Identita podle původu - Identity by descent
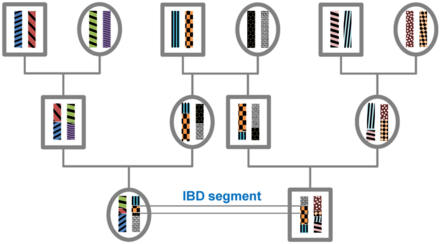
A DNA segment je shodné podle stavu (IBS) u dvou nebo více jedinců, pokud mají identické nukleotidové sekvence v tomto segmentu. Segment IBS je shodné sestupem (IBD) u dvou nebo více jedinců, pokud jej zdědili od společného předka bez rekombinace, to znamená, že segment má u těchto jedinců stejný původ. Segmenty DNA, které jsou IBD, jsou IBS podle definice, ale segmenty, které nejsou IBD, mohou být stále IBS kvůli tomu samému mutace u různých jedinců nebo rekombinací, které nemění segment.

Teorie
Všichni jedinci v konečné populaci jsou příbuzní, pokud jsou sledováni dostatečně dlouho, a proto budou sdílet jejich segmenty genomy IBD. V době redukční dělení buněk segmenty IBD jsou rozděleny rekombinací. Očekávaná délka segmentu IBD proto závisí na počtu generací od poslední společný předek v místě segmentu. Délka segmentů IBD, které jsou výsledkem společného předka n generace v minulosti (tedy zahrnující 2n meióza) je exponenciálně distribuována s průměrem 1 / (2n) Morgans (M).[1] Očekávaný počet segmentů IBD klesá s počtem generací od společného předka v tomto místě. U konkrétního segmentu DNA pravděpodobnost, že bude IBD, klesá jako 2−2n protože v každé meióze je pravděpodobnost přenosu tohoto segmentu 1/2.[2]
Aplikace
Identifikované segmenty IBD lze použít pro širokou škálu účelů. Jak je uvedeno výše, množství (délka a počet) sdílení IBD závisí na rodinných vztazích mezi testovanými jedinci. Jednou z aplikací detekce segmentu IBD je proto kvantifikace příbuznosti.[3][4][5][6] Měření příbuznosti lze použít v forenzní genetika,[7] ale může také zvýšit informace v genetická vazba mapování[3][8] a pomáhají snižovat zaujatost standardními neregistrovanými vztahy asociační studie.[6][9]Další aplikací IBD je imputace genotypu a haplotyp fáze odvození.[10][11][12] Dlouhé sdílené segmenty IBD, které jsou rozděleny podle krátkých oblastí, mohou indikovat chyby fázování.[5][13]:SI
Mapování IBD
Mapování IBD[3] je podobná analýze vazeb, ale lze ji provést bez známého rodokmenu na kohortě nesouvisejících jedinců. Mapování IBD lze považovat za novou formu asociační analýzy, která zvyšuje Napájení mapovat geny nebo genomové oblasti obsahující více variant náchylnosti k vzácným chorobám.[6][14]
Pomocí simulovaných dat, Browning a Thompson ukázaly, že mapování IBD má vyšší sílu než asociační testování, když více vzácných variant v genu přispívá k náchylnosti k onemocnění.[14] Prostřednictvím mapování IBD v celém genomu významný Byly nalezeny regiony v izolovaných populacích i v outbredních populacích, zatímco standardní asociační testy selhaly.[11][15] Houwen a kol. používá sdílení IBD k identifikaci chromozomální polohy genu odpovědného za benigní rekurentní intrahepatální cholestáza v izolované rybářské populaci.[16] Kenny a kol. také použil izolovanou populaci k jemnému mapování signálu nalezeného a genomová asociační studie (GWAS) plazmy rostlinný sterol (PPS), náhradní míra absorpce cholesterolu ze střeva.[17] Francks a kol. byl schopen identifikovat potenciální lokus citlivosti na schizofrenie a bipolární porucha s genotypovými daty vzorků případové kontroly.[18] Lin a kol. našel signální signál celé genomu v datové sadě roztroušená skleróza pacientů.[19] Letouzé a kol. použité vyhledávání IBD zakladatelské mutace v rakovina Vzorky.[20]

IBD v populační genetice
Detekce přírodní výběr v lidském genomu je také možné prostřednictvím detekovaných segmentů IBD. Výběr má obvykle tendenci zvyšovat počet segmentů IBD mezi jednotlivci v populaci. Skenováním oblastí s nadměrným sdílením IBD lze identifikovat oblasti v lidském genomu, které byly pod silnou, velmi nedávnou selekcí.[21][22]
Kromě toho mohou být segmenty IBD užitečné pro měření a identifikaci dalších vlivů na strukturu populace.[6][23][24][25][26] Gusev a kol. ukázal, že segmenty IBD lze použít s dalším modelováním k odhadu demografické historie včetně úzká místa a přísada.[24] S využitím podobných modelů Palamara a kol. a Carmi a kol. rekonstruován demografická historie z Ashkenazi židovský a Keňan Masajové Jednotlivci.[25][26][27] Botigué a kol. zkoumali rozdíly v africkém původu mezi evropskými populacemi.[28] Ralph a Coop použili detekci IBD ke kvantifikaci společného původu různých evropských populací[29] a Gravel et al. Podobně se pokusil vyvodit závěry z genetické historie populací v Americe.[30] Ringbauer a kol. využil geografickou strukturu segmentů IBD k odhadu rozptýlení ve východní Evropě během posledních století.[31] Za použití 1000 genomů data Hochreiter zjistil rozdíly ve sdílení IBD mezi africkými, asijskými a evropskými populacemi, stejně jako segmenty IBD, které jsou sdíleny se starodávnými genomy, jako je neandrtálec nebo Denisova.[13]
Metody a software
Programy pro detekci segmentů IBD u nepříbuzných jedinců:
- RYCHLÝ: Ultrarychlá identita podle detekce sestupu v kohortách v měřítku biobanky pomocí poziční transformace Burrows-Wheeler [32]
- Parente: identifikuje segmenty IBD mezi dvojicemi jedinců v datech bez genotypu[33]
- BEAGLE / fastIBD: najde segmenty IBD mezi páry jedinců v celém genomu SNP data[34]
- BEAGLE / RefinedIBD: najde segmenty IBD ve dvojicích jedinců pomocí hashovací metody a vyhodnotí jejich význam pomocí poměru pravděpodobnosti[35]
- IBDseq: detekuje párové segmenty IBD v sekvenčních datech[36]
- GERMLINE: objevuje v segmentech IBD v lineárním čase ve dvojicích jedinců[5]
- POMLČKA: navazuje na párové segmenty IBD k odvození shluků jedinců, kteří pravděpodobně sdílejí jediný haplotyp[15]
- PINK: je sada nástrojů pro celá asociace genomu a populační analýzy propojení zahrnující metodu pro detekci párového IBD segmentu[6]
- Vztah: odhaduje pravděpodobnost IBD mezi páry jednotlivců na konkrétním místě pomocí SNP[3]
- MCMC_IBDfinder: je založeno na Markovský řetězec Monte Carlo (MCMC) pro hledání segmentů IBD u více jedinců[37]
- IBD-Groupon: detekuje segmenty IBD po skupinách na základě párových vztahů IBD[38]
- HapFABIA: identifikuje velmi krátké segmenty IBD charakterizované vzácnými variantami jako celku sekvenování data současně u více osob[13]
Viz také
- Mapování asociací
- Genetická asociace
- Genetická vazba
- Celomanomová asociační studie
- Totožnost podle typu
- Vazebná nerovnováha
- Populační genetika
Reference
- ^ Browning, S. R. (2008). „Odhad párové identity sestupem z hustých dat genetických markerů v populačním vzorku haplotypů“. Genetika. 178 (4): 2123–2132. doi:10.1534 / genetika.107.084624. PMC 2323802. PMID 18430938.
- ^ Thompson, E. A. (2008). „Proces IBD podél čtyř chromozomů“. Teoretická populační biologie. 73 (3): 369–373. doi:10.1016 / j.tpb.2007.11.011. PMC 2518088. PMID 18282591.
- ^ A b C d Albrechtsen, A .; Sand Korneliussen, T .; Moltke, I .; Van Overseem Hansen, T .; Nielsen, F. C .; Nielsen, R. (2009). "Mapování příbuznosti a oblasti příbuznosti pro data v celém genomu za přítomnosti vazebné nerovnováhy". Genetická epidemiologie. 33 (3): 266–274. doi:10.1002 / gepi.20378. PMID 19025785.
- ^ Browning, S. R .; Browning, B.L. (2010). „Detekce identity s vysokým rozlišením podle původu u nepříbuzných jedinců“. American Journal of Human Genetics. 86 (4): 526–539. doi:10.1016 / j.ajhg.2010.02.021. PMC 2850444. PMID 20303063.
- ^ A b C Gusev, A .; Lowe, J. K .; Stoffel, M .; Daly, M. J .; Altshuler, D .; Breslow, J.L .; Friedman, J. M .; Pe'Er, I. (2008). „Celá populace, mapování skryté příbuznosti v celém genomu“. Výzkum genomu. 19 (2): 318–326. doi:10.1101 / gr.081398.108. PMC 2652213. PMID 18971310.
- ^ A b C d E Purcell, S .; Neale, B .; Todd-Brown, K .; Thomas, L .; Ferreira, M. A. R .; Bender, D .; Maller, J .; Sklar, P .; De Bakker, P. I. W .; Daly, M. J .; Sham, P. C. (2007). „PLINK: Sada nástrojů pro asociaci celého genomu a populační analýzy propojení“. American Journal of Human Genetics. 81 (3): 559–575. doi:10.1086/519795. PMC 1950838. PMID 17701901.
- ^ Ian W. Evett; Bruce S. Weir (leden 1998). Interpretace důkazů DNA: Statistická genetika pro forenzní vědce. Sinauer Associates, Incorporated. ISBN 978-0-87893-155-2.
- ^ Leutenegger, A .; Prum, B .; Genin, E .; Verny, C .; Lemainque, A .; Clergetdarpoux, F .; Thompson, E. (2003). „Odhad koeficientu inbreedingu pomocí genomických dat“. American Journal of Human Genetics. 73 (3): 516–523. doi:10.1086/378207. PMC 1180677. PMID 12900793.
- ^ Voight, B.F .; Pritchard, J. K. (2005). „Matoucí z kryptické souvislosti ve studiích asociace případových kontrol“. Genetika PLOS. 1 (3): e32. doi:10.1371 / journal.pgen.0010032. PMC 1200427. PMID 16151517.
- ^ Kong, A .; Masson, G .; Frigge, M. L .; Gylfason, A .; Zusmanovich, P .; Thorleifsson, G .; Olason, P. I .; Ingason, A .; Steinberg, S .; Rafnar, T .; Sulem, P .; Mouy, M .; Jonsson, F .; Thorsteinsdottir, U .; Gudbjartsson, D. F .; Stefansson, H .; Stefansson, K. (2008). „Detekce sdílení podle původu, fázování na velké vzdálenosti a imputace haplotypu“. Genetika přírody. 40 (9): 1068–1075. doi:10,1038 / ng.216. PMC 4540081. PMID 19165921.
- ^ A b Gusev, A .; Shah, M. J .; Kenny, E. E.; Ramachandran, A .; Lowe, J. K .; Salit, J .; Lee, C. C .; Levandowsky, E. C .; Weaver, T. N .; Doan, Q. C .; Peckham, H. E.; McLaughlin, S. F .; Lyons, M. R.; Sheth, V. N .; Stoffel, M .; De La Vega, F. M .; Friedman, J. M .; Breslow, J.L .; Pe'Er, I. (2011). „Low-Pass Genome-Wide Sequencing and Variant Inference using Identity-by-Descent in a Isolated Human Population“. Genetika. 190 (2): 679–689. doi:10.1534 / genetika.111.134874. PMC 3276614. PMID 22135348.
- ^ Browning, B.L .; Browning, S. R. (2009). „Jednotný přístup k imputaci genotypu a odvození fáze haplotypu pro velké datové sady tria a nepříbuzných jedinců“. American Journal of Human Genetics. 84 (2): 210–223. doi:10.1016 / j.ajhg.2009.01.005. PMC 2668004. PMID 19200528.
- ^ A b C Hochreiter, S. (2013). „HapFABIA: Identifikace velmi krátkých segmentů identity sestupem charakterizovaným vzácnými variantami ve velkých sekvenčních datech“. Výzkum nukleových kyselin. 41 (22): e202. doi:10.1093 / nar / gkt1013. PMC 3905877. PMID 24174545.
- ^ A b Browning, S. R .; Thompson, E. A. (2012). „Detekce vzácných asociací variant podle mapování identity podle původu ve studiích případové kontroly“. Genetika. 190 (4): 1521–1531. doi:10.1534 / genetika.111.136937. PMC 3316661. PMID 22267498.
- ^ A b Gusev, A .; Kenny, E. E.; Lowe, J. K .; Salit, J .; Saxena, R .; Kathiresan, S .; Altshuler, D. M .; Friedman, J. M .; Breslow, J.L .; Pe'Er, I. (2011). „DASH: Metoda pro mapování haplotypu identického původu sestupem odhaluje asociaci s nedávnou variací“. American Journal of Human Genetics. 88 (6): 706–717. doi:10.1016 / j.ajhg.2011.04.023. PMC 3113343. PMID 21620352.
- ^ Houwen, R. H. J .; Baharloo, S .; Blankenship, K .; Raeymaekers, P .; Juyn, J .; Sandkuijl, L. A .; Freimer, N. B. (1994). "Screening genomu hledáním sdílených segmentů: Mapování genu pro benigní rekurentní intrahepatální cholestázu". Genetika přírody. 8 (4): 380–386. doi:10.1038 / ng1294-380. hdl:1765/55192. PMID 7894490.
- ^ Kenny, E. E.; Gusev, A .; Riegel, K .; Lutjohann, D .; Lowe, J. K .; Salit, J .; Maller, J. B .; Stoffel, M .; Daly, M. J .; Altshuler, D. M .; Friedman, J. M .; Breslow, J.L .; Pe'Er, I .; Sehayek, E. (2009). „Systematická analýza haplotypu řeší komplex lokusů sterolů plazmové rostliny na mikronézském ostrově Kosrae“. Sborník Národní akademie věd. 106 (33): 13886–13891. doi:10.1073 / pnas.0907336106. PMC 2728990. PMID 19667188.
- ^ Francks, C .; Tozzi, F .; Farmer, A .; Vincent, J. B .; Rujescu, D .; St Clair, D .; Muglia, P. (2008). „Populační vazebná analýza schizofrenie a bipolárních kohort kontrolujících případy identifikuje potenciální lokus citlivosti na 19q13“. Molekulární psychiatrie. 15 (3): 319–325. doi:10.1038 / mp.2008.100. PMID 18794890.
- ^ Lin, R .; Charlesworth, J .; Stankovich, J .; Perreau, V. M .; Brown, M. A .; Anzgene, B. V .; Taylor, B. V. (2013). Toland, Amanda Ewart (ed.). „Mapování identity podle sestupu k detekci vzácných variant udávajících náchylnost k roztroušené skleróze“. PLOS ONE. 8 (3): e56379. doi:10.1371 / journal.pone.0056379. PMC 3589405. PMID 23472070.
- ^ Letouzé, E .; Sow, A .; Petel, F .; Rosati, R .; Figueiredo, B. C .; Burnichon, N .; Gimenez-Roqueplo, A. P .; Lalli, E .; De Reyniès, A. L. (2012). Mailund, Thomas (ed.). „Mapování identity podle sestupu zakladatelských mutací v rakovině pomocí dat nádoru s vysokým rozlišením SNP“. PLOS ONE. 7 (5): e35897. doi:10.1371 / journal.pone.0035897. PMC 3342326. PMID 22567117.
- ^ Albrechtsen, A .; Moltke, I .; Nielsen, R. (2010). „Přirozený výběr a distribuce identity podle původu v lidském genomu“. Genetika. 186 (1): 295–308. doi:10.1534 / genetika.110.113977. PMC 2940294. PMID 20592267.
- ^ Han, L .; Abney, M. (2011). „Identita podle odhadu sestupu s hustými genotypovými údaji v celém genomu“. Genetická epidemiologie. 35 (6): 557–567. doi:10.1002 / gepi.20606. PMC 3587128. PMID 21769932.
- ^ Cockerham, C. C .; Weir, B. S. (1983). Msgstr "Odchylka od skutečné inbreedingu". Teoretická populační biologie. 23 (1): 85–109. doi:10.1016/0040-5809(83)90006-0. PMID 6857551.
- ^ A b Gusev, A .; Palamara, P. F .; Aponte, G .; Zhuang, Z .; Darvasi, A .; Gregersen, P .; Pe'Er, I. (2011). „Architektura haplotypů dlouhého dosahu sdílená uvnitř a napříč populacemi“. Molekulární biologie a evoluce. 29 (2): 473–486. doi:10.1093 / molbev / msr133. PMC 3350316. PMID 21984068.
- ^ A b Palamara, P. F .; Lencz, T .; Darvasi, A .; Pe’Er, I. (2012). „Distribuce délky identity podle původu odhaluje jemnou demografickou historii“. American Journal of Human Genetics. 91 (5): 809–822. doi:10.1016 / j.ajhg.2012.08.030. PMC 3487132. PMID 23103233.
- ^ A b Palamara, P. F .; Pe'Er, I. (2013). „Odvození historických rychlostí migrace prostřednictvím sdílení haplotypu“. Bioinformatika. 29 (13): i180 – i188. doi:10.1093 / bioinformatika / btt239. PMC 3694674. PMID 23812983.
- ^ Carmi, S .; Palamara, P. F .; Vacic, V .; Lencz, T .; Darvasi, A .; Pe'Er, I. (2012). „Rozptyl sdílení identity podle původu v modelu Wright-Fisher“. Genetika. 193 (3): 911–928. doi:10.1534 / genetika.112.147215. PMC 3584006. PMID 23267057.
- ^ Botigue, L. R .; Henn, B. M .; Gravel, S .; Maples, B. K .; Gignoux, C. R .; Corona, E .; Atzmon, G .; Burns, E .; Ostrer, H .; Flores, C .; Bertranpetit, J .; Comas, D .; Bustamante, C. D. (2013). „Tok genů ze severní Afriky přispívá k rozdílné lidské genetické rozmanitosti v jižní Evropě“. Sborník Národní akademie věd. 110 (29): 11791–11796. doi:10.1073 / pnas.1306223110. PMC 3718088. PMID 23733930.
- ^ Ralph, P .; Coop, G. (2013). Tyler-Smith, Chris (ed.). „Geografie nedávného genetického původu v celé Evropě“. PLOS Biology. 11 (5): e1001555. doi:10.1371 / journal.pbio.1001555. PMC 3646727. PMID 23667324.
- ^ Gravel, S .; Zakharia, F .; Moreno-Estrada, A .; Byrnes, J. K .; Muzzio, M .; Rodriguez-Flores, J.L .; Kenny, E. E.; Gignoux, C. R .; Maples, B. K .; Guiblet, W .; Dutil, J .; Via, M .; Sandoval, K .; Bedoya, G .; 1000 Genomes, T. K.; Oleksyk, A .; Ruiz-Linares, E. G .; Burchard, J. C .; Martinez-Cruzado, C. D .; Bustamante, C. D. (2013). Williams, Scott M. (ed.). „Rekonstrukce migrací původních Američanů z údajů o celém genomu a datech z celého Exomu“. Genetika PLOS. 9 (12): e1004023. doi:10.1371 / journal.pgen.1004023. PMC 3873240. PMID 24385924.
- ^ Ringbauer, Harald; Coop, Graham; Barton, Nicholas H. (03.03.2017). „Odvození nedávné demografie z izolace podle vzdálenosti bloků dlouhé sdílené sekvence“. Genetika. 205 (3): 1335–1351. doi:10.1534 / genetika.116.196220. ISSN 0016-6731. PMC 5340342. PMID 28108588.
- ^ Naseri A, Liu X, Zhang S, Zhi D. Ultrarychlá identifikace podle detekce sestupu v kohortách v Biobank v měřítku pomocí Poziční Burrows-Wheeler Transform BioRxiv 2017.
- ^ Rodriguez JM, Batzoglou S, Bercovici S. Přesná metoda pro odvození příbuznosti ve velkých souborech dat nefázovaných genotypů pomocí integrovaného testu pravděpodobnosti. RECOMB 2013, LNBI 7821: 212-229.
- ^ Browning, B.L .; Browning, S. R. (2011). „Rychlá a výkonná metoda detekce identity podle původu“. American Journal of Human Genetics. 88 (2): 173–182. doi:10.1016 / j.ajhg.2011.01.010. PMC 3035716. PMID 21310274.
- ^ Browning, B.L .; Browning, S. R. (2013). „Zlepšení přesnosti a účinnosti detekce identity podle původu v populačních datech“. Genetika. 194 (2): 459–471. doi:10.1534 / genetika.113.150029. PMC 3664855. PMID 23535385.
- ^ Browning, B.L .; Browning, S. R. (2013). „Detekce identity podle původu a odhad chybových rychlostí genotypu v sekvenčních datech“. American Journal of Human Genetics. 93 (5): 840–851. doi:10.1016 / j.ajhg.2013.09.014. PMC 3824133. PMID 24207118.
- ^ Moltke, I .; Albrechtsen, A .; Hansen, T. V. O .; Nielsen, F. C .; Nielsen, R. (2011). „Metoda pro detekci oblastí IBD současně u více jedinců - s aplikacemi na genetiku nemocí“. Výzkum genomu. 21 (7): 1168–1180. doi:10,1101 / gr.115360.110. PMC 3129259. PMID 21493780.
- ^ On, D. (2013). „IBD-Groupon: Efektivní metoda pro detekci skupinových oblastí identity podle původu současně u více jedinců na základě párových IBD vztahů“. Bioinformatika. 29 (13): i162 – i170. doi:10.1093 / bioinformatika / btt237. PMC 3694672. PMID 23812980.