Tunstallské kódování - Tunstall coding - Wikipedia
v počítačová věda a teorie informace, Tunstallské kódování je forma entropické kódování používá bezztrátová komprese dat.
Dějiny
Programování Tunstall bylo předmětem disertační práce Briana Parkera Tunstalla v roce 1967, zatímco pracoval na Georgia Institute of Technology. Předmětem této práce byla „Syntéza bezhlučných kompresních kódů“ [1]
Jeho design je předchůdcem Lempel – Ziv.
Vlastnosti
Na rozdíl od kódy s proměnnou délkou, který zahrnuje Huffman a Kódování Lempel – Ziv, Tunstallské kódování je a kód který mapuje zdrojové symboly na pevný počet bitů.[2]
Kódy Tunstall i Lempel – Ziv představují slova s proměnnou délkou pomocí kódů s pevnou délkou.[3]
Na rozdíl od typické kódování sady, Tunstallovo kódování analyzuje stochastický zdroj s kódovými slovy proměnné délky.
Může se to ukázat[4]že pro dostatečně velký slovník může být počet bitů na zdrojové písmeno libovolně blízký , entropie zdroje.

Algoritmus
Algoritmus vyžaduje jako vstup vstupní abecedu , spolu s distribucí pravděpodobností pro každé slovní zadání. Vyžaduje také libovolnou konstantu , což je horní hranice velikosti slovníku, který bude počítat. Dotyčný slovník, , je konstruován jako strom pravděpodobností, ve kterém je každá hrana spojena s písmenem ze vstupní abecedy. Algoritmus zní takto:



D: = strom listy, jeden pro každé písmeno v .Zatímco : Převést nejpravděpodobnější list na strom pomocí listy.


Příklad
Tento článek může vyžadovat vyčištění setkat se s Wikipedií standardy kvality. Specifický problém je: špatné pravděpodobnosti (Srpna 2014) (Zjistěte, jak a kdy odstranit tuto zprávu šablony) |
Představme si, že si přejeme zakódovat řetězec „ahoj, svět“. Předpokládejme (poněkud nerealisticky), že vstupní abeceda obsahuje pouze znaky z řetězce „ahoj, svět“ - tedy „h“, „e“, „l“, „,“, „,„ w “,„ o “,„ r “,„ d “. Můžeme tedy vypočítat pravděpodobnost každého znaku na základě jeho statistického vzhledu ve vstupním řetězci. Například písmeno L se objeví třikrát v řetězci 12 znaků: jeho pravděpodobnost je .

Inicializujeme strom, počínaje stromem listy. Každé slovo je tedy přímo spojeno s písmenem abecedy. 9 slov, která takto získáme, lze zakódovat do výstupu pevné velikosti bity.


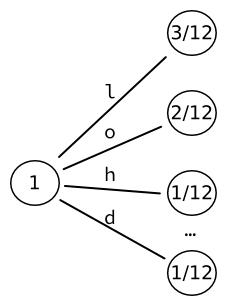
Poté vezmeme list s nejvyšší pravděpodobností (zde, ) a převést jej na další strom listy, jeden pro každý znak. Pravděpodobnosti těchto listů přepočítáme. Například sekvence dvou písmen L se stane jednou. Vzhledem k tomu, že existují tři výskyty písmen následovaných písmenem L, je výsledná pravděpodobnost .


Získáváme 17 slov, která lze zakódovat do výstupu pevné velikosti bity.

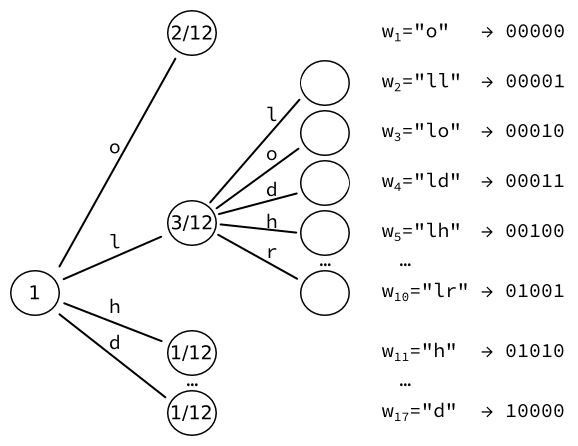
Všimněte si, že bychom mohli iterovat dále a zvýšit počet slov o pokaždé.

Omezení
Tunstallské kódování vyžaduje, aby algoritmus před operací syntézy věděl, jaké je rozdělení pravděpodobností pro každé písmeno abecedy. Huffmanovo kódování.
Jeho požadavek na výstup bloku s pevnou délkou je menší než Lempel – Ziv, který má podobný slovníkový design, ale s výstupem bloku proměnné velikosti.[je zapotřebí objasnění ]
Reference
- ^ Tunstall, Brian Parker (září 1967). Syntéza bezhlučných kompresních kódů. Gruzínský technologický institut.
- ^ http://www.rle.mit.edu/rgallager/documents/notes1.pdf „Studie Tunstallova algoritmu na MIT
- ^ "Adaptivní kódování zdroje s pevnou délkou - kódování Lempel-Ziv".[1][2]
- ^ [3] „Studie Tunstallova algoritmu z EPFL oddělení informační teorie
Komprese dat metody | |||||||
|---|---|---|---|---|---|---|---|
| Bezztrátový |
| ||||||
| Ztrátový |
| ||||||
| Zvuk |
| ||||||
| obraz |
| ||||||
| Video |
| ||||||
| Teorie | |||||||
| |||||||