Mezní hodnota chyby (vývoj) - Error threshold (evolution) - Wikipedia
tento článek potřebuje další citace pro ověření. (Duben 2012) (Zjistěte, jak a kdy odstranit tuto zprávu šablony) |
v evoluční biologie a populační genetika, prahová hodnota chyby (nebo rychlost kritické mutace) je limit počtu základní páry samoreplikující se molekula, kterou může mít předtím, než mutace zničí informace v následujících generacích molekuly. Mezní hodnota chyby je zásadní pro pochopení „Eigenova paradoxu“.
Mezní hodnota chyby je pojem v počátcích života (abiogeneze ), zejména velmi raného života, před příchodem DNA. Předpokládá se, že první samoreplikující se molekuly mohly být malé ribozym -jako RNA molekuly. Tyto molekuly se skládají z řetězců párů bází nebo „číslic“ a jejich pořadí je kód, který řídí, jak molekula interaguje s okolním prostředím. Veškerá replikace podléhá chybě mutace. Během procesu replikace má každá číslice určitou pravděpodobnost, že bude nahrazena jinou číslicí, což změní způsob interakce molekuly s okolním prostředím a může zvýšit nebo snížit její vhodnost nebo schopnost reprodukovat se v tomto prostředí.
Fitness krajina
Bylo to zaznamenáno Manfred Eigen ve svém příspěvku z roku 1971 (Eigen 1971), že tento proces mutace omezuje počet číslic, které může molekula mít. Pokud molekula překročí tuto kritickou velikost, účinek mutací bude ohromující a proces uprchlých mutací zničí informace v následujících generacích molekuly. Chybový práh je také řízen „fitness krajinou“ pro molekuly. Fitness krajina je charakterizována dvěma koncepty výšky (= fitness) a vzdálenosti (= počet mutací). Podobné molekuly jsou si navzájem „blízké“ a molekuly, které jsou zdatnější než jiné a mají větší pravděpodobnost reprodukce, jsou „vyšší“ v krajině.
Pokud má určitá sekvence a její sousedé vysokou kondici, vytvoří a kvazidruhy a bude schopen podporovat delší délky sekvencí než fit sekvence s několika fit sousedy nebo méně fit sousedství sekvencí. Také si všiml Wilke (Wilke 2005), že koncept prahové hodnoty chyby se nevztahuje na části krajiny, kde jsou smrtelné mutace, ve kterých indukovaná mutace poskytuje nulovou kondici a zakazuje reprodukci molekuly.
Eigenův paradox
Eigenův paradox je jednou z nejnesnadnějších hádanek ve studiu původu života. Předpokládá se, že výše popsaný koncept prahové hodnoty chyby omezuje velikost samoreplikujících se molekul na možná několik stovek číslic, přesto však téměř veškerý život na Zemi vyžaduje mnohem delší molekuly pro kódování jejich genetické informace. Tento problém řeší v živých buňkách enzymy, které opravují mutace, což umožňuje kódujícím molekulám dosáhnout velikosti řádově miliónů párů bází. Tyto velké molekuly musí samozřejmě kódovat samotné enzymy, které je opravují, a v tom spočívá Eigenův paradox, který nejprve zavedl Manfred Eigen ve svém příspěvku z roku 1971 (Eigen 1971).[1] Jednoduše řečeno, Eigenův paradox se rovná následujícímu:
- Bez enzymů pro korekci chyb je maximální velikost replikující se molekuly asi 100 párů bází.
- Aby replikující molekula kódovala enzymy pro korekci chyb, musí být podstatně větší než 100 bází.
Tohle je kuře nebo vejce paradox, s ještě obtížnějším řešením. Co bylo dříve, velký genom nebo enzymy pro korekci chyb? Byla navržena řada řešení tohoto paradoxu:
- Stochastický korektorový model (Szathmáry & Maynard Smith, 1995). V tomto navrhovaném řešení je řada primitivních molekul, řekněme, dvou různých typů, nějakým způsobem spojena navzájem, možná kapslí nebo „buněčnou stěnou“. Pokud je jejich reprodukční úspěch zvýšen tím, že mají, řekněme, stejný počet v každé buňce a k reprodukci dochází dělením, ve kterém je každý z různých typů molekul náhodně rozdělen mezi „děti“, proces výběru podpoří takové stejné zastoupení v buňky, i když jedna z molekul může mít oproti druhé selektivní výhodu.
- Uvolněná prahová hodnota chyb (Kun et al., 2005) - Studie skutečných ribozymů naznačují, že rychlost mutace může být podstatně nižší, než se původně očekávalo - řádově 0,001 na pár bází na replikaci. To může umožnit délky sekvencí řádově 7-8 tisíc párů bází, dostatečné k začlenění enzymů pro korekci základních chyb.
Jednoduchý matematický model
Vezměme si 3místnou molekulu [A, B, C], kde A, B a C mohou nabývat hodnot 0 a 1. Existuje osm takových sekvencí ([000], [001], [010], [011] , [100], [101], [110] a [111]). Řekněme, že nejvhodnější je molekula [000]; při každé replikaci vyprodukuje průměrně kopie, kde . Tato molekula se nazývá „hlavní sekvence“. Dalších sedm sekvencí je méně vhodných; každý produkuje pouze 1 kopii na replikaci. Replikace každé ze tří číslic se provádí s rychlostí mutace μ. Jinými slovy, při každé replikaci číslice sekvence existuje pravděpodobnost že to bude chybné; 0 bude nahrazeno 1 nebo naopak. Ignorujme dvojité mutace a smrt molekul (populace poroste nekonečně) a rozdělme osm molekul do tří tříd v závislosti na jejich Hammingova vzdálenost z hlavní sekvence:



Hamming
vzdálenostSekvence 0 [000] 1 [001]
[010]
[100]2 [110]
[101]
[011]3 [111]
Všimněte si, že počet sekvencí pro vzdálenost d je jen binomický koeficient pro L = 3 a že každou sekvenci lze vizualizovat jako vrchol dimenzionální krychle L = 3, přičemž každá hrana krychle určuje cestu mutace, ve které je změna Hammingovy vzdálenosti buď nula, nebo ± 1. Je vidět, že například jedna třetina mutací molekul bude [0001] produkovat molekuly, zatímco další dvě třetiny budou produkovat molekuly třídy 2 [011] a [101]. Nyní můžeme napsat výraz pro dětské populace třídy i z hlediska mateřské populace .




kde matice 'w„Který zahrnuje přirozený výběr a mutaci model quasispecies, darováno:

kde je pravděpodobnost, že celá molekula bude úspěšně replikována. The vlastní vektory z w matice získá rovnovážné počty populace pro každou třídu. Například pokud je rychlost mutace μ nula, budeme mít Q = 1 a rovnovážné koncentrace budou . Hlavní sekvence, která bude nejvhodnější, bude jediná, která přežije. Pokud máme replikační věrnost Q = 0,95 a genetickou výhodu a = 1,05, pak budou rovnovážné koncentrace zhruba . Je vidět, že hlavní sekvence není tak dominantní; nicméně sekvence s nízkou Hammingovou vzdáleností jsou většinou. Pokud máme věrnost replikace Q blížící se 0, pak budou rovnovážné koncentrace zhruba . Toto je populace se stejným počtem každé z 8 sekvencí. (Pokud bychom měli dokonale stejnou populaci všech sekvencí, měli bychom populace [1,3,3,1] / 8.)

![[n_ {0}, n_ {1}, n_ {2}, n_ {3}] = [1,0,0,0]](https://wikimedia.org/api/rest_v1/media/math/render/svg/2b77707e33cb921bda49ec8653444ef681c57cf4)
![[0.33,0.38,0.24,0.06]](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1a0d8e9ac1cf04d4831f3f9f5ef4c5e15ad75bc)
![[0.125,0.375,0.375,0.125]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9d99733a62ed1458e1d1225b3f851bc52ee98496)
Pokud nyní přejdeme k případu, kdy je počet párů bází velký, řekněme L = 100, získáme chování, které se podobá fázový přechod. Graf níže vlevo ukazuje řadu rovnovážných koncentrací děleno binomickým koeficientem . (Toto násobení ukáže populaci pro jednotlivou sekvenci v této vzdálenosti a přinese rovnou čáru pro rovnoměrné rozdělení.) Selektivní výhoda hlavní sekvence je nastavena na a = 1,05. Vodorovná osa je Hammingova vzdálenost d . Různé křivky jsou pro různé celkové rychlosti mutací . Je vidět, že pro nízké hodnoty celkové rychlosti mutace tvoří populaci a kvazidruhy shromáždili v sousedství hlavní sekvence. Nad celkovou rychlostí mutace asi 1-Q = 0,05 se distribuce rychle rozšíří a naplní všechny sekvence rovnoměrně. Graf níže vpravo ukazuje frakční populaci hlavní sekvence jako funkci celkové rychlosti mutace. Opět je vidět, že pod kritickou rychlostí mutace přibližně 1-Q = 0,05 obsahuje hlavní sekvence většinu populace, zatímco nad touto rychlostí obsahuje pouze přibližně z celkového počtu obyvatel.



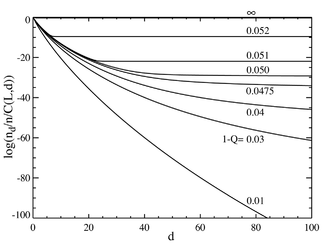

Je vidět, že dochází k prudkému přechodu při hodnotě 1-Q jen o něco větší než 0,05. U rychlostí mutací nad touto hodnotou populace hlavní sekvence klesne prakticky na nulu. Nad touto hodnotou dominuje.
V limitu jako L blíží se k nekonečnu, systém ve skutečnosti má fázový přechod na kritické hodnotě Q: . Dalo by se uvažovat o celkové rychlosti mutace (1-Q) jako o jakési „teplotě“, která „taví“ věrnost molekulárních sekvencí nad kritickou „teplotou“ . Aby došlo k věrné replikaci, musí být informace „zmrazena“ do genomu.


Viz také
Reference
- ^ Holmes, Edward C. (2009). Evoluce a vznik RNA virů. Oxford University Press. 22, 23, 48. ISBN 9780199211128. Citováno 1. února 2019.
- Eigen, M. (1971). "Selforganizace hmoty a vývoj biologických makromolekul". Naturwissenschaften. 58 (10): 465–523. Bibcode:1971NW ..... 58..465E. doi:10.1007 / BF00623322. PMID 4942363. S2CID 38296619.
- „Teorie kvazidruhů v kontextu populační genetiky - Claus O. Wilke“ (PDF). Citováno 12. října 2005.
- Campos, P. R. A .; Fontanari, J. F. (1999). "Škálování konečné velikosti přechodového prahu chyby v konečných populacích" (PDF). J. Phys. A: Math. Gen. 32: L1 – L7. arXiv:cond-mat / 9809209. Bibcode:1999JPhA ... 32L ... 1C. doi:10.1088/0305-4470/32/1/001. S2CID 16500591.
- Holmes, Edward C. (2005). „Má správnou velikost“. Genetika přírody. 37 (9): 923–924. doi:10.1038 / ng0905-923. PMC 7097767. PMID 16132047.
- Eörs Szathmáry; John Maynard Smith (1995). "Hlavní evoluční přechody". Příroda. 374 (6519): 227–232. Bibcode:1995 Natur.374..227S. doi:10.1038 / 374227a0. PMID 7885442. S2CID 4315120.
- Luis Villarreal; Guenther Witzany (2013). „Přehodnocení teorie kvazidruhů: Od nejvhodnějšího typu po kooperativní konsorcia“. World Journal of Biological Chemistry. 4 (4): 79–90. doi:10,4331 / wjbc.v4.i4.79. PMC 3856310. PMID 24340131.
- Ádám Kun; Mauro Santos; Eörs Szathmáry (2005). "Skutečné ribozymy naznačují uvolněný práh chyb". Genetika přírody. 37 (9): 1008–1011. doi:10.1038 / ng1621. PMID 16127452. S2CID 30582475.