Smith – Watermanův algoritmus - Smith–Waterman algorithm
| Třída | Sekvenční zarovnání |
|---|---|
| Nejhorší případ výkon | |
| Nejhorší případ složitost prostoru |


The Smith – Watermanův algoritmus provádí místní zarovnání sekvence; tj. pro určení podobných oblastí mezi dvěma řetězci sekvence nukleových kyselin nebo proteinové sekvence. Místo pohledu na celý sekvence, algoritmus Smith – Waterman porovnává segmenty všech možných délek a optimalizuje the opatření podobnosti.
Algoritmus poprvé navrhl Temple F. Smith a Michael S. Waterman v roce 1981.[1] Jako Algoritmus Needleman – Wunsch, jehož je to variace, Smith – Waterman je dynamické programování algoritmus. Jako takový má žádoucí vlastnost, že je zaručeno nalezení optimálního místního zarovnání s ohledem na použitý bodovací systém (který zahrnuje substituční matice a bodování mezer systém). Hlavní rozdíl oproti Algoritmus Needleman – Wunsch je, že buňky matice negativního skórování jsou nastaveny na nulu, což zviditelní (tedy pozitivně skórující) lokální zarovnání. Procedura Traceback začíná na buňce matice s nejvyšším skóre a pokračuje, dokud nenarazí na buňku s nulovým skóre, čímž se získá místní zarovnání s nejvyšším skóre. Kvůli své kvadratické složitosti v čase a prostoru jej často nelze prakticky aplikovat na problémy velkého rozsahu a je nahrazen ve prospěch méně obecných, ale výpočetně efektivnějších alternativ, jako je (Gotoh, 1982),[2] (Altschul a Erickson, 1986),[3] a (Myers a Miller, 1988).[4]
Dějiny
V roce 1970 navrhli Saul B. Needleman a Christian D. Wunsch heuristický algoritmus homologie pro zarovnání sekvence, označovaný také jako algoritmus Needleman – Wunsch.[5] Jedná se o algoritmus globálního zarovnání, který vyžaduje kroky výpočtu ( a jsou délky dvou sekvencí, které jsou zarovnány). Používá iterativní výpočet matice za účelem zobrazení globálního zarovnání. V následujícím desetiletí, Sankoff,[6] Reichert,[7] Beyer[8] a další formulovali alternativní heuristické algoritmy pro analýzu genových sekvencí. Prodejci představili systém pro měření sekvenčních vzdáleností.[9] V roce 1976 Waterman et al. přidal koncept mezer do původního systému měření.[10] V roce 1981 publikovali Smith a Waterman svůj algoritmus Smith – Waterman pro výpočet lokálního zarovnání.


Algoritmus Smith – Waterman je poměrně náročný na čas: Zarovnat dvě sekvence délek a , je vyžadován čas. Gotoh[2] a Altschul[3] optimalizoval algoritmus na kroky. Složitost prostoru optimalizovali Myers a Miller[4] z na (lineární), kde je délka kratší sekvence pro případ, kdy je požadováno pouze jedno z mnoha možných optimálních zarovnání.

Motivace
V posledních letech, genomové projekty prováděné na různých organismech generovalo obrovské množství sekvenčních dat pro geny a proteiny, což vyžaduje výpočetní analýzu. Zarovnání sekvence ukazuje vztahy mezi geny nebo mezi proteiny, což vede k lepšímu pochopení jejich homologie a funkčnosti. Sekvenční zarovnání může také odhalit konzervované domény a motivy.
Jednou z motivací pro místní srovnání je obtížnost získání správného srovnání v oblastech s nízkou podobností mezi vzdáleně příbuznými biologickými sekvencemi, protože mutace během evolučního času přidaly příliš mnoho „šumu“, aby umožnily smysluplné srovnání těchto oblastí. Místní vyrovnání se těmto regionům úplně vyhýbá a zaměřuje se na ty s pozitivním skóre, tj. Na ty, které mají evolučně konzervovaný signál podobnosti. Předpokladem pro místní zarovnání je negativní očekávané skóre. Očekávané skóre je definováno jako průměrné skóre, které bodovací systém (substituční matice a pokuty za mezery ) by přineslo náhodnou sekvenci.
Další motivací pro použití lokálních zarovnání je to, že existuje spolehlivý statistický model (vyvinutý Karlinem a Altschulem) pro optimální místní zarovnání. Zarovnání nesouvisejících sekvencí má tendenci produkovat optimální lokální skóre zarovnání, které následují extrémní distribuci hodnot. Tato vlastnost umožňuje programům vytvářet očekávaná hodnota pro optimální lokální zarovnání dvou sekvencí, což je měřítko toho, jak často by dvě nesouvisející sekvence produkovaly optimální lokální zarovnání, jehož skóre je větší nebo rovno pozorovanému skóre. Velmi nízké hodnoty očekávání naznačují, že tyto dvě sekvence mohou být homologní, což znamená, že by mohli sdílet společného předka.
Algoritmus
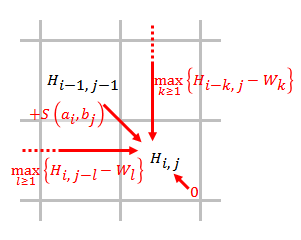
Nechat a být sekvence, které mají být srovnány, kde a jsou délky a resp.




- Určete substituční matici a schéma postihu za mezeru.
- - Skóre podobnosti prvků, které tvořily dvě sekvence
- - Trest mezery, která má délku
- Vytvořte bodovací matici a inicializovat jeho první řádek a první sloupec. Velikost bodovací matice je . Matice používá indexování na základě 0.
- Naplňte bodovací matici pomocí níže uvedené rovnice.
- kde
- je skóre vyrovnání a ,
- je skóre, pokud je na konci mezery délky ,
- je skóre, pokud je na konci mezery délky ,
- znamená, že neexistuje žádná podobnost a .
- Vystopovat. Počínaje nejvyšším skóre v bodovací matici a končící v buňce matice, která má skóre 0, zpětné vysledování založené na zdroji každého skóre rekurzivně, aby se vygenerovalo nejlepší místní zarovnání.














Vysvětlení
Algoritmus Smith – Waterman zarovná dvě sekvence podle shody / nesouladu (také známé jako substituce), vložení a odstranění. Vložení i odstranění jsou operace, které zavádějí mezery, které jsou reprezentovány pomlčkami. Algoritmus Smith – Waterman má několik kroků:
- Určete substituční matici a schéma postihu za mezeru. Substituční matice přiřadí každé dvojici bází nebo aminokyselin skóre shody nebo nesouladu. Zápasy obvykle získávají pozitivní skóre, zatímco neshody získávají relativně nižší skóre. Funkce trestu za mezeru určuje cenu skóre za otevření nebo prodloužení mezery. Doporučuje se, aby si uživatelé vybrali vhodný bodovací systém na základě cílů. Kromě toho je také dobrým zvykem vyzkoušet různé kombinace substitučních matic a pokut za mezery.
- Inicializujte bodovací matici. Rozměry skórovací matice jsou 1 + délka každé sekvence. Všechny prvky prvního řádku a prvního sloupce jsou nastaveny na 0. Mimořádně první řádek a první sloupec umožňují zarovnat jednu sekvenci s druhou na libovolné pozici a jejich nastavení na 0 způsobí, že koncová mezera nebude penalizována.
- Bodování. Skóre každého prvku zleva doprava, shora dolů v matici, s ohledem na výsledky substitucí (diagonální skóre) nebo přidání mezer (horizontální a vertikální skóre). Pokud žádné ze skóre není kladné, dostane tento prvek 0. Jinak se použije nejvyšší skóre a zaznamená se zdroj tohoto skóre.
- Vystopovat. Počínaje prvkem s nejvyšším skóre, zpětné trasování založené na zdroji každého skóre rekurzivně, dokud nenastane 0. V tomto procesu jsou generovány segmenty, které mají nejvyšší skóre podobnosti založené na daném bodovacím systému. Chcete-li získat druhé nejlepší místní zarovnání, použijte proces zpětného trasování počínaje druhým nejvyšším skóre mimo trasování nejlepšího zarovnání.
Srovnání s algoritmem Needleman – Wunsch
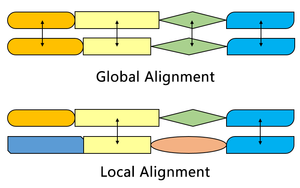
Algoritmus Smith – Waterman najde segmenty ve dvou sekvencích, které mají podobnosti, zatímco algoritmus Needleman – Wunsch zarovná dvě úplné sekvence. Proto slouží různým účelům. Oba algoritmy používají pojmy substituční matice, funkce penalizace mezer, skórovací matice a proces zpětného sledování. Tři hlavní rozdíly jsou:
| Smith – Watermanův algoritmus | Algoritmus Needleman – Wunsch | |
|---|---|---|
| Inicializace | První řádek a první sloupec jsou nastaveny na 0 | První řádek a první sloupec podléhají penalizaci mezery |
| Bodování | Negativní skóre je nastaveno na 0 | Skóre může být záporné |
| Vystopovat | Začněte nejvyšším skóre, skončete, když narazíte na 0 | Začněte buňkou v pravém dolním rohu matice, konec v levé horní buňce |
Jedním z nejdůležitějších rozdílů je, že v systému bodování algoritmu Smith – Waterman, který umožňuje místní zarovnání, není přiřazeno žádné negativní skóre. Pokud má některý prvek skóre nižší než nula, znamená to, že sekvence až do této polohy nemají žádnou podobnost; tento prvek bude poté nastaven na nulu, aby se vyloučil vliv předchozího zarovnání. Tímto způsobem může výpočet pokračovat v hledání zarovnání v jakékoli poloze poté.
Počáteční skórovací matice algoritmu Smith – Waterman umožňuje zarovnání libovolného segmentu jedné sekvence s libovolnou pozicí v druhé sekvenci. V algoritmu Needleman – Wunsch je však třeba vzít v úvahu pokutu za koncovou mezeru, aby se zarovnaly celé sekvence.
Substituční matice
Každé substituci báze nebo substituci aminokyseliny je přiřazeno skóre. Obecně se zápasům přiřazují kladná skóre a nesouladům se přiřazují relativně nižší skóre. Jako příklad si vezměte sekvenci DNA. Pokud zápasy získají +1, nesoulady -1, pak substituční matice je:
| A | G | C | T | |
|---|---|---|---|---|
| A | 1 | -1 | -1 | -1 |
| G | -1 | 1 | -1 | -1 |
| C | -1 | -1 | 1 | -1 |
| T | -1 | -1 | -1 | 1 |
Tuto substituční matici lze popsat jako:

Různé základní substituce nebo aminokyselinové substituce mohou mít různá skóre. Substituční matice aminokyselin je obvykle složitější než u bází. Vidět PAM, BLOSUM.
Penalizace za mezeru
Trest mezery označuje skóre pro vložení nebo odstranění. Jednoduchou strategií penalizace za mezeru je použít pevné skóre pro každou mezeru. V biologii je však z praktických důvodů třeba počítat skóre jinak. Na jedné straně je částečná podobnost mezi dvěma sekvencemi běžným jevem; na druhé straně může událost jediné mutace genu vést k vložení jedné dlouhé mezery. Proto jsou spojené mezery tvořící dlouhou mezeru obvykle upřednostňovány než více rozptýlených krátkých mezer. Aby byl tento rozdíl zohledněn, byly do systému hodnocení přidány koncepty otevírání a prodlužování mezer. Skóre otevření mezery je obvykle vyšší než skóre rozšíření mezery. Například výchozí parametr v EMBOSS Voda jsou: otevření mezery = 10, prodloužení mezery = 0,5.
Zde diskutujeme dvě společné strategie pro pokutu za mezeru. Vidět Penalizace za mezeru pro více strategií. Pojďme být funkcí trestu za mezeru za délkovou mezeru :
Lineární
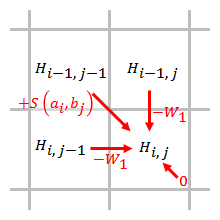
Trest za lineární mezeru má stejné skóre za otevření a prodloužení mezery:
,

kde jsou náklady na jednu mezeru.

Trest za mezeru je přímo úměrný délce mezery. Při použití lineárního trestu za mezeru lze algoritmus Smith – Waterman zjednodušit na:

Zjednodušený algoritmus používá kroky. Při skórování prvku je třeba vzít v úvahu pouze penalizace za mezery od prvků, které přímo sousedí s tímto prvkem.
Afinní
Penalizace za afinní mezeru zvažuje otevření a prodloužení mezery zvlášť:
,

kde je penalta za otevření mezery a je pokuta za prodloužení mezery. Například trest za mezeru o délce 2 je .



V původním článku algoritmu Smith – Waterman byl použit libovolný trest za mezeru. Využívá to kroky, proto je časově docela náročný. Gotoh optimalizoval kroky pro pokutu za afinní mezeru ,[2] ale optimalizovaný algoritmus se pokouší najít pouze jedno optimální zarovnání a optimální zarovnání není zaručeno.[3] Altschul upravil Gotohův algoritmus tak, aby našel všechna optimální vyrovnání při zachování výpočetní složitosti.[3] Později Myers a Miller poukázali na to, že algoritmus Gotoh a Altschul lze dále upravit na základě metody, kterou publikoval Hirschberg v roce 1975,[11] a použil tuto metodu.[4] Algoritmus Myerse a Millera dokáže pomocí dvou sekvencí zarovnat vesmír, s je délka kratší sekvence.

Příklad pokuty za mezeru
Vezměte zarovnání sekvencí TACGGGCCCGCTAC a TAGCCCTATCGGTCA jako příklad.Při použití funkce lineárního trestu za mezeru je výsledkem (Zarovnání provedené EMBOSS Water. Substituční matice je DNAfull. Otevření a rozšíření mezery jsou 1,0):
TACGGGCCCGCTA-C|| | || ||| |TA --- G-CC-CTATC
Při použití postihu za afinní mezeru je výsledek (otevření mezery a prodloužení 5,0 a 1,0):
TACGGGCCCGCTA|| ||| |||TA --- GCC - CTA
Tento příklad ukazuje, že pokuta za afinní mezeru může pomoci vyhnout se rozptýleným malým mezerám.
Bodovací matice
Funkcí skórovací matice je provádět individuální srovnání všech složek ve dvou sekvencích a zaznamenávat optimální výsledky zarovnání. Proces bodování odráží koncept dynamického programování. Konečné optimální zarovnání se zjistí iterativním rozšířením rostoucího optimálního zarovnání. Jinými slovy, aktuální optimální zarovnání je generováno rozhodnutím, která cesta (shoda / neshoda nebo vložení mezery) dává nejvyšší skóre z předchozího optimálního zarovnání. Velikost matice je délka jedné sekvence plus 1 o délku druhé sekvence plus 1. Další první řádek a první sloupec slouží k zarovnání jedné sekvence na libovolné pozice v druhé sekvenci. První řádek i první sloupec jsou nastaveny na 0, takže koncová mezera nebude penalizována. Počáteční bodovací matice je:
| b1 | … | bj | … | bm | ||
|---|---|---|---|---|---|---|
| 0 | 0 | … | 0 | … | 0 | |
| A1 | 0 | |||||
| … | … | |||||
| Ai | 0 | |||||
| … | … | |||||
| An | 0 |
Příklad
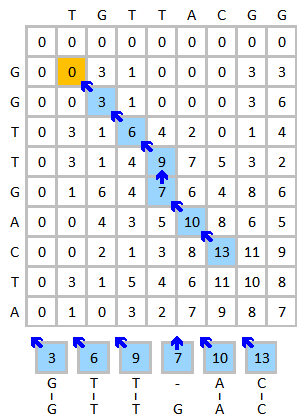
Vezměte zarovnání sekvencí DNA TGTTACGG a GGTTGACTA jako příklad. Použijte následující schéma:
- Substituční matice:
- Trest mezery: (trest za lineární mezeru ve výši )



Inicializujte a vyplňte bodovací matici, jak je uvedeno níže. Tento obrázek ukazuje proces bodování prvních tří prvků. Žlutá barva označuje báze, které jsou zvažovány. Červená barva označuje nejvyšší možné skóre pro hodnocenou buňku.

Hotová bodovací matice je zobrazena vlevo dole. Modrá barva ukazuje nejvyšší skóre. Prvek může získat skóre od více než jednoho prvku, každý z nich vytvoří jinou cestu, pokud je tento prvek zpětně vysledován. V případě více nejvyšších skóre by mělo být provedeno zpětné sledování počínaje každým nejvyšším skóre. Proces zpětného sledování je uveden níže vpravo. Nejlepší místní zarovnání je generováno v opačném směru.
 |  |
| Hotová bodovací matice (nejvyšší skóre je modré) | Výsledek procesu zpětného sledování a zarovnání |
Výsledek zarovnání je:
G T T - A C| | | | |G T T G A C
Implementace
Implementace Smith – Watermanova algoritmu, SSEARCH, je k dispozici v FASTA balíček pro sekvenční analýzu z UVA FASTA ke stažení. Tato implementace zahrnuje Altivec zrychlený kód pro PowerPC Procesory G4 a G5, které zrychlují srovnání 10–20krát, pomocí modifikace přístupu Wozniak, 1997,[12] a vektorizace SSE2 vyvinutá Farrarem[13] tvorba optimálního proteinu sekvenční databáze hledá docela praktické. Knihovna, SSW, rozšiřuje implementaci Farrar tak, aby kromě optimálního skóre Smith – Waterman vrátila informace o zarovnání.[14]
Zrychlené verze
FPGA
Cray demonstroval zrychlení algoritmu Smith – Waterman pomocí a rekonfigurovatelné výpočty platforma založená na FPGA čipy, přičemž výsledky ukazují až 28násobné zrychlení oproti standardním řešením založeným na mikroprocesorech. Další verze algoritmu Smith – Waterman založená na FPGA ukazuje zrychlení FPGA (Virtex-4) až 100x[15] přes 2,2 GHz procesor Opteron.[16] The TimeLogic Systémy DeCypher a CodeQuest také urychlují Smith – Waterman a Framesearch pomocí karet PCIe FPGA.
Diplomová práce z roku 2011 [17] zahrnuje analýzu zrychlení Smith – Waterman na bázi FPGA.
V publikaci z roku 2016 OpenCL kód kompilovaný s Xilinx SDAccel zrychluje sekvenování genomu, překonává výkon CPU / GPU / W 12-21x, byla představena velmi efektivní implementace. Při použití jedné karty PCIe FPGA vybavené procesorem Xilinx Virtex-7 2000T FPGA byl výkon na watt lepší o 12-21x než CPU / GPU.
GPU
Lawrence Livermore National Laboratory a ministerstvo energetiky USA (USA) Společný genomový institut implementoval zrychlenou verzi vyhledávání lokálních sekvencí Smith – Waterman pomocí jednotky grafického zpracování (GPU) s předběžnými výsledky, které ukazují dvojnásobné zrychlení oproti softwarovým implementacím.[18] Podobná metoda je již implementována v softwaru Biofacet od roku 1997, se stejným faktorem zrychlení.[19]
Několik GPU implementace algoritmu ve Windows NVIDIA je CUDA K dispozici je také platforma C.[20] Ve srovnání s nejznámější implementací CPU (pomocí instrukcí SIMD na architektuře x86), Farrar, testy výkonu tohoto řešení pomocí jediného NVidia GeForce 8800 GTX karta ukazuje mírné zvýšení výkonu pro menší sekvence, ale mírné snížení výkonu pro větší sekvence. Stejné testy však běží na duálních NVidia GeForce 8800 GTX karty jsou téměř dvakrát rychlejší než implementace Farrar pro všechny testované velikosti sekvencí.
Nyní je k dispozici novější implementace SW GPU CUDA, která je rychlejší než předchozí verze a také odstraňuje omezení délek dotazů. Vidět CUDASW ++.
Bylo hlášeno jedenáct různých implementací SW na CUDA, z nichž tři uvádějí zrychlení 30krát.[21]
SIMD
V roce 2000 došlo k rychlé implementaci Smith-Watermanova algoritmu pomocí SIMD technologie dostupná v Intel Pentium MMX procesory a podobné technologie byly popsány v publikaci Rognes a Seeberg.[22] Na rozdíl od přístupu Wozniaka (1997) byla nová implementace založena na vektorech paralelních se sekvencí dotazu, nikoli na diagonálních vektorech. Společnost Sencel Bioinformatika požádal o patent pokrývající tento přístup. Sencel software dále vyvíjí a poskytuje spustitelné soubory pro akademické použití zdarma.
A SSE2 vektorizace algoritmu (Farrar, 2007) je nyní k dispozici a poskytuje 8–16násobné zrychlení na procesorech Intel / AMD s rozšířeními SSE2.[13] Při běhu na procesoru Intel pomocí Základní mikroarchitektura implementace SSE2 dosahuje 20násobného zvýšení. Implementace Farrar SSE2 je k dispozici jako program SSEARCH v FASTA balíček porovnání sekvencí. Hledání je zahrnuto v Evropský bioinformatický institut je sada programy pro vyhledávání podobnosti.
Dánská společnost pro bioinformatiku CLC bio dosáhl zrychlení téměř 200 oproti standardním softwarovým implementacím s SSE2 na procesoru Intel 2,17 GHz Core 2 Duo, podle veřejně dostupná bílá kniha.
Zrychlená verze algoritmu Smith – Waterman, zapnuta Intel a AMD založené na Linuxových serverech, je podporováno GenCore 6 balíček, který nabízí Biorychlení. Výkonnostní měřítka tohoto softwarového balíčku ukazují až desetinásobnou rychlost zrychlení ve srovnání se standardní implementací softwaru na stejném procesoru.
V současné době jediná společnost v bioinformatice, která nabízí řešení SSE i FPGA urychlující Smith – Waterman, CLC bio dosáhl zrychlení více než 110 oproti standardním softwarovým implementacím s CLC Bioinformatics Cube[Citace je zapotřebí ]
Nejrychlejší implementace algoritmu na CPU s SSSE3 lze najít SWIPE software (Rognes, 2011),[23] který je k dispozici pod GNU Affero General Public License. Souběžně tento software porovnává zbytky ze šestnácti různých databázových sekvencí s jedním zbytkem dotazu. Použitím sekvence dotazů na zbytky 375 bylo na duálním procesoru Intel dosaženo rychlosti 106 miliard aktualizací buněk za sekundu (GCUPS) Xeon Šestijádrový procesor X5650, který je více než šestkrát rychlejší než software založený na „pruhovaném“ přístupu společnosti Farrar. Je to rychlejší než VÝBUCH při použití matice BLOSUM50.
Existuje také diagonalsw, implementace C a C ++ algoritmu Smith – Waterman se sadami instrukcí SIMD (SSE4.1 pro platformu x86 a AltiVec pro platformu PowerPC). Je licencován pod open-source licencí MIT.
Cell Broadband Engine
V roce 2008 Farrar[24] popsal přístav Striped Smith – Waterman[13] do Cell Broadband Engine a ohlásil rychlosti 32 a 12 GCUPS na Blade IBM QS20 a Sony PlayStation 3, resp.
Omezení
Rychlá expanze genetických dat zpochybňuje rychlost současných algoritmů zarovnání sekvence DNA. Základní potřeby efektivní a přesné metody pro objevování variant DNA vyžadují inovativní přístupy k paralelnímu zpracování v reálném čase. Optické výpočty přístupy byly navrženy jako slibné alternativy k současným elektrickým implementacím. OptCAM je příkladem takových přístupů a ukázalo se, že je rychlejší než algoritmus Smith – Waterman.[25]
Viz také
- Bioinformatika
- Sekvenční zarovnání
- Sekvenční těžba
- Algoritmus Needleman – Wunsch
- Levenshteinova vzdálenost
- VÝBUCH
- FASTA
Reference
- ^ Smith, Temple F. & Waterman, Michael S. (1981). „Identifikace běžných molekulárních následků“ (PDF). Journal of Molecular Biology. 147 (1): 195–197. CiteSeerX 10.1.1.63.2897. doi:10.1016/0022-2836(81)90087-5. PMID 7265238.
- ^ A b C Osamu Gotoh (1982). Msgstr "Vylepšený algoritmus pro porovnávání biologických sekvencí". Journal of Molecular Biology. 162 (3): 705–708. CiteSeerX 10.1.1.204.203. doi:10.1016/0022-2836(82)90398-9. PMID 7166760.
- ^ A b C d Stephen F. Altschul a Bruce W. Erickson (1986). Msgstr "Optimální zarovnání sekvence pomocí nákladů na afinní mezeru". Bulletin of Mathematical Biology. 48 (5–6): 603–616. doi:10.1007 / BF02462326. PMID 3580642. S2CID 189889143.
- ^ A b C Miller, Webb; Myers, Eugene (1988). Msgstr "Optimální zarovnání v lineárním prostoru". Bioinformatika. 4 (1): 11–17. CiteSeerX 10.1.1.107.6989. doi:10.1093 / bioinformatika / 4.1.11. PMID 3382986.
- ^ Saul B. Needleman; Christian D. Wunsch (1970). "Obecná metoda použitelná pro hledání podobností v aminokyselinové sekvenci dvou proteinů". Journal of Molecular Biology. 48 (3): 443–453. doi:10.1016/0022-2836(70)90057-4. PMID 5420325.
- ^ Sankoff D. (1972). "Odpovídající sekvence v rámci omezení mazání / vkládání". Sborník Národní akademie věd Spojených států amerických. 69 (1): 4–6. Bibcode:1972PNAS ... 69 .... 4S. doi:10.1073 / pnas.69.1.4. PMC 427531. PMID 4500555.
- ^ Thomas A. Reichert; Donald N. Cohen; Andrew K.C. Wong (1973). "Aplikace teorie informace na genetické mutace a porovnávání polypeptidových sekvencí". Journal of Theoretical Biology. 42 (2): 245–261. doi:10.1016 / 0022-5193 (73) 90088-X. PMID 4762954.
- ^ William A. Beyer, Myron L. Stein, Temple F. Smith a Stanislaw M. Ulam (1974). "Metrické a evoluční stromy s molekulární sekvencí". Matematické biologické vědy. 19 (1–2): 9–25. doi:10.1016/0025-5564(74)90028-5.CS1 maint: více jmen: seznam autorů (odkaz)
- ^ Peter H. Sellers (1974). „O teorii a výpočtu evolučních vzdáleností“. Journal of Applied Mathematics. 26 (4): 787–793. doi:10.1137/0126070.
- ^ M.S Waterman; T.F Smith; W.A Beyer (1976). "Některé metriky biologické sekvence". Pokroky v matematice. 20 (3): 367–387. doi:10.1016/0001-8708(76)90202-4.
- ^ D. S. Hirschberg (1975). Msgstr "Algoritmus lineárního prostoru pro výpočet maximálních společných posloupností". Komunikace ACM. 18 (6): 341–343. CiteSeerX 10.1.1.348.4774. doi:10.1145/360825.360861. S2CID 207694727.
- ^ Wozniak, Andrzej (1997). „Použití instrukcí zaměřených na video k urychlení porovnání sekvence“ (PDF). Počítačové aplikace v biologických vědách (CABIOS). 13 (2): 145–50. doi:10.1093 / bioinformatika / 13.2.145. PMID 9146961.
- ^ A b C Farrar, Michael S. (2007). „Striped Smith – Waterman zrychluje vyhledávání v databázi šestkrát oproti jiným implementacím SIMD“ (PDF). Bioinformatika. 23 (2): 156–161. doi:10.1093 / bioinformatika / btl582. PMID 17110365.
- ^ Zhao, Mengyao; Lee, Wan-Ping; Garrison, Erik P; Marth, Gabor T (4. prosince 2013). „Knihovna SSW: Knihovna SIMD Smith-Waterman C / C ++ pro použití v genomických aplikacích“. PLOS ONE. 8 (12): e82138. arXiv:1208.6350. Bibcode:2013PLoSO ... 882138Z. doi:10.1371 / journal.pone.0082138. PMC 3852983. PMID 24324759.
- ^ FPGA 100x papíry: „Archivovaná kopie“ (PDF). Archivovány od originál (PDF) dne 2008-07-05. Citováno 2007-10-17.CS1 maint: archivovaná kopie jako titul (odkaz), „Archivovaná kopie“ (PDF). Archivovány od originál (PDF) dne 2008-07-05. Citováno 2007-10-17.CS1 maint: archivovaná kopie jako titul (odkaz), a „Archivovaná kopie“ (PDF). Archivovány od originál (PDF) dne 2011-07-20. Citováno 2007-10-17.CS1 maint: archivovaná kopie jako titul (odkaz)
- ^ Progeniq Pte. Ltd., “Bílá kniha - Zrychlení intenzivních aplikací při zrychlení 10 × –50 × k odstranění úzkých míst ve výpočetních pracovních postupech ".
- ^ Vermij, Erik (2011). Zarovnání genetické sekvence na superpočítačové platformě (PDF) (Magisterská práce). Technologická univerzita v Delftu. Archivovány od originál (PDF) dne 30. 9. 2011. Citováno 2011-08-17.
- ^ Liu, Yang; Huang, Wayne; Johnson, John; Vaidya, Sheila (2006). GPU zrychlil Smith – Waterman. Přednášky z informatiky. 3994. SpringerLink. str.188–195. doi:10.1007/11758549_29. ISBN 978-3-540-34385-1.
- ^ „Vyhledávání a analýza bioinformatiky s vysokou propustností (bílá kniha)“. GenomeQuest. Archivovány od originál 13. května 2008. Citováno 2008-05-09.
- ^ „Zóna CUDA“. Nvidia. Citováno 2010-02-25.
- ^ Rognes, Torbjørn & Seeberg, Erling (2000). „Šestinásobné zrychlení vyhledávání sekvenční databáze Smith – Waterman pomocí paralelního zpracování na běžných mikroprocesorech“ (PDF). Bioinformatika. 16 (8): 699–706. doi:10.1093 / bioinformatika / 16.8.699. PMID 11099256.
- ^ Rognes, Torbjørn (2011). „Rychlejší Smith – Watermanova databáze prohledává mezisekvenční paralelizaci SIMD“. BMC bioinformatika. 12: 221. doi:10.1186/1471-2105-12-221. PMC 3120707. PMID 21631914.
- ^ Farrar, Michael S. (2008). „Optimalizace Smith – Waterman pro buňkový širokopásmový motor“. Archivovány od originál dne 2012-02-12. Citovat deník vyžaduje
| deník =(Pomoc) - ^ Maleki, Ehsan; Koohi, Somayyeh; Kavehvash, Zahra; Mashaghi, Alireza (2020). „OptCAM: Ultrarychlá all-optická architektura pro objevování variant DNA“. Journal of Biophotonics. 13 (1): e201900227. doi:10.1002 / jbio.201900227. PMID 31397961.
externí odkazy
- JAligner - open source implementace Java algoritmu Smith – Waterman
- B.A.B.A. - applet (se zdrojem), který vizuálně vysvětluje algoritmus
- RYCHLE / VYHLEDÁVÁNÍ - stránka služeb na EBI
- UGENE Smith – Waterman plugin - open source SSEARCH kompatibilní implementace algoritmu s grafickým rozhraním napsaným v C ++
- OPÁL - knihovna SIMD C / C ++ pro masivní optimální zarovnání sekvence
- diagonalsw - implementace open-source C / C ++ se sadami instrukcí SIMD (zejména SSE4.1) na základě licence MIT
- SSW - open-source knihovna C ++ poskytující API pro implementaci SIMD algoritmu Smith – Waterman na základě licence MIT
- melodické zarovnání sekvence - implementace javascript pro zarovnání melodické sekvence