INAVA - INAVA - Wikipedia




INAVA, někdy označované jako hypotetický protein LOC55765, je protein neznámé funkce, která je u lidí kódována INAVA gen.[5] Méně časté aliasy genů zahrnují FLJ10901 a MGC125608.
Gen
Umístění

U lidí se INAVA nachází na dlouhém rameni chromozom 1 na místo 1q32.1. Zahrnuje od 200 891 499 do 200 915 736 (24 238 kb) v řetězci plus.[5]
Genové sousedství
INAVA je lemován receptorem 25 spřaženým s G proteinem (upstream) a maestro tepelně podobným členem rodiny 3 (MROH3P), predikovaným downstream pseudogenem. Ribozomální protein L34 pseudogen 6 (RPL34P6) je dále proti proudu a člen kinebinové rodiny 21B je dále proti směru.[5]
Promotér

Existuje sedm předpovězených promotorů pro INAVA a experimentální důkazy naznačují, že izoforma 1 a 2, nejběžnější izoformy, jsou transkribovány pomocí různých promotorů.[6] K předpovědi byl použit MatInspector, nástroj dostupný prostřednictvím Genomatix transkripční faktor vazebná místa v potenciálních promotorových oblastech. Transkripční faktory, u nichž se předpokládá, že zacílí na očekávaný promotor pro izoformu 1, jsou exprimovány v řadě tkání. Nejběžnějšími tkáněmi exprese jsou urogenitální systém, nervový systém a kostní dřeň. To se shoduje s údaji o expresi proteinu INAVA, který je vysoce exprimován v ledvinách a kostní dřeni.[7] Vpravo je zobrazen diagram předpovězené oblasti promotoru se zvýrazněnými vazebnými místy transkripčního faktoru. Faktory, u nichž se předpokládá, že se váží na promotorovou oblast izoformy 2, se liší a dvanáct z nejlepších dvaceti předpokládaných faktorů je exprimováno v krevních buňkách a / nebo tkáních kardiovaskulárního systému.
Výraz
C1orf106 je exprimován v široké škále tkání. Níže jsou uvedena data výrazů z profilů GEO. Stránky s nejvyšším vyjádřením jsou uvedeny v tabulce. Exprese je mírná v placentě, prostatě, varlatech, plicích, slinných žlázách a dendritických buňkách. Má nízký obsah v mozku, většině imunitních buněk, nadledvinách, děloze, srdci a adipocytech.[7] Data exprese z různých experimentů nalezená na GEO profilech naznačují, že exprese INAVA je up-regulována u několika druhů rakoviny, včetně: plic, vaječníků, kolorektálního karcinomu a prsu.

| Tkáň | Percentilní hodnost |
|---|---|
| B lymfocyty | 90 |
| Průdušnice | 89 |
| Kůže | 88 |
| Lidské bronchiální epiteliální buňky | 88 |
| Kolorektální adenokarcinom | 87 |
| Ledviny | 87 |
| Jazyk | 85 |
| Slinivka břišní | 84 |
| slepé střevo | 82 |
| Kostní dřeň | 80 |
mRNA
Izoformy
Z genu INAVA se produkuje devět domnělých izoforem, z nichž se předpokládá, že sedm kóduje proteiny.[8] Níže uvedené izoformy 1 a 2 jsou nejběžnějšími izoformami.
Isoforma 1, která je nejdelší, je přijímána jako kanonická izoforma. Obsahuje deset exonů, které kódují protein o délce 677 aminokyselin, v závislosti na zdroji. Některé zdroje uvádějí, že protein má pouze 663 aminokyselin v důsledku použití startovacího kodonu, který je čtyřicet dva nukleotidů po proudu. Podle NCBI byla tato izoforma předpovězena pouze výpočetně.[5] Může to být proto, že Kozakova sekvence obklopení downstream start kodonu je více podobné konsensuální Kozakově sekvenci, jak je ukázáno v tabulce níže. Softberry byl použit k získání sekvence předpokládané izoformy.[9] Isoform 2 je kratší kvůli zkrácenému N-konci. Obě izoformy mají alternativní polyadenylační místo.[8]

regulace miRNA
miRNA-24 byla identifikována jako a mikroRNA které by mohly potenciálně cílit na INAVA mRNA.[10] Vazebné místo, které se nachází v 5 'nepřekládaná oblast je ukázáno.
Protein
Obecné vlastnosti

Isoform 1, znázorněný níže, obsahuje doménu DUF3338, dvě oblasti s nízkou složitostí a oblast bohatou na prolin. Protein je bohatý na arginin a prolin a obsahuje nižší než průměrné množství asparaginu a hydrofobních aminokyselin, konkrétně fenylalaninu a isoleucinu.[11] Izoelektrický bod je 9,58 a molekulová hmotnost nemodifikovaného proteinu je 72,9 kdal.[12] Nepředpokládá se, že by protein měl N-koncový signální peptid, ale předpokládá se jaderné lokalizační signály (NLS) a bohatý na leucin jaderný exportní signál.[13][14][15]
Modifikace
Předpokládá se, že INAVA bude vysoce fosforylovaná.[16][17] Fosfoylační místa předpovězená programem PROSITE jsou uvedena v tabulce níže. Předpovědi NETPhos jsou znázorněny na obrázku. Každá čára ukazuje na předpokládané fosforylační místo a spojuje se s písmenem, které představuje buď serin (S), threonin (T) nebo tyrosin (Y).


Struktura
Předpokládá se, že spirálové cívky se rozprostírají od zbytků 130-160 a 200-260.[18] Předpokládalo se, že sekundární složení bude asi 60% náhodných cívek, 30% alfa šroubovic a 10% beta listů.[19]
Interakce
Proteiny, se kterými protein INAVA interaguje, nejsou dobře charakterizovány. Dolování textu důkazy naznačují, že INAVA může interagovat s následujícími proteiny: DNAJC5G, SLC7A13, PIEZO2, MUC19.[20] Experimentální důkazy z kvasinkového dvouhybridního screeningu naznačují, že protein INAVA interaguje s proteinem sigma 14-3-3, což je adaptorový protein.[21]
Homologie
INAVA je u obratlovců dobře konzervovaná, jak ukazuje následující tabulka. Sekvence byly získány z VÝBUCH[22] a BLAT.[23]
| Sekvence | Rod a druh | Běžné jméno | Přistoupení k NCBI | Délka (aa) | Sekvenční identita | Čas od divergence (Mya) | |
|---|---|---|---|---|---|---|---|
| * | C1orf106 | Homo sapiens | Člověk | NP_060735.3 | 667 | 100% | NA |
| * | C1orf106 | Macaca fascicularis | Krabí jíst makak | XP_005540414.1 | 703 | 97% | 29.0 |
| * | LOC289399 | Rattus norvegicus | Krysa norská | NP_001178750.1 | 667 | 86% | 92.3 |
| * | Předpokládaný C1orf106 homolog | Odobenus rosmarus divergens | Mrož | XP_004392787.1 | 672 | 85% | 94.2 |
| * | C1orf106-like | Loxodonta africana | Slon | XP_003410255.1 | 663 | 84% | 98.7 |
| * | Předpokládaný C1orf106 homolog | Dasypus novemcinctus | Pásovec devítipásý | XP_004478752.1 | 676 | 81% | 104.2 |
| * | Předpokládaný C1orf106 homolog | Ochotona princeps | Americká pika | XP_004578841.1 | 681 | 78% | 92.3 |
| * | Předpokládaný C1orf106 homolog | Monodelphis domestica | Šedý vačice s krátkým ocasem | XP_001367913.2 | 578 | 76% | 162.2 |
| * | Předpokládaný C1orf106 homolog | Chrysemys picta bellii | Malovaná želva | XP_005313167.1 | 602 | 56% | 296.0 |
| * | Předpokládaný C1orf106 homolog | Geospiza fortis | Středně broušený finch | XP_005426868.1 | 542 | 50% | 296.0 |
| * | Předpokládaný C1orf106 homolog | Alligator mississippiensis | Aligátor | XP_006278041.1 | 547 | 49% | 296.0 |
| * | Předpokládaný C1orf106 homolog | Ficedula albicollis | Límeček černohlavý | XP_005059352.1 | 542 | 49% | 296.0 |
| Předpokládaný C1orf106 homolog | Latimeria chalumnae | Coelacanth západoindického oceánu | XP_005988436.1 | 613 | 46% | 414.9 | |
| * | Předpokládaný C1orf106 homolog | Lepisosteus oculatus | Skvrnitý gar | XP_006628420.1 | 637 | 44% | 400.1 |
| * | FERM doména obsahující 4A | Xenopus (Silurana) tropicalis | Západní drápá žába | XP_002935289.2 | 695 | 43% | 371.2 |
| * | Předpokládaný C1orf106 homolog | Oreochromis niloticus | Nilská tilapie | XP_005478188.1 | 576 | 40% | 400.1 |
| Předpokládaný C1orf106 homolog | Haplochromis burtoni | Astatotilapia burtoni | XP_005914919.1 | 576 | 40% | 400.1 | |
| Předpokládaný C1orf106 homolog | Pundamilia nyererei | Haplochromis nyererei | XP_005732720.1 | 577 | 40% | 400.1 | |
| * | LOC563192 | Danio rerio | Zebrafish | NP_001073474.1 | 612 | 37% | 400.1 |
| LOC101161145 | Oryzias latipes | Japonská rýžová ryba | XP_004069287.1 | 612 | 33% | 400.1 |
Níže je uveden graf sekvenční identity versus čas od divergence pro položky označené hvězdičkou. Barvy odpovídají stupni příbuznosti (zelená = úzce souvisí, fialová = vzdáleně souvisí).

Paralogy
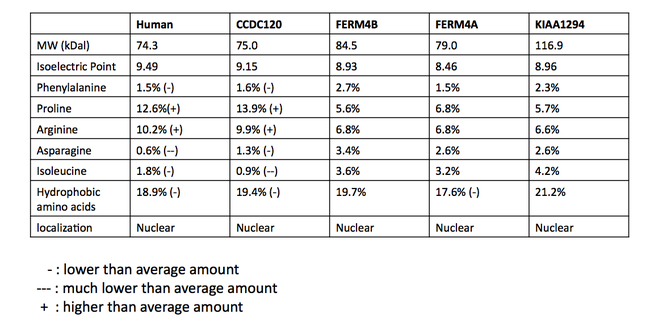
Proteiny, které jsou považovány za INAVA paralogy, nejsou mezi databázemi konzistentní. Bylo provedeno vícenásobné seřazení sekvencí (MSA) potenciálně paralogních proteinů, aby se určila pravděpodobnost skutečně paralogního vztahu.[24] Sekvence byly získány z vyhledávání BLAST u lidí s proteinem C1orf106. MSA navrhuje, aby proteiny sdílely homologní doménu DUF3338, která se nachází v eukaryotech. Část zarovnání více sekvencí je uvedena níže. Kromě domény DUF (označeno zelenou barvou) došlo k malé ochraně. Doména DUF3338 nemá žádné mimořádné fyzikální vlastnosti, jedním pozoruhodným zjištěním však je, že se předpokládá, že každý z proteinů v MSA bude mít dva jaderné lokalizační signály. Předpokládá se, že všechny proteiny v MSA se lokalizují do jádra.[13] Srovnání fyzikálních vlastností proteinů bylo také provedeno pomocí SAPS a je uvedeno v tabulce.[11]

Klinický význam
Celkem 556 jednonukleotidové polymorfismy (SNP) byly identifikovány v genové oblasti INAVA, z nichž 96 je spojeno s klinickým zdrojem.[25] Rivas a kol.[26] identifikoval čtyři SNP uvedené v tabulce níže, které mohou být spojeny s zánětlivé onemocnění střev a Crohnova nemoc. Podle GeneCards mohou zahrnovat další asociace chorob roztroušená skleróza a ulcerózní kolitida.[27]
| Zbytek | Změna | Poznámky |
|---|---|---|
| 333 (rs41313912) | Tyrosin ⇒ fenylalanin | Fosforylovaný, střední konzervace |
| 376 | Arginin ⇒ cystein | Mírná ochrana |
| 397 | Arginin ⇒ threonin | Nezachováno |
| 554 (rs61745433) | Arginin ⇒ cystein | Střední ochrana |
Modelové organismy
Modelové organismy byly použity při studiu funkce INAVA. Podmíněný knockout myš linka volala 5730559C18 Riktm2a (EUCOMM) Wtsi byl vygenerován na Wellcome Trust Sanger Institute.[28] Samci a samice prošli standardizací fenotypová obrazovka[29] k určení účinků vypuštění.[30][31][32][33] Další provedená vyšetření: - Hloubková imunologická fenotypizace[34] - hloubková fenotypizace kostí a chrupavek[35]
| Charakteristický | Fenotyp |
|---|---|
| Veškerá data jsou k dispozici na.[29][34][35] | |
| Leukocyty periferní krve 6 týdnů | Normální |
| Inzulín | Normální |
| Hematologie 6 týdnů | Normální |
| Homozygotní životaschopnost na P14 | Normální |
| Homozygotní plodnost | Normální |
| Tělesná hmotnost | Normální |
| Neurologické hodnocení | Normální |
| Síla úchopu | Normální |
| Dysmorfologie | Normální |
| Nepřímá kalorimetrie | Normální |
| Zkouška tolerance glukózy | Normální |
| Sluchová odezva mozkového kmene | Normální |
| DEXA | Normální |
| Radiografie | Normální |
| Morfologie očí | Normální |
| Klinická chemie | Normální |
| Hematologie 16 týdnů | Normální |
| Leukocyty periferní krve 16 týdnů | Normální |
| Váha srdce | Normální |
| Salmonella infekce | Normální |
| Cytotoxická funkce T buněk | Normální |
| Imunofenotypizace sleziny | Normální |
| Imunofenotypizace mezenterických lymfatických uzlin | Normální |
| Imunofenotypizace kostní dřeně | Normální |
| Epidermální imunitní složení | Normální |
| Chřipková výzva | Normální |
Reference
- ^ A b C GRCh38: Vydání souboru 89: ENSG00000163362 - Ensembl, Květen 2017
- ^ A b C GRCm38: Vydání souboru 89: ENSMUSG00000041605 - Ensembl, Květen 2017
- ^ „Human PubMed Reference:“. Národní centrum pro biotechnologické informace, Americká národní lékařská knihovna.
- ^ „Myš PubMed Reference:“. Národní centrum pro biotechnologické informace, Americká národní lékařská knihovna.
- ^ A b C d „NCBI Gene 55765“. Citováno 10. února 2014.
- ^ "Genomatix: MatInspector". Citováno 6. března 2014.
- ^ A b „Profily GEO“. Citováno 6. března 2014.
- ^ A b "Aceview". Citováno 6. března 2014.
- ^ "Softberry". Citováno 20. dubna 2014.
- ^ „TargetScanHuman 6.2“. Citováno 15. dubna 2014.
- ^ A b "Statistická analýza proteinových sekvencí". Citováno 20. dubna 2014.
- ^ "Nástroj pro výpočet pI / MW". Citováno 10. dubna 2014.
- ^ A b „PSORTII“. Citováno 20. dubna 2014.
- ^ „cNLS Mapper“. Citováno 20. dubna 2014.
- ^ „NetNES“. Citováno 20. dubna 2014.
- ^ „NETPhos“. Citováno 20. dubna 2014.
- ^ „Švýcarský institut bioinformatiky: PROSITE“.
- ^ „VÝBĚRNÉ CÍVKY“. Citováno 20. dubna 2014.
- ^ „SOPMA“. Citováno 27. dubna 2014.
- ^ "TĚTIVA". Citováno 15. dubna 2014.
- ^ "MÁTA". Citováno 15. dubna 2014.
- ^ "VÝBUCH". Citováno 8. března 2014.
- ^ „BLAT“. Citováno 8. března 2014.
- ^ „SDSC Biology Workbench: ClustalW“. Citováno 12. března 2014.
- ^ "dbSNP". Citováno 22. dubna 2014.
- ^ Rivas MA; et al. (2011). „Hluboké resekvenování lokusů GWAS identifikuje nezávislé vzácné varianty spojené se zánětlivým onemocněním střev“. Genetika přírody. 43 (11): 1066–1073. doi:10,1038 / ng.952. PMC 3378381. PMID 21983784.
- ^ „Genové karty“. Citováno 1. května 2014.
- ^ Gerdin AK (2010). „Genetický program Sanger Mouse: vysoká propustnost charakterizace knockoutovaných myší“. Acta Ophthalmologica. 88: 925–7. doi:10.1111 / j.1755-3768.2010.4142.x.
- ^ A b „Mezinárodní konsorcium pro fenotypizaci myší“.
- ^ Skarnes WC, Rosen B, West AP, Koutsourakis M, Bushell W, Iyer V, Mujica AO, Thomas M, Harrow J, Cox T, Jackson D, Severin J, Biggs P, Fu J, Nefedov M, de Jong PJ, Stewart AF, Bradley A (červen 2011). „Podmíněný knockoutový zdroj pro celogenomové studium funkce myšího genu“. Příroda. 474 (7351): 337–42. doi:10.1038 / příroda10163. PMC 3572410. PMID 21677750.
- ^ Dolgin E (červen 2011). „Knihovna myší je vyřazena“. Příroda. 474 (7351): 262–3. doi:10.1038 / 474262a. PMID 21677718.
- ^ Collins FS, Rossant J, Wurst W (leden 2007). "Myš ze všech důvodů". Buňka. 128 (1): 9–13. doi:10.1016 / j.cell.2006.12.018. PMID 17218247.
- ^ White JK, Gerdin AK, Karp NA, Ryder E, Buljan M, Bussell JN, Salisbury J, Clare S, Ingham NJ, Podrini C, Houghton R, Estabel J, Bottomley JR, Melvin DG, Sunter D, Adams NC, Sanger Institute Mouse Genetics Project, Tannahill D, Logan DW, Macarthur DG, Flint J, Mahajan VB, Tsang SH, Smyth I, Watt FM, Skarnes WC, Dougan G, Adams DJ, Ramirez-Solis R, Bradley A, Steel KP (2013) . „Generace v celém genomu a systematické fenotypování knockoutovaných myší odhaluje nové role mnoha genů“. Buňka. 154 (2): 452–64. doi:10.1016 / j.cell.2013.06.022. PMC 3717207. PMID 23870131.
- ^ A b „Konsorcium pro infekci a imunitu Imunofenotypizace (3i)“.
- ^ A b „OBCD Consortium“.
externí odkazy
- Člověk C1orf106 umístění genomu a C1orf106 stránka s podrobnostmi o genu v UCSC Genome Browser.