Adaptivní Huffmanovo kódování - Adaptive Huffman coding
Adaptivní Huffmanovo kódování (také zvaný Dynamické Huffmanovo kódování) je adaptivní kódování technika založená na Huffmanovo kódování. Umožňuje vytváření kódu při přenosu symbolů, aniž by měl počáteční znalosti o distribuci zdroje, což umožňuje kódování jedním průchodem a přizpůsobení měnícím se podmínkám v datech.
Výhodou postupu s jedním průchodem je, že zdroj lze kódovat v reálném čase, i když se stává citlivější na chyby přenosu, protože pouze jedna ztráta zničí celý kód.
Algoritmy
Existuje řada implementací této metody, nejpozoruhodnější jsou FGK (Faller -Gallager -Knuth ) a Vitter algoritmus.
Algoritmus FGK
Jedná se o online kódovací techniku založenou na Huffmanově kódování. Bez počáteční znalosti frekvencí výskytu umožňuje dynamické přizpůsobování Huffmanova stromu během přenosu dat. Ve stromu FGK Huffmana se nazývá speciální externí uzel 0-uzel, se používá k identifikaci nově přicházející postavy. To znamená, že kdykoli narazíte na nová data, odešlete cestu k 0-uzlu následovanému daty. U postavy přicházející z minulosti stačí vygenerovat cestu k datům v aktuálním Huffmanově stromu. Nejdůležitější je, že v případě potřeby musíme upravit strom FGK Huffman a nakonec aktualizovat frekvenci souvisejících uzlů. Jak se zvyšuje frekvence nulového bodu, sourozenecký majetek Huffmanova stromu může být zlomena. Z tohoto důvodu se spustí úprava. Toho je dosaženo postupným zaměňováním uzlů, podstromů nebo obou. Datový uzel je zaměněn s nejlépe uspořádaným uzlem stejné frekvence v Huffmanově stromu (nebo podstromem zakořeněným v nejlépe uspořádaném uzlu). Všechny uzly předků uzlu by také měly být zpracovány stejným způsobem.
Vzhledem k tomu, že algoritmus FGK má určité nevýhody při výměně uzlů nebo podstromů, navrhl Vitter jiný algoritmus, který by jej vylepšil.
Vitterův algoritmus
Některé důležité terminologie a omezení: -
- Implicitní číslování : Jednoduše to znamená, že uzly jsou číslovány ve vzestupném pořadí podle úrovně a zleva doprava. tj. uzly na spodní úrovni budou mít nízký implicitní počet ve srovnání s uzly na vyšší úrovni a uzly na stejné úrovni jsou očíslovány ve vzestupném pořadí zleva doprava.
- Invariantní : Pro každou váhu w všechny listy váhy w předcházejí všechny vnitřní uzly, které mají váhu w.
- Bloky : Uzly stejné hmotnosti a stejného typu (tj. Uzel listu nebo vnitřní uzel) tvoří blok.
- Vůdce : Nejvyšší očíslovaný uzel v bloku.
Bloky jsou vzájemně propojeny zvyšováním pořadí jejich vah.
Blok listů vždy předchází vnitřnímu bloku stejné hmotnosti, čímž udržuje invariant.
NYT (dosud nepřeneseno) je speciální uzel a představuje symboly, které jsou ‚dosud nepřeneseno '.








algoritmus pro přidání symbolu je leaf_to_increment: = NULL p: = ukazatel na listový uzel obsahující další symbol -li (p je NYT) pak Rozšířit p přidáním dvou dětí Levé dítě se stane novým NYT a pravé dítě je nový uzel listu symbolu str : = rodič nového symbolu listový uzel leaf_to_increment: = Right Child of p jiný Zaměňte p za vůdce jeho bloku -li (nový p je sourozenec NYT) pak leaf_to_increment: = str str : = rodič p zatímco (p ≠ NULL) dělat Slide_And_Increment (p) -li (leaf_to_increment! = NULL) pak Slide_And_Increment (leaf_to_increment)
funkce Slide_And_Increment (p) je previous_p: = rodič z str -li (p je interní uzel) pak Posuňte p na stromě výše než listové uzly hmotnosti wt + 1 zvýšení hmotnosti str o 1 str : = předchozí_p jiný Posuňte p ve stromu výše než vnitřní uzly hmotnosti wt zvýší váhu str o 1 str : = nový rodič str.
Kodér a dekodér začínají pouze kořenovým uzlem, který má maximální počet. Na začátku je to náš počáteční NYT uzel.
Když vysíláme symbol NYT, musíme přenášet kód pro uzel NYT, poté pro jeho obecný kód.
U každého symbolu, který je již ve stromu, musíme přenášet pouze kód pro jeho listový uzel.
Příklad
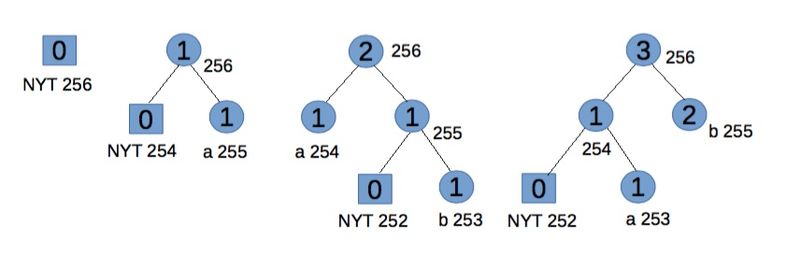
Kódování „abb“ dává 01100001 001100010 11.
Krok 1:
Začněte s prázdným stromem.
Pro „a“ předejte svůj binární kód.
Krok 2:
NYT založí dva podřízené uzly: 254 a 255, oba s váhou 0. Zvýšení váhy pro root a 255. Kód pro „a“ přidružený k uzlu 255 je 1.
Pro "b" vysílejte 0 (pro uzel NYT) pak jeho binární kód.
Krok 3:
NYT založí dva podřízené uzly: 252 pro NYT a 253 pro listový uzel, oba s váhou 0. Zvyšte váhy pro 253, 254 a root. Chcete-li zachovat Vitterův invariant, že všechny listy váhy w předcházejí (v implicitním číslování) všem vnitřním uzlům váhy w, větev začínající uzlem 254 by měla být zaměněna (z hlediska symbolů a vah, ale ne pořadí čísel) s uzlem 255. Kód pro „b“ je 11.
Pro druhé "b" vysílejte 11.
Pro usnadnění vysvětlení tento krok přesně nenasleduje Vitterův algoritmus,[1] ale účinky jsou rovnocenné.
Krok 4:
Přejít na listový uzel 253. Všimněte si, že máme dva bloky s váhou 1. Uzel 253 a 254 je jeden blok (skládající se z listů), uzel 255 je další blok (skládající se z vnitřních uzlů). U uzlu 253 je největší počet v jeho bloku 254, proto vyměňte váhy a symboly uzlů 253 a 254. Nyní uzel 254 a větev začínající od uzlu 255 splňují podmínku SlideAndIncrement[1] a proto musí být vyměněn. Nakonec zvětšete váhu uzlu 255 a 256.
Budoucí kód pro „b“ je 1 a pro „a“ je nyní 01, což odráží jejich frekvenci.
Reference
- ^ A b „Adaptivní Huffmanovo kódování“. Cs.duke.edu. Citováno 2012-02-26.
- Vitterův původní papír: J. S. Vitter, “Návrh a analýza dynamických Huffmanových kódů ", Journal of the ACM, 34 (4), říjen 1987, str. 825–845.
- J. S. Vitter, „ALGORITHM 673 Dynamic Huffman Coding“, ACM Transactions on Mathematical Software, 15 (2), červen 1989, str. 158–167. Objeví se také v Collected Algorithms of ACM.
- Donald E. Knuth, „Dynamic Huffman Coding“, Journal of Algorithm, 6 (2), 1985, str. 163–180.
externí odkazy
 Tento článek zahrnuje public domain materiál zNIST dokument:Černý, Paul E. „adaptivní Huffmanovo kódování“. Slovník algoritmů a datových struktur.
Tento článek zahrnuje public domain materiál zNIST dokument:Černý, Paul E. „adaptivní Huffmanovo kódování“. Slovník algoritmů a datových struktur.- Stránka Dan Hirschberg z University of California
- Stránka Dr. David Marshall z Cardiffské univerzity
- C implementace Vitterova algoritmu
- Vynikající popis z Duke University
Komprese dat metody | |||||||
|---|---|---|---|---|---|---|---|
| Bezztrátový |
| ||||||
| Ztrátový |
| ||||||
| Zvuk |
| ||||||
| obraz |
| ||||||
| Video |
| ||||||
| Teorie | |||||||
| |||||||