení metagenomů na základě pravděpodobných vzorců inter-mikrobiální interakce, spíše než pouhé srovnání hodnot hojnosti různých taxonomických skupin. Nástroj navíc implementuje několik interaktivních funkcí založených na grafickém uživatelském rozhraní, které uživatelům umožňují provádět standardní srovnávací analýzy napříč mikrobiomy.
Analýza dat
Komunitní metabolismus
V mnoha bakteriálních komunitách, přírodních nebo umělých (např bioreaktory ), existuje významná dělba práce v metabolismu (Syntrofie ), během nichž jsou odpadní produkty některých organismů metabolity pro jiné.[65] V jednom takovém systému je methanogenní bioreaktor, funkční stabilita vyžaduje přítomnost několika syntrofický druh (Syntrophobacterales a Synergistia ) spolupracujeme na přeměně surovin na plně metabolizovaný odpad (metan ).[66] Využití srovnávacích genových studií a experimentů s expresí s mikročipy nebo proteomika vědci mohou sestavit metabolickou síť, která přesahuje hranice druhů. Takové studie vyžadují podrobné znalosti o tom, které verze bílkovin jsou kódovány, které druhy a dokonce i které kmeny jakého druhu. Proto jsou komunitní genomové informace dalším základním nástrojem (s metabolomika a proteomika) ve snaze určit, jak jsou metabolity komunitou přenášeny a transformovány.[67]
Metatranscriptomics
Metagenomika umožňuje vědcům přístup k funkční a metabolické rozmanitosti mikrobiálních komunit, ale nemůže ukázat, které z těchto procesů jsou aktivní.[59] Extrakce a analýza metagenomických mRNA (dále jen metatranscriptome) poskytuje informace o nařízení a výraz profily složitých komunit. Z důvodu technických potíží ( krátký poločas například mRNA) ve sběru environmentální RNA bylo relativně málo in situ metatranskriptomické studie mikrobiálních komunit k dnešnímu dni.[59] Zatímco původně omezeno na microarray technologie, metatranscriptomics studie využily transkriptomické technologie měřit expresi celého genomu a kvantifikaci mikrobiální komunity,[59] poprvé použit při analýze oxidace amoniaku v půdě.[68]
Viry
Metagenomické sekvenování je zvláště užitečné při studiu virových komunit. Protože virům chybí společný univerzální fylogenetický marker (jako 16S RNA pro bakterie a archea a 18S RNA pro eukarya), jediný způsob, jak získat přístup ke genetické rozmanitosti virové komunity ze vzorku prostředí, je prostřednictvím metagenomiky. Virové metagenomy (nazývané také viromy) by tedy měly poskytovat stále více informací o virové rozmanitosti a evoluci.[69][70][71][72][73] Například metagenomický plynovod s názvem Giant Virus Finder ukázal první důkaz o existenci obří viry ve slané poušti[74] a v antarktických suchých údolích.[75]
Aplikace
Metagenomika má potenciál rozvíjet znalosti v nejrůznějších oborech. Lze jej také použít k řešení praktických výzev v EU lék, inženýrství, zemědělství, udržitelnost a ekologie.[31][76]
Zemědělství
The půdy ve kterých rostliny rostou, jsou obývány mikrobiálními společenstvími, přičemž jeden gram půdy obsahuje asi 109-1010 mikrobiální buňky, které obsahují přibližně jednu gigabázu sekvenční informace.[77][78] Mikrobiální společenství, která obývají půdy, jsou jedny z nejsložitějších vědeckých poznatků a zůstávají i přes jejich ekonomický význam stále nepochopena.[79] Mikrobiální konsorcia provádějí širokou škálu ekosystémové služby nezbytné pro růst rostlin, včetně fixace atmosférického dusíku, koloběh živin, potlačení nemoci a sekvestr žehlička a další kovy.[80] Funkční metagenomické strategie se používají k prozkoumání interakcí mezi rostlinami a mikroby prostřednictvím kultivace nezávislých studií těchto mikrobiálních společenstev.[81][82] Umožněním nahlédnutí do role dříve nekultivovaných nebo vzácných členů komunity při koloběhu živin a podpoře růstu rostlin mohou metagenomické přístupy přispět ke zlepšení detekce nemocí v plodiny a hospodářská zvířata a přizpůsobení vylepšeného zemědělství postupy, které zlepšují zdraví plodin využitím vztahu mezi mikroby a rostlinami.[31]
Biopalivo
Biopaliva jsou paliva odvozený od biomasa konverze, jako při konverzi celulóza obsaženo v kukuřice stonky, trávník a další biomasu do celulózový ethanol.[31] Tento proces je závislý na mikrobiálních konsorciích (asociacích), které transformují celulózu na cukry, následovaný kvašení cukrů do ethanol. Mikroby také produkují řadu zdrojů bioenergie počítaje v to metan a vodík.[31]
The efektivní průmyslová dekonstrukce biomasy vyžaduje román enzymy s vyšší produktivitou a nižšími náklady.[28] Metagenomické přístupy k analýze komplexních mikrobiálních komunit umožňují cílené promítání z enzymy s průmyslovými aplikacemi při výrobě biopaliv, jako např glykosidové hydrolázy.[83] Kromě toho je pro jejich ovládání nutná znalost fungování těchto mikrobiálních komunit a metagenomika je klíčovým nástrojem jejich porozumění. Metagenomické přístupy umožňují srovnávací analýzy mezi konvergentní mikrobiální systémy jako bioplyn fermentory[84] nebo hmyz býložravci tak jako houba zahrada z mravenci.[85]
Biotechnologie
Mikrobiální společenství produkují obrovské množství biologicky aktivních chemikálií, které se používají v soutěži a komunikaci.[80] Mnoho dnes používaných drog bylo původně odkryto v mikrobech; nedávný pokrok v těžbě bohatého genetického zdroje nekultivovatelných mikrobů vedl k objevení nových genů, enzymů a přírodních produktů.[59][86] Aplikace metagenomiky umožnila vývoj zboží a jemné chemikálie, agrochemikálie a léčiva kde je výhoda enzymem katalyzovaný chirální syntéza je stále více uznávána.[87]
V analýze se používají dva typy analýz bioprozkoumávání metagenomických dat: screening řízený funkcí pro vyjádřený znak a sekvenční screening sledovaných sekvencí DNA.[88] Funkčně řízená analýza usiluje o identifikaci klonů exprimujících požadovaný znak nebo užitečnou aktivitu, následovaná biochemickou charakterizací a sekvenční analýzou. Tento přístup je omezen dostupností vhodné obrazovky a požadavkem, aby byl požadovaný znak vyjádřen v hostitelské buňce. Nízká míra objevu (méně než jeden na 1 000 vyšetřovaných klonů) a jeho pracovně náročná povaha tento přístup dále omezují.[89] Naproti tomu používá sekvenčně řízená analýza konzervované sekvence DNA na design PCR primerů k screeningu klonů na sledovanou sekvenci.[88] Ve srovnání s přístupy založenými na klonování použití přístupu založeného pouze na sekvenci dále snižuje množství požadované práce na stole. Aplikace masivně paralelního sekvenování také výrazně zvyšuje množství generovaných sekvenčních dat, která vyžadují vysoce výkonné kanály bioinformatické analýzy.[89] Sekvenčně řízený přístup k screeningu je omezen šířkou a přesností genových funkcí přítomných ve veřejných databázích sekvencí. V praxi experimenty využívají kombinaci funkčních i sekvenčních přístupů založených na sledované funkci, složitosti testovaného vzorku a dalších faktorech.[89][90] Příklad úspěchu při používání metagenomiky jako biotechnologie pro objevování léků je ilustrován na malacidin antibiotika.[91]
Ekologie

Metagenomika může poskytnout cenné poznatky o funkční ekologii environmentálních komunit.[92] Metagenomická analýza bakteriálních konsorcií nalezených v defekacích australských lachtanů naznačuje, že výkaly lachtanů bohatých na živiny mohou být důležitým zdrojem živin pro pobřežní ekosystémy. Je to proto, že bakterie, které jsou vylučovány současně s defekacemi, jsou schopny rozkládat živiny ve stolici na biologicky dostupnou formu, která může být přijata do potravinového řetězce.[93]
Sekvenování DNA lze také použít v širším smyslu k identifikaci druhů přítomných ve vodě,[94] nečistoty odfiltrované ze vzduchu nebo vzorky nečistot. Tím lze stanovit rozsah invazivní druhy a ohrožené druhy a sledovat sezónní populace.
Sanace životního prostředí
Metagenomika může zlepšit strategie pro sledování dopadu znečišťující látky na ekosystémy a pro čištění kontaminovaného prostředí. Lepší porozumění tomu, jak se mikrobiální společenství vyrovnávají se znečišťujícími látkami, zlepšuje hodnocení potenciálu kontaminovaných lokalit zotavit se ze znečištění a zvyšuje šance na bioaugmentace nebo biostimulace pokusy uspět.[95]
Charakterizace střevních mikrobů
Mikrobiální společenství hrají klíčovou roli při ochraně člověka zdraví, ale jejich složení a mechanismus, kterým to dělají, zůstává záhadné.[96] Metagenomické sekvenování se používá k charakterizaci mikrobiálních komunit z 15–18 míst těla od nejméně 250 jedinců. Toto je součást Iniciativa pro lidský mikrobiom s primárními cíli zjistit, zda existuje jádro lidský mikrobiom, porozumět změnám v lidském mikrobiomu, které lze korelovat s lidským zdravím, a vyvinout nové technologické a bioinformatika nástroje na podporu těchto cílů.[97]
Další lékařská studie v rámci projektu MetaHit (Metagenomics of the Human Intestinal Tract) sestávala ze 124 jedinců z Dánska a Španělska, kteří se skládali ze zdravých pacientů s nadváhou a podrážděnými střevními chorobami. Studie se pokusila kategorizovat hloubku a fylogenetickou rozmanitost gastrointestinálních bakterií. Pomocí dat sekvence Illumina GA a SOAPdenovo, grafického nástroje de Bruijn, který byl speciálně navržen pro krátká čtení sestav, byli schopni generovat 6,58 milionu kontigů větších než 500 bp pro celkovou délku kontig 10,3 Gb a délku N50 2,2 kb.
Studie prokázala, že dvě bakteriální divize, Bacteroidetes a Firmicutes, tvoří více než 90% známých fylogenetických kategorií, které dominují ve vzdálených střevních bakteriích. Pomocí relativních genových frekvencí nalezených ve střevě tito vědci identifikovali 1244 metagenomických klastrů, které jsou kriticky důležité pro zdraví střevního traktu. V těchto řadách klastrů existují dva typy funkcí: úklid a funkce specifické pro střevo. Klastry genů pro domácnost jsou vyžadovány u všech bakterií a jsou často hlavními hráči v hlavních metabolických drahách, včetně centrálního metabolismu uhlíku a syntézy aminokyselin. Mezi funkce specifické pro střeva patří adheze k hostitelským proteinům a sběr cukrů z globosérie glykolipidů. Ukázalo se, že pacienti se syndromem dráždivého tračníku vykazují o 25% méně genů a nižší bakteriální diverzitu než jedinci netrpící syndromem dráždivého tračníku, což naznačuje, že s tímto stavem mohou souviset změny v rozmanitosti střevního biomu pacientů.
Zatímco tyto studie zdůrazňují některé potenciálně cenné lékařské aplikace, pouze 31–48,8% naměřených hodnot mohlo být srovnáno se 194 veřejnými bakteriálními genomy lidského střeva a 7,6–21,2% s bakteriálními genomy dostupnými v GenBank, což naznačuje, že je stále zapotřebí mnohem více výzkumu zachytit nové bakteriální genomy.[98]
Diagnostika infekčních nemocí
Rozlišování mezi infekčním a neinfekčním onemocněním a identifikace základní etiologie infekce může být docela náročné. Například více než polovina případů encefalitida zůstávají nediagnostikovaní, a to navzdory rozsáhlému testování pomocí nejmodernějších klinických laboratorních metod. Metagenomické sekvenování je slibné jako citlivá a rychlá metoda diagnostiky infekce porovnáním genetického materiálu nalezeného ve vzorku pacienta s databází tisíců bakterií, virů a dalších patogenů
Viz také
Reference
- ^ A b C d E F G Wooley JC, Godzik A, Friedberg I (únor 2010). Bourne PE (ed.). „Základní nátěr na metagenomiku“. PLOS výpočetní biologie. 6 (2): e1000667. Bibcode:2010PLSCB ... 6E0667W. doi:10.1371 / journal.pcbi.1000667. PMC 2829047. PMID 20195499.
- ^ A b Hugenholtz P, Goebel BM, Pace NR (září 1998). „Dopad studií nezávislých na kultuře na vznikající fylogenetický pohled na bakteriální rozmanitost“. Journal of Bacteriology. 180 (18): 4765–74. doi:10.1128 / JB.180.18.4765-4774.1998. PMC 107498. PMID 9733676.
- ^ Marco, D, vyd. (2011). Metagenomika: současné inovace a budoucí trendy. Caister Academic Press. ISBN 978-1-904455-87-5.
- ^ Eisen JA (březen 2007). „Environmentální brokovnice: její potenciál a výzvy pro studium skrytého světa mikrobů“. PLOS Biology. 5 (3): e82. doi:10.1371 / journal.pbio.0050082. PMC 1821061. PMID 17355177.
- ^ Handelsman J, Rondon MR, Brady SF, Clardy J, Goodman RM (říjen 1998). „Molekulárně biologický přístup k chemii neznámých půdních mikrobů: nová hranice pro přírodní produkty“. Chemie a biologie. 5 (10): R245-9. doi:10.1016 / S1074-5521 (98) 90108-9. PMID 9818143..
- ^ Chen K, Pachter L (červenec 2005). „Bioinformatika pro sekvenování brokovnic v celém genomu mikrobiálních komunit“. PLOS výpočetní biologie. 1 (2): 106–12. Bibcode:2005PLSCB ... 1 ... 24C. doi:10,1371 / journal.pcbi.0010024. PMC 1185649. PMID 16110337.
- ^ Lane DJ, Pace B, Olsen GJ, Stahl DA, Sogin ML, Pace NR (October 1985). "Rapid determination of 16S ribosomal RNA sequences for phylogenetic analyses". Sborník Národní akademie věd Spojených států amerických. 82 (20): 6955–9. Bibcode:1985PNAS...82.6955L. doi:10.1073/pnas.82.20.6955. PMC 391288. PMID 2413450.
- ^ Pace NR, Stahl DA, Lane DJ, Olsen GJ (1986). "The Analysis of Natural Microbial Populations by Ribosomal RNA Sequences". In Marshall KC (ed.). Pokroky v mikrobiální ekologii. 9. Springer USA. s. 1–55. doi:10.1007/978-1-4757-0611-6_1. ISBN 978-1-4757-0611-6.
- ^ Schmidt TM, DeLong EF, Pace NR (July 1991). "Analysis of a marine picoplankton community by 16S rRNA gene cloning and sequencing". Journal of Bacteriology. 173 (14): 4371–8. doi:10.1128/jb.173.14.4371-4378.1991. PMC 208098. PMID 2066334.
- ^ Healy FG, Ray RM, Aldrich HC, Wilkie AC, Ingram LO, Shanmugam KT (1995). "Direct isolation of functional genes encoding cellulases from the microbial consortia in a thermophilic, anaerobic digester maintained on lignocellulose". Aplikovaná mikrobiologie a biotechnologie. 43 (4): 667–74. doi:10.1007/BF00164771. PMID 7546604. S2CID 31384119.
- ^ Stein JL, Marsh TL, Wu KY, Shizuya H, DeLong EF (February 1996). "Characterization of uncultivated prokaryotes: isolation and analysis of a 40-kilobase-pair genome fragment from a planktonic marine archaeon". Journal of Bacteriology. 178 (3): 591–9. doi:10.1128/jb.178.3.591-599.1996. PMC 177699. PMID 8550487.
- ^ Breitbart M, Salamon P, Andresen B, Mahaffy JM, Segall AM, Mead D, et al. (Říjen 2002). „Genomická analýza nekulturních mořských virových komunit“. Sborník Národní akademie věd Spojených států amerických. 99 (22): 14250–5. Bibcode:2002PNAS ... 9914250B. doi:10.1073 / pnas.202488399. PMC 137870. PMID 12384570.
- ^ A b Tyson GW, Chapman J, Hugenholtz P, Allen EE, Ram RJ, Richardson PM, et al. (Březen 2004). "Community structure and metabolism through reconstruction of microbial genomes from the environment". Příroda. 428 (6978): 37–43. Bibcode:2004Natur.428...37T. doi:10.1038/nature02340. PMID 14961025. S2CID 4420754.(vyžadováno předplatné)
- ^ Hugenholtz P (2002). "Exploring prokaryotic diversity in the genomic era". Genome Biology. 3 (2): REVIEWS0003. doi:10.1186/gb-2002-3-2-reviews0003. PMC 139013. PMID 11864374.
- ^ Venter JC, Remington K, Heidelberg JF, Halpern AL, Rusch D, Eisen JA, et al. (Duben 2004). „Sekvenování brokovnice environmentálního genomu Sargasového moře“. Věda. 304 (5667): 66–74. Bibcode:2004Sci ... 304 ... 66V. CiteSeerX 10.1.1.124.1840. doi:10.1126 / science.1093857. PMID 15001713. S2CID 1454587.
- ^ Yooseph S, Nealson KH, Rusch DB, McCrow JP, Dupont CL, Kim M, et al. (Listopad 2010). "Genomic and functional adaptation in surface ocean planktonic prokaryotes". Příroda. 468 (7320): 60–6. Bibcode:2010Natur.468...60Y. doi:10.1038/nature09530. PMID 21048761.(vyžadováno předplatné)
- ^ A b C Poinar HN, Schwarz C, Qi J, Shapiro B, Macphee RD, Buigues B, et al. (Leden 2006). "Metagenomics to paleogenomics: large-scale sequencing of mammoth DNA". Věda. 311 (5759): 392–4. Bibcode:2006Sci...311..392P. doi:10.1126/science.1123360. PMID 16368896. S2CID 11238470.
- ^ Edwards RA, Rodriguez-Brito B, Wegley L, Haynes M, Breitbart M, Peterson DM, et al. (Březen 2006). „Použití pyrosekvenování k objasnění mikrobiální ekologie hlubinných dolů“. BMC Genomics. 7: 57. doi:10.1186/1471-2164-7-57. PMC 1483832. PMID 16549033.
- ^ Thomas T, Gilbert J, Meyer F (February 2012). "Metagenomics - a guide from sampling to data analysis". Mikrobiální informatika a experimentování. 2 (1): 3. doi:10.1186/2042-5783-2-3. PMC 3351745. PMID 22587947.
- ^ Béjà O, Suzuki MT, Koonin EV, Aravind L, Hadd A, Nguyen LP, et al. (Říjen 2000). "Construction and analysis of bacterial artificial chromosome libraries from a marine microbial assemblage". Mikrobiologie prostředí. 2 (5): 516–29. doi:10.1046/j.1462-2920.2000.00133.x. PMID 11233160. S2CID 8267748.
- ^ A b Segata N, Boernigen D, Tickle TL, Morgan XC, Garrett WS, Huttenhower C (May 2013). "Computational meta'omics for microbial community studies". Molekulární systémy biologie. 9 (666): 666. doi:10.1038/msb.2013.22. PMC 4039370. PMID 23670539.
- ^ Rodrigue S, Materna AC, Timberlake SC, Blackburn MC, Malmstrom RR, Alm EJ, Chisholm SW (July 2010). Gilbert JA (ed.). "Unlocking short read sequencing for metagenomics". PLOS ONE. 5 (7): e11840. Bibcode:2010PLoSO...511840R. doi:10.1371/journal.pone.0011840. PMC 2911387. PMID 20676378.
- ^ Schuster SC (January 2008). "Next-generation sequencing transforms today's biology". Přírodní metody. 5 (1): 16–8. doi:10.1038/nmeth1156. PMID 18165802. S2CID 1465786.
- ^ "Metagenomics versus Moore's law". Přírodní metody. 6 (9): 623. 2009. doi:10.1038/nmeth0909-623.
- ^ Stewart RD, Auffret MD, Warr A, Wiser AH, Press MO, Langford KW, et al. (Únor 2018). "Assembly of 913 microbial genomes from metagenomic sequencing of the cow rumen". Příroda komunikace. 9 (1): 870. Bibcode:2018NatCo...9..870S. doi:10.1038/s41467-018-03317-6. PMC 5830445. PMID 29491419.
- ^ Hiraoka S, Yang CC, Iwasaki W (September 2016). "Metagenomics and Bioinformatics in Microbial Ecology: Current Status and Beyond". Mikroby a prostředí. 31 (3): 204–12. doi:10.1264/jsme2.ME16024. PMC 5017796. PMID 27383682.
- ^ Pérez-Cobas AE, Gomez-Valero L, Buchrieser C (2020). "Metagenomic approaches in microbial ecology: an update on whole-genome and marker gene sequencing analyses". Mikrobiální genomika. 6 (8). doi:10.1099/mgen.0.000409. PMID 32706331.
- ^ A b Hess M, Sczyrba A, Egan R, Kim TW, Chokhawala H, Schroth G, et al. (Leden 2011). "Metagenomic discovery of biomass-degrading genes and genomes from cow rumen". Věda. 331 (6016): 463–7. Bibcode:2011Sci...331..463H. doi:10.1126/science.1200387. PMID 21273488. S2CID 36572885.
- ^ Qin J, Li R, Raes J, Arumugam M, Burgdorf KS, Manichanh C, et al. (Březen 2010). „Katalog lidského střevního mikrobiálního genu vytvořený metagenomickým sekvenováním“. Příroda. 464 (7285): 59–65. Bibcode:2010Natur.464 ... 59.. doi:10.1038 / nature08821. PMC 3779803. PMID 20203603.(vyžadováno předplatné)
- ^ A b Paulson JN, Stine OC, Bravo HC, Pop M (December 2013). "Differential abundance analysis for microbial marker-gene surveys". Přírodní metody. 10 (12): 1200–2. doi:10.1038/nmeth.2658. PMC 4010126. PMID 24076764.
- ^ A b C d E F G Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). The New Science of Metagenomics: Revealing the Secrets of Our Microbial Planet. Washington, DC: Národní akademie Press. doi:10.17226/11902. ISBN 978-0-309-10676-4. PMID 21678629.
- ^ Oulas A, Pavloudi C, Polymenakou P, Pavlopoulos GA, Papanikolaou N, Kotoulas G, et al. (2015). "Metagenomics: tools and insights for analyzing next-generation sequencing data derived from biodiversity studies". Bioinformatics and Biology Insights. 9: 75–88. doi:10.4137/BBI.S12462. PMC 4426941. PMID 25983555.
- ^ Mende DR, Waller AS, Sunagawa S, Järvelin AI, Chan MM, Arumugam M, et al. (23 February 2012). "Assessment of metagenomic assembly using simulated next generation sequencing data". PLOS ONE. 7 (2): e31386. Bibcode:2012PLoSO...731386M. doi:10.1371/journal.pone.0031386. PMC 3285633. PMID 22384016.
- ^ Balzer S, Malde K, Grohme MA, Jonassen I (April 2013). "Filtering duplicate reads from 454 pyrosequencing data". Bioinformatika. 29 (7): 830–6. doi:10.1093/bioinformatics/btt047. PMC 3605598. PMID 23376350.
- ^ Mohammed MH, Chadaram S, Komanduri D, Ghosh TS, Mande SS (September 2011). "Eu-Detect: an algorithm for detecting eukaryotic sequences in metagenomic data sets". Journal of Biosciences. 36 (4): 709–17. doi:10.1007/s12038-011-9105-2. PMID 21857117. S2CID 25857874.
- ^ Schmieder R, Edwards R (March 2011). "Fast identification and removal of sequence contamination from genomic and metagenomic datasets". PLOS ONE. 6 (3): e17288. Bibcode:2011PLoSO...617288S. doi:10.1371/journal.pone.0017288. PMC 3052304. PMID 21408061.
- ^ A b C d E Kunin V, Copeland A, Lapidus A, Mavromatis K, Hugenholtz P (December 2008). "A bioinformatician's guide to metagenomics". Recenze mikrobiologie a molekulární biologie. 72 (4): 557–78, Table of Contents. doi:10.1128/MMBR.00009-08. PMC 2593568. PMID 19052320.
- ^ Namiki T, Hachiya T, Tanaka H, Sakakibara Y (November 2012). "MetaVelvet: an extension of Velvet assembler to de novo metagenome assembly from short sequence reads". Výzkum nukleových kyselin. 40 (20): e155. doi:10.1093/nar/gks678. PMC 3488206. PMID 22821567.
- ^ Zerbino DR, Birney E (May 2008). "Velvet: algorithms for de novo short read assembly using de Bruijn graphs". Výzkum genomu. 18 (5): 821–9. doi:10.1101 / gr.074492.107. PMC 2336801. PMID 18349386.
- ^ Burton JN, Liachko I, Dunham MJ, Shendure J (May 2014). "Species-level deconvolution of metagenome assemblies with Hi-C-based contact probability maps". G3. 4 (7): 1339–46. doi:10.1534/g3.114.011825. PMC 4455782. PMID 24855317.
- ^ A b Huson DH, Mitra S, Ruscheweyh HJ, Weber N, Schuster SC (září 2011). „Integrativní analýza sekvencí prostředí pomocí MEGAN4“. Výzkum genomu. 21 (9): 1552–60. doi:10,1101 / gr. 120618.111. PMC 3166839. PMID 21690186.
- ^ Zhu W, Lomsadze A, Borodovsky M (červenec 2010). "Identifikace genu Ab initio v metagenomických sekvencích". Výzkum nukleových kyselin. 38 (12): e132. doi:10.1093 / nar / gkq275. PMC 2896542. PMID 20403810.
- ^ Konopka A (November 2009). „Co je to ekologie mikrobiální komunity?“. Časopis ISME. 3 (11): 1223–30. doi:10.1038 / ismej.2009.88. PMID 19657372.
- ^ A b Huson DH, Auch AF, Qi J, Schuster SC (March 2007). "MEGAN analysis of metagenomic data". Výzkum genomu. 17 (3): 377–86. doi:10,1101 / gr. 5969107. PMC 1800929. PMID 17255551.
- ^ Segata N, Waldron L, Ballarini A, Narasimhan V, Jousson O, Huttenhower C (June 2012). "Metagenomic microbial community profiling using unique clade-specific marker genes". Přírodní metody. 9 (8): 811–4. doi:10.1038/nmeth.2066. PMC 3443552. PMID 22688413.
- ^ Sunagawa S, Mende DR, Zeller G, Izquierdo-Carrasco F, Berger SA, Kultima JR, et al. (Prosinec 2013). "Metagenomic species profiling using universal phylogenetic marker genes". Přírodní metody. 10 (12): 1196–9. doi:10.1038/nmeth.2693. PMID 24141494. S2CID 7728395.
- ^ A b Milanese A, Mende DR, Paoli L, Salazar G, Ruscheweyh HJ, Cuenca M, et al. (Březen 2019). "Microbial abundance, activity and population genomic profiling with mOTUs2". Příroda komunikace. 10 (1): 1014. Bibcode:2019NatCo..10.1014M. doi:10.1038/s41467-019-08844-4. PMC 6399450. PMID 30833550.
- ^ Liu B, Gibbons T, Ghodsi M, Treangen T, Pop M (2011). "Accurate and fast estimation of taxonomic profiles from metagenomic shotgun sequences". BMC Genomics. 12 Suppl 2: S4. doi:10.1186/1471-2164-12-S2-S4. PMC 3194235. PMID 21989143.
- ^ Dadi TH, Renard BY, Wieler LH, Semmler T, Reinert K (2017). "SLIMM: species level identification of microorganisms from metagenomes". PeerJ. 5: e3138. doi:10.7717/peerj.3138. PMC 5372838. PMID 28367376.
- ^ Pagani I, Liolios K, Jansson J, Chen IM, Smirnova T, Nosrat B, et al. (Leden 2012). „The Genomes OnLine Database (GOLD) v.4: status of genomic and metagenomic projects and their associated metadata“. Výzkum nukleových kyselin. 40 (Database issue): D571-9. doi:10.1093 / nar / gkr1100. PMC 3245063. PMID 22135293.
- ^ Meyer F, Paarmann D, D'Souza M, Olson R, Glass EM, Kubal M, et al. (Září 2008). "The metagenomics RAST server - a public resource for the automatic phylogenetic and functional analysis of metagenomes". BMC bioinformatika. 9: 386. doi:10.1186/1471-2105-9-386. PMC 2563014. PMID 18803844.
- ^ Markowitz VM, Chen IM, Chu K, Szeto E, Palaniappan K, Grechkin Y, et al. (Leden 2012). "IMG/M: the integrated metagenome data management and comparative analysis system". Výzkum nukleových kyselin. 40 (Database issue): D123-9. doi:10.1093/nar/gkr975. PMC 3245048. PMID 22086953.
- ^ A b Mitra S, Rupek P, Richter DC, Urich T, Gilbert JA, Meyer F, et al. (Únor 2011). "Functional analysis of metagenomes and metatranscriptomes using SEED and KEGG". BMC bioinformatika. 12 Suppl 1: S21. doi:10.1186/1471-2105-12-S1-S21. PMC 3044276. PMID 21342551.
- ^ Benson DA, Cavanaugh M, Clark K, Karsch-Mizrachi I, Lipman DJ, Ostell J, Sayers EW (January 2013). „GenBank“. Výzkum nukleových kyselin. 41 (Database issue): D36-42. doi:10.1093 / nar / gks1195. PMC 3531190. PMID 23193287.
- ^ Bazinet AL, Cummings MP (May 2012). "A comparative evaluation of sequence classification programs". BMC bioinformatika. 13: 92. doi:10.1186/1471-2105-13-92. PMC 3428669. PMID 22574964.
- ^ Ounit R, Wanamaker S, Close TJ, Lonardi S (March 2015). "CLARK: fast and accurate classification of metagenomic and genomic sequences using discriminative k-mers". BMC Genomics. 16: 236. doi:10.1186/s12864-015-1419-2. PMC 4428112. PMID 25879410.
- ^ Pratas D, Pinho AJ, Silva RM, Rodrigues JM, Hosseini M, Caetano T, Ferreira PJ (únor 2018). "FALCON: a method to infer metagenomic composition of ancient DNA". bioRxiv 10.1101/267179.
- ^ Kurokawa K, Itoh T, Kuwahara T, Oshima K, Toh H, Toyoda A, et al. (Srpen 2007). "Comparative metagenomics revealed commonly enriched gene sets in human gut microbiomes". Výzkum DNA. 14 (4): 169–81. doi:10.1093/dnares/dsm018. PMC 2533590. PMID 17916580.
- ^ A b C d E F Simon C, Daniel R (February 2011). "Metagenomic analyses: past and future trends". Aplikovaná a environmentální mikrobiologie. 77 (4): 1153–61. doi:10.1128/AEM.02345-10. PMC 3067235. PMID 21169428.
- ^ Willner D, Thurber RV, Rohwer F (July 2009). "Metagenomic signatures of 86 microbial and viral metagenomes". Mikrobiologie prostředí. 11 (7): 1752–66. doi:10.1111/j.1462-2920.2009.01901.x. PMID 19302541.
- ^ Ghosh TS, Mohammed MH, Rajasingh H, Chadaram S, Mande SS (2011). "HabiSign: a novel approach for comparison of metagenomes and rapid identification of habitat-specific sequences". BMC bioinformatika. 12 Suppl 13 (Supplement 13): S9. doi:10.1186/1471-2105-12-s13-s9. PMC 3278849. PMID 22373355.
- ^ Fimereli D, Detours V, Konopka T (April 2013). "TriageTools: tools for partitioning and prioritizing analysis of high-throughput sequencing data". Výzkum nukleových kyselin. 41 (7): e86. doi:10.1093/nar/gkt094. PMC 3627586. PMID 23408855.
- ^ Maillet N, Lemaitre C, Chikhi R, Lavenier D, Peterlongo P (2012). "Compareads: comparing huge metagenomic experiments". BMC bioinformatika. 13 Suppl 19 (Suppl 19): S10. doi:10.1186/1471-2105-13-S19-S10. PMC 3526429. PMID 23282463.
- ^ Kuntal BK, Ghosh TS, Mande SS (October 2013). "Community-analyzer: a platform for visualizing and comparing microbial community structure across microbiomes". Genomika. 102 (4): 409–18. doi:10.1016/j.ygeno.2013.08.004. PMID 23978768.
- ^ Werner JJ, Knights D, Garcia ML, Scalfone NB, Smith S, Yarasheski K, et al. (Březen 2011). "Bacterial community structures are unique and resilient in full-scale bioenergy systems". Sborník Národní akademie věd Spojených států amerických. 108 (10): 4158–63. Bibcode:2011PNAS..108.4158W. doi:10.1073/pnas.1015676108. PMC 3053989. PMID 21368115.
- ^ McInerney MJ, Sieber JR, Gunsalus RP (December 2009). "Syntrophy in anaerobic global carbon cycles". Aktuální názor na biotechnologie. 20 (6): 623–32. doi:10.1016/j.copbio.2009.10.001. PMC 2790021. PMID 19897353.
- ^ Klitgord N, Segrè D (August 2011). "Ecosystems biology of microbial metabolism". Aktuální názor na biotechnologie. 22 (4): 541–6. doi:10.1016/j.copbio.2011.04.018. PMID 21592777.
- ^ Leininger S, Urich T, Schloter M, Schwark L, Qi J, Nicol GW, et al. (Srpen 2006). „Archaea převládají mezi prokaryoty oxidujícími amoniak v půdě“. Příroda. 442 (7104): 806–9. Bibcode:2006 Natur.442..806L. doi:10.1038 / nature04983. PMID 16915287. S2CID 4380804.
- ^ Paez-Espino D, Eloe-Fadrosh EA, Pavlopoulos GA, Thomas AD, Huntemann M, Mikhailova N, et al. (Srpen 2016). „Odhalení viromu Země“. Příroda. 536 (7617): 425–30. Bibcode:2016Natur.536..425P. doi:10.1038 / příroda1994. PMID 27533034. S2CID 4466854.
- ^ Paez-Espino D, Chen IA, Palaniappan K, Ratner A, Chu K, Szeto E a kol. (Leden 2017). „IMG / VR: databáze kultivovaných a nekulturních DNA virů a retrovirů“. Výzkum nukleových kyselin. 45 (D1): D457 – D465. doi:10.1093 / nar / gkw1030. PMC 5210529. PMID 27799466.
- ^ Paez-Espino D, Roux S, Chen IA, Palaniappan K, Ratner A, Chu K a kol. (Leden 2019). „IMG / VR v.2.0: integrovaný systém správy a analýzy dat pro kultivované a environmentální virové genomy“. Výzkum nukleových kyselin. 47 (D1): D678–D686. doi:10.1093 / nar / gky1127. PMC 6323928. PMID 30407573.
- ^ Paez-Espino D, Pavlopoulos GA, Ivanova NN, Kyrpides NC (srpen 2017). „Kanál zjišťování necílených virových sekvencí a shlukování virů pro metagenomická data“ (PDF). Přírodní protokoly. 12 (8): 1673–1682. doi:10.1038 / nprot.2017.063. PMID 28749930. S2CID 2127494.
- ^ Kristensen DM, Mushegian AR, Dolja VV, Koonin EV (January 2010). "New dimensions of the virus world discovered through metagenomics". Trendy v mikrobiologii. 18 (1): 11–9. doi:10.1016/j.tim.2009.11.003. PMC 3293453. PMID 19942437.
- ^ Kerepesi C, Grolmusz V (March 2016). "Giant viruses of the Kutch Desert". Archivy virologie. 161 (3): 721–4. arXiv:1410.1278. doi:10.1007 / s00705-015-2720-8. PMID 26666442. S2CID 13145926.
- ^ Kerepesi C, Grolmusz V (June 2017). "The "Giant Virus Finder" discovers an abundance of giant viruses in the Antarctic dry valleys". Archivy virologie. 162 (6): 1671–1676. arXiv:1503.05575. doi:10.1007 / s00705-017-3286-4. PMID 28247094. S2CID 1925728.
- ^ Copeland CS (September–October 2017). "The World Within Us" (PDF). Healthcare Journal of New Orleans: 21–26.
- ^ Jansson J (2011). "Towards "Tera-Terra": Terabase Sequencing of Terrestrial Metagenomes Print E-mail". Mikrob. 6 (7). str. 309. Archived from originál dne 31. března 2012.
- ^ Vogel TM, Simonet P, Jansson JK, Hirsch PR, Tiedje JM, Van Elsas JD, Bailey MJ, Nalin R, Philippot L (2009). "TerraGenome: A consortium for the sequencing of a soil metagenome". Příroda Recenze Mikrobiologie. 7 (4): 252. doi:10.1038/nrmicro2119.
- ^ "TerraGenome Homepage". TerraGenome international sequencing consortium. Citováno 30. prosince 2011.
- ^ A b Committee on Metagenomics: Challenges and Functional Applications, National Research Council (2007). Understanding Our Microbial Planet: The New Science of Metagenomics (PDF). Národní akademie Press.
- ^ Charles T (2010). "The Potential for Investigation of Plant-microbe Interactions Using Metagenomics Methods". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ Bringel F, Couée I (22 May 2015). "Pivotal roles of phyllosphere microorganisms at the interface between plant functioning and atmospheric trace gas dynamics". Hranice v mikrobiologii. 6: 486. doi:10.3389/fmicb.2015.00486. PMC 4440916. PMID 26052316.
- ^ Li LL, McCorkle SR, Monchy S, Taghavi S, van der Lelie D (May 2009). "Bioprospecting metagenomes: glycosyl hydrolases for converting biomass". Biotechnologie pro biopaliva. 2: 10. doi:10.1186/1754-6834-2-10. PMC 2694162. PMID 19450243.
- ^ Jaenicke S, Ander C, Bekel T, Bisdorf R, Dröge M, Gartemann KH, et al. (Leden 2011). Aziz RK (ed.). "Comparative and joint analysis of two metagenomic datasets from a biogas fermenter obtained by 454-pyrosequencing". PLOS ONE. 6 (1): e14519. Bibcode:2011PLoSO...614519J. doi:10.1371/journal.pone.0014519. PMC 3027613. PMID 21297863.
- ^ Suen G, Scott JJ, Aylward FO, Adams SM, Tringe SG, Pinto-Tomás AA, et al. (Září 2010). Sonnenburg J (ed.). "An insect herbivore microbiome with high plant biomass-degrading capacity". Genetika PLOS. 6 (9): e1001129. doi:10.1371/journal.pgen.1001129. PMC 2944797. PMID 20885794.
- ^ Simon C, Daniel R (November 2009). "Achievements and new knowledge unraveled by metagenomic approaches". Aplikovaná mikrobiologie a biotechnologie. 85 (2): 265–76. doi:10.1007/s00253-009-2233-z. PMC 2773367. PMID 19760178.
- ^ Wong D (2010). "Applications of Metagenomics for Industrial Bioproducts". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ A b Schloss PD, Handelsman J (June 2003). "Biotechnological prospects from metagenomics" (PDF). Aktuální názor na biotechnologie. 14 (3): 303–10. doi:10.1016/S0958-1669(03)00067-3. PMID 12849784. Archivovány od originál (PDF) dne 4. března 2016. Citováno 20. ledna 2012.
- ^ A b C Kakirde KS, Parsley LC, Liles MR (November 2010). "Size Does Matter: Application-driven Approaches for Soil Metagenomics". Soil Biology & Biochemistry. 42 (11): 1911–1923. doi:10.1016/j.soilbio.2010.07.021. PMC 2976544. PMID 21076656.
- ^ Parachin NS, Gorwa-Grauslund MF (May 2011). "Isolation of xylose isomerases by sequence- and function-based screening from a soil metagenomic library". Biotechnologie pro biopaliva. 4 (1): 9. doi:10.1186/1754-6834-4-9. PMC 3113934. PMID 21545702.
- ^ Hover BM, Kim SH, Katz M, Charlop-Powers Z, Owen JG, Ternei MA, et al. (Duben 2018). „Objev malacidinů nezávislých na kultuře jako antibiotik závislých na vápníku s aktivitou proti multirezistentním grampozitivním patogenům“. Přírodní mikrobiologie. 3 (4): 415–422. doi:10.1038 / s41564-018-0110-1. PMC 5874163. PMID 29434326.
- ^ Raes J, Letunic I, Yamada T, Jensen LJ, Bork P (March 2011). "Toward molecular trait-based ecology through integration of biogeochemical, geographical and metagenomic data". Molekulární systémy biologie. 7: 473. doi:10.1038/msb.2011.6. PMC 3094067. PMID 21407210.
- ^ Lavery TJ, Roudnew B, Seymour J, Mitchell JG, Jeffries T (2012). Steinke D (ed.). "High nutrient transport and cycling potential revealed in the microbial metagenome of Australian sea lion (Neophoca cinerea) faeces". PLOS ONE. 7 (5): e36478. Bibcode:2012PLoSO...736478L. doi:10.1371/journal.pone.0036478. PMC 3350522. PMID 22606263.
- ^ "What's Swimming in the River? Just Look For DNA". NPR.org. 24. července 2013. Citováno 10. října 2014.
- ^ George I, Stenuit B, Agathos SN (2010). "Application of Metagenomics to Bioremediation". In Marco D (ed.). Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ Zimmer C (13 July 2010). "How Microbes Defend and Define Us". New York Times. Citováno 29. prosince 2011.
- ^ Nelson KE and White BA (2010). "Metagenomics and Its Applications to the Study of the Human Microbiome". Metagenomics: Theory, Methods and Applications. Caister Academic Press. ISBN 978-1-904455-54-7.
- ^ Qin J, Li R, Raes J, Arumugam M, Burgdorf KS, Manichanh C, et al. (Březen 2010). „Katalog lidského střevního mikrobiálního genu vytvořený metagenomickým sekvenováním“. Příroda. 464 (7285): 59–65. Bibcode:2010Natur.464 ... 59.. doi:10.1038 / nature08821. PMC 3779803. PMID 20203603.
externí odkazy
- Focus on Metagenomics na Příroda Recenze Mikrobiologie web deníku
- The “Critical Assessment of Metagenome Interpretation” (CAMI) initiative to evaluate methods in metagenomics
| Genomika | |
|---|---|
| Bioinformatika | |
| Strukturní biologie | |
| Výzkumné nástroje | |
| Organizace |
|
| |