Algoritmus Rete - Rete algorithm
tento článek potřebuje další citace pro ověření. (Březen 2018) (Zjistěte, jak a kdy odstranit tuto zprávu šablony) |
The Algoritmus Rete (/ˈriːtiː/ REE- o, /ˈreɪtiː/ PAPRSEK- o, zřídka /ˈriːt/ REET, /rɛˈteɪ/ rehabilitaceTAY ) je porovnávání vzorů algoritmus pro implementaci systémy založené na pravidlech. Algoritmus byl vyvinut k efektivní aplikaci mnoha aplikací pravidla nebo vzory mnoha objektů, nebo fakta, v znalostní báze. Používá se k určení, která z pravidel systému by se měla spustit na základě jeho datového úložiště, jeho skutečností. Algoritmus Rete navrhl Charles L. Forgy z Univerzita Carnegie Mellon, nejprve publikován v pracovním dokumentu v roce 1974, a později rozpracován v jeho 1979 Ph.D. práce a práce z roku 1982 [1].
Přehled
A naivní implementace z expertní systém může zkontrolovat každý pravidlo proti známému fakta v znalostní báze, v případě potřeby toto pravidlo aktivovat, poté přejít k dalšímu pravidlu (a po dokončení se vrátit k prvnímu pravidlu). U dokonce středně velkých pravidel a znalostních bází faktů funguje tento naivní přístup příliš pomalu. Algoritmus Rete poskytuje základ pro efektivnější implementaci. Expertní systém založený na Rete buduje síť uzly, kde každý uzel (kromě kořene) odpovídá vzoru vyskytujícímu se na levé straně (podmínková část) pravidla. Cesta z kořenový uzel do a listový uzel definuje úplné pravidlo na levé straně. Každý uzel má paměť faktů, které tento vzorec splňují. Tato struktura je v zásadě zobecněná trie. Jak se nová fakta prosazují nebo upravují, šíří se po síti, což způsobí, že uzly budou anotovány, když se tato skutečnost shoduje s tímto vzorem. Když fakt nebo kombinace faktů způsobí, že budou splněny všechny vzorce pro dané pravidlo, je dosažen uzel listu a je spuštěno odpovídající pravidlo.
Rete byl poprvé použit jako hlavní motor OPS5 jazyk produkčního systému, který byl použit k vytvoření časných systémů, včetně R1 pro Digital Equipment Corporation. Rete se stalo základem mnoha populárních motorů pravidel a expertních systémových skořápek, včetně Tibco Obchodní akce, Newgen OmniRules, KLIPY, Jess, Slintá, Správa operačního rozhodnutí IBM, OPSJ, Blaze Advisor, BizTalk Pravidla Engine, Stoupat, Clara a Sparkling Logic SMARTS. Slovo „Rete“ je latinsky pro „net“ nebo „hřeben“. Stejné slovo se používá v moderní italštině síť. Charles Forgy údajně uvedl, že přijal termín „Rete“ kvůli jeho použití v anatomii k popisu sítě krevních cév a nervových vláken.[2]
Algoritmus Rete je navržen tak, aby obětoval Paměť pro zvýšenou rychlost. Ve většině případů je nárůst rychlosti oproti naivním implementacím několik řádů (protože výkon Rete je teoreticky nezávislý na počtu pravidel v systému). Ve velmi velkých expertních systémech má však původní algoritmus Rete tendenci narážet na problémy se spotřebou paměti a serveru. Od té doby byly navrženy další algoritmy, nové i založené na Rete, které vyžadují méně paměti (např. Rete *[3] nebo Collection Oriented Match[4]).
Popis
Algoritmus Rete poskytuje zobecněný logický popis implementace funkce odpovědné za shodu dat n-tice („fakta“) proti produkci („pravidla ") ve výrobním systému přizpůsobujícím se vzorům (kategorie pravidlo motoru ). Produkce se skládá z jedné nebo více podmínek a souboru akcí, které lze provést pro každou úplnou sadu faktů, které odpovídají podmínkám. Podmínky testu fakt atributy, včetně specifikátorů / identifikátorů typů faktů. Algoritmus Rete vykazuje následující hlavní charakteristiky:
- Snižuje nebo eliminuje určité typy redundance pomocí sdílení uzlů.
- Při provádění ukládá částečné shody připojí se mezi různými typy faktů. To zase umožňuje produkčním systémům vyhnout se úplnému přehodnocení všech faktů pokaždé, když dojde ke změnám v pracovní paměti produkčního systému. Místo toho produkční systém potřebuje pouze vyhodnotit změny (delty) pracovní paměti.
- Umožňuje efektivní odebrání paměťových prvků, když jsou fakta stažena z pracovní paměti.
Algoritmus Rete je široce používán k implementaci funkcí porovnávání v motorech porovnávání vzorů, které využívají cyklus podpory shody a řešení k podpoře dopředu řetězení a závěry.
- Poskytuje prostředky pro shodu mnoho-mnoho, což je důležitá funkce, když musí být nalezeno mnoho nebo všechna možná řešení ve vyhledávací síti.
Retes jsou směrované acyklické grafy které představují sady pravidel vyšší úrovně. Obecně jsou zastoupeny za běhu pomocí sítě objektů v paměti. Tyto sítě odpovídají podmínkám (vzorům) pravidel s fakty (n-tice relačních dat). Sítě Rete fungují jako typ procesoru relačních dotazů projekce, výběry a připojuje se podmíněně na libovolném počtu datových n-tic.
Produkce (pravidla) jsou obvykle zachyceny a definovány analytici a vývojáři pomocí některého jazyka pravidel na vysoké úrovni. Shromažďují se do sad pravidel, které se poté často za běhu překládají do spustitelného Rete.
Když se fakta „uplatní“ v pracovní paměti, vytvoří se motor prvky pracovní paměti (WME) pro každou skutečnost. Fakta jsou n-tice, a proto mohou obsahovat libovolný počet datových položek. Každá WME může obsahovat celou n-tici, nebo alternativně může být každá skutečnost představována sadou WME, kde každá WME obsahuje n-tici s pevnou délkou. V tomto případě jsou n-tice typicky triplety (3-n-tice).
Každý WME vstupuje do sítě Rete v jednom kořenovém uzlu. Kořenový uzel předává každý WME svým podřízeným uzlům a každý WME může být poté šířen sítí, případně může být uložen v mezipaměti, dokud nedorazí na koncový uzel.
Síť Alpha
Levá" (alfa) strana grafu uzlu tvoří diskriminační síť odpovědnou za výběr jednotlivých WME na základě jednoduchých podmíněných testů, které porovnávají atributy WME s konstantními hodnotami. Uzly v diskriminační síti mohou také provádět testy, které porovnávají dva nebo více atributů stejné WME. Pokud je WME úspěšně porovnán s podmínkami představovanými jedním uzlem, je předán dalšímu uzlu. Ve většině modulů se okamžité podřízené uzly kořenového uzlu používají k testování identifikátoru entity nebo typu faktu každého WME. Proto jsou všechny WME, které představují stejné subjekt typ obvykle prochází danou větev uzlů v diskriminační síti.
V rámci diskriminační sítě končí každá větev alfa uzlů (nazývaných také 1-vstupní uzly) v paměti zvané an alfa paměť. Tyto paměti ukládají kolekce WME, které odpovídají každé podmínce v každém uzlu v dané větvi uzlu. WME, kterým se ve větvi nepodaří splnit alespoň jednu podmínku, se v odpovídající alfa paměti neuskutečnily. Větve alfa uzlů se mohou rozvětvovat, aby se minimalizovala redundance podmínek.
Síť Beta
Právo" (beta) strana grafu provádí hlavně spojení mezi různými WME. Je volitelný a je zahrnut pouze v případě potřeby. Skládá se ze 2-vstupních uzlů, kde každý uzel má "levý" a "pravý" vstup. Každý uzel beta odesílá svůj výstup do a beta paměť.
V popisech Rete je běžné odkazovat na token procházející v beta síti. V tomto článku však popíšeme šíření dat, pokud jde o seznamy WME, nikoli o tokeny, v rozpoznávání různých možností implementace a základního účelu a použití tokenů. Protože kterýkoli ze seznamů WME prochází sítí beta, mohou být do ní přidány nové WME a seznam může být uložen do pamětí beta. Seznam WME v paměti beta představuje částečnou shodu s podmínkami v dané produkci.
Seznamy WME, které se dostanou na konec větve beta uzlů, představují úplnou shodu pro jednu produkci a jsou předávány koncovým uzlům. Tyto uzly se někdy nazývají p-uzly, kde „p“ znamená Výroba. Každý koncový uzel představuje jednu produkci a každý seznam WME, který dorazí do koncového uzlu, představuje úplnou sadu odpovídajících WME pro podmínky v dané produkci. Pro každý seznam WME, který obdrží, produkční uzel „aktivuje“ novou produkční instanci v „agendě“. Agendy jsou obvykle implementovány jako prioritní fronty.
Beta uzly obvykle provádějí spojení mezi seznamy WME uloženými v pamětí beta a jednotlivými WME uloženými v paměti alfa. Každý beta uzel je spojen se dvěma vstupními pamětí. Alfa paměť obsahuje WM a provádí „správné“ aktivace v beta uzlu pokaždé, když ukládá nový WME. Paměť beta uchovává seznamy WME a provádí „levou“ aktivaci v uzlu beta pokaždé, když uloží nový seznam WME. Když je uzel spojení aktivován vpravo, porovnává jeden nebo více atributů nově uloženého WME z jeho vstupní alfa paměti s danými atributy konkrétních WME v každém seznamu WME obsaženém ve vstupní beta paměti. Když je uzel připojení aktivován vlevo, prochází jeden nově uložený seznam WME v paměti beta a načte specifické hodnoty atributů daných WME. Porovnává tyto hodnoty s hodnotami atributů každého WME v alfa paměti.
Každý beta uzel vydává seznamy WME, které jsou buď uloženy v beta paměti, nebo odeslány přímo do koncového uzlu. Seznamy WME se ukládají do beta pamětí, kdykoli bude motor provádět další levé aktivace v následujících beta uzlech.
Logicky je beta uzel v čele větve beta uzlů zvláštním případem, protože nepřijímá žádný vstup z jakékoli beta paměti vyšší v síti. Různé motory řeší tento problém různými způsoby. Některé motory používají specializované uzly adaptéru k připojení pamětí alfa k levému vstupu uzlů beta. Jiné enginy umožňují beta uzlům přijímat vstup přímo ze dvou alfa pamětí, přičemž jeden považuje za „levý“ vstup a druhý za „pravý“ vstup. V obou případech „hlavní“ uzly beta přijímají vstup ze dvou alfa pamětí.
Za účelem vyloučení redundancí uzlů lze k provedení aktivace na více uzlech beta použít libovolnou alfa nebo beta paměť. Kromě připojení uzlů může beta síť obsahovat další typy uzlů, z nichž některé jsou popsány níže. Pokud Rete neobsahuje žádnou beta síť, tokeny kanálu alfa uzly, z nichž každý obsahuje jeden WME, přímo do p-uzlů. V takovém případě nemusí být potřeba ukládat WME do alfa pamětí.
Řešení konfliktů
Během kteréhokoli cyklu shody - řešení - akt vyhledávač vyhledá všechny možné shody pro fakta aktuálně uplatňovaná v pracovní paměti. Jakmile budou nalezeny všechny aktuální shody a budou aktivovány odpovídající produkční instance v agendě, stroj určí pořadí, ve kterém mohou být produkční instance "aktivovány". Toto se nazývá řešení konfliktůa seznam aktivovaných produkčních instancí se nazývá sada konfliktů. Objednávka může být založena na prioritě pravidla (nápadnost), pořadí pravidel, čas, kdy byla fakta obsažená v každém případě uplatněna na pracovní paměť, složitost každé produkce nebo některá další kritéria. Mnoho modulů umožňuje vývojářům pravidel vybrat si mezi různými strategiemi řešení konfliktů nebo zřetězit výběr více strategií.
Řešení konfliktů není definováno jako součást algoritmu Rete, ale je používáno společně s algoritmem. Některé specializované produkční systémy neprovádějí řešení konfliktů.
Provádění výroby
Po provedení řešení konfliktu motor nyní „vystřelí“ první produkční instanci a provede seznam akcí spojených s produkcí. Akce působí na data představovaná seznamem WME produkční instance.
Ve výchozím nastavení bude motor nadále spouštět každou produkční instanci v pořadí, dokud nebudou spuštěny všechny produkční instance. Každá produkční instance bude spuštěna maximálně jednou, během libovolného cyklu shody - řešení - akt. Tato vlastnost se nazývá lom světla. Sekvence spouštění produkčních instancí však může být přerušena v jakékoli fázi provedením změn v pracovní paměti. Akce pravidel mohou obsahovat pokyny k prosazení nebo stažení WME z pracovní paměti motoru. Pokaždé, když kterákoli jednotlivá produkční instance provede jednu nebo více takových změn, motor okamžitě vstoupí do nového cyklu shody-řešení-jednání. To zahrnuje „aktualizace“ WME aktuálně v pracovní paměti. Aktualizace jsou reprezentovány zatažením a opětovným uplatněním WME. Motor provádí porovnávání změněných dat, což může vést ke změnám v seznamu produkčních instancí v agendě. Proto po provedení akcí pro jednu konkrétní produkční instanci mohly být dříve aktivované instance deaktivovány a odstraněny z agendy a mohly být aktivovány nové instance.
V rámci nového cyklu zápas-řešení-akt provádí modul řešení konfliktů v agendě a poté provede aktuální první instanci. Motor pokračuje ve spouštění produkčních instancí a v zadávání nových cyklů porovnávání a řešení akcí, dokud v agendě neexistují žádné další produkční instance. V tomto okamžiku se pravidlo považuje za dokončené a zastaví se.
Některé motory podporují pokročilé refrakční strategie, při nichž se některé produkční instance provedené v předchozím cyklu znovu nevykonávají v novém cyklu, i když v agendě stále mohou existovat.
Je možné, že engine vstoupí do nekonečných smyček, ve kterých program nikdy nedosáhne prázdného stavu. Z tohoto důvodu většina motorů podporuje explicitní "zastavená" slovesa, která lze vyvolat ze seznamů produkčních akcí. Mohou také poskytovat automatické detekce smyčky ve kterém jsou nekonečné smyčky automaticky zastaveny po daném počtu iterací. Některé motory podporují model, ve kterém místo zastavení, když je program prázdný, motor přejde do stavu čekání, dokud nebudou externě uplatněna nová fakta.
Pokud jde o řešení konfliktů, aktivace aktivovaných produkčních instancí není funkcí algoritmu Rete. Je to však ústřední rys motorů, které používají sítě Rete. Některé z optimalizací nabízených sítěmi Rete jsou užitečné pouze ve scénářích, kdy stroj provádí několik cyklů shoda-řešení-jednání.
Existenční a univerzální kvantifikace
Podmíněné testy se nejčastěji používají k provádění výběrů a spojování jednotlivých n-tic. Implementací dalších typů uzlů beta je však možné, aby sítě Rete fungovaly kvantifikace. Existenční kvantifikace zahrnuje testování existence alespoň jedné sady odpovídajících WME v pracovní paměti. Univerzální kvantifikace zahrnuje testování, že celá sada WME v pracovní paměti splňuje danou podmínku. Varianta univerzální kvantifikace by mohla otestovat, že daný počet WME, čerpaný ze sady WME, splňuje uvedená kritéria. To může být z hlediska testování přesného počtu nebo minimálního počtu shod.
Kvantifikace není v motorech Rete implementována univerzálně a tam, kde je podporována, existuje několik variant. Varianta existenční kvantifikace označovaná jako negace je široce, i když ne všeobecně, podporován a je popsán v klíčových dokumentech. Existenciálně negované podmínky a spojky zahrnují použití specializovaných beta uzlů, které testují neexistenci odpovídajících WME nebo sad WME. Tyto uzly propagují seznamy WME pouze v případě, že není nalezena shoda. Přesná implementace negace se liší. V jednom přístupu uzel udržuje jednoduchý počet na každém seznamu WME, který obdrží ze svého levého vstupu. Počet určuje počet nalezených shod s WME přijatými ze správného vstupu. Uzel propaguje pouze seznamy WME, jejichž počet je nulový. V jiném přístupu uzel udržuje další paměť na každém seznamu WME přijatém z levého vstupu. Tyto paměti jsou formou paměti beta a ukládají seznamy WME pro každou shodu s WME přijatými na správném vstupu. Pokud seznam WME nemá ve své paměti žádné seznamy WME, šíří se po síti. V tomto přístupu negační uzly obecně aktivují přímo další beta uzly, místo aby ukládaly svůj výstup do další beta paměti. Negační uzly poskytují formu 'negace jako selhání '.
Když se provedou změny v pracovní paměti, seznam WME, který dříve odpovídal žádným WME, se nyní může shodovat s nově uplatněnými WME. V tomto případě je třeba rozšířený seznam WME a všechny jeho rozšířené kopie stáhnout z beta pamětí dále po síti. Druhý přístup popsaný výše se často používá k podpoře účinných mechanismů pro odstranění seznamů WME. Když jsou seznamy WME odstraněny, všechny odpovídající produkční instance jsou deaktivovány a odstraněny z agendy.
Existenciální kvantifikaci lze provést kombinací dvou negačních beta uzlů. To představuje sémantiku dvojitá negace (např. „Pokud NEJSOU žádné odpovídající WME, pak ...“). Toto je běžný přístup, který zaujímá několik produkčních systémů.
Indexování paměti
Algoritmus Rete nepožaduje žádný konkrétní přístup k indexování pracovní paměti. Většina moderních produkčních systémů však poskytuje mechanismy indexování. V některých případech jsou indexovány pouze beta paměti, zatímco v jiných se indexování používá pro alfa i beta paměti. Dobrá strategie indexování je hlavním faktorem při rozhodování o celkovém výkonu produkčního systému, zejména při provádění sad pravidel, jejichž výsledkem je vysoce kombinatorické porovnávání vzorů (tj. Intenzivní používání uzlů spojení beta), nebo u některých motorů při provádění pravidel sady, které provádějí značný počet stažení WME během několika cyklů zápas-řešení-čin. Paměti jsou často implementovány pomocí kombinací hash tabulek a hash hodnoty se používají k provádění podmíněných spojení na podmnožinách seznamů WME a WME, nikoli na celém obsahu pamětí. To zase často významně snižuje počet hodnocení prováděných sítí Rete.
Odstranění WME a seznamů WME
Když je WME stažen z pracovní paměti, musí být odstraněn z každé alfa paměti, ve které je uložen. Seznamy WME, které obsahují WME, musí být navíc odstraněny z pamětí beta a aktivované produkční instance pro tyto seznamy WME musí být deaktivovány a odstraněny z agendy. Existuje několik variant implementace, včetně odstraňování na základě stromů a rematchů. V některých případech lze k optimalizaci odebrání použít indexování paměti.
Manipulace s podmínkami ORed
Při definování produkcí v sadě pravidel je běžné povolit seskupení podmínek pomocí OR spojovací. V mnoha produkčních systémech je to řešeno interpretací jedné produkce obsahující více vzorů ORed jako ekvivalent více produkcí. Výsledná síť Rete obsahuje sady koncových uzlů, které společně představují jednotlivé produkce. Tento přístup zakazuje jakoukoli formu zkratu podmínek ORED. Může také v některých případech vést k aktivaci duplicitních produkčních instancí v agendě, kde stejná sada WME odpovídá více interním produkcím. Některé nástroje zajišťují odstranění problému s agendou.
Diagram
Následující diagram ilustruje základní topografii Rete a ukazuje přidružení mezi různými typy uzlů a pamětí.
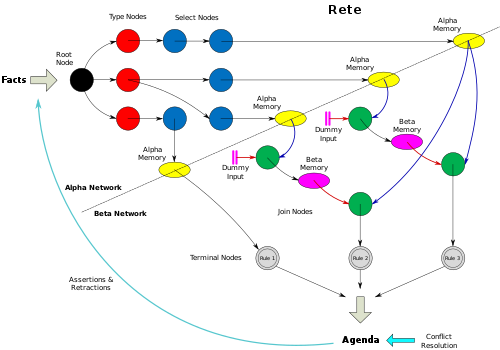
- Většina implementací používá uzly typu k provedení první úrovně výběru prvků n-tice pracovní paměti. Uzly typu lze považovat za specializované vybrané uzly. Rozlišují mezi různými typy relací n-tice.
- Diagram neilustruje použití specializovaných typů uzlů, jako jsou uzly s negovanou spojkou. Některé motory implementují několik různých specializací uzlů, aby rozšířily funkčnost a maximalizovaly optimalizaci.
- Diagram poskytuje logický pohled na Rete. Implementace se mohou lišit ve fyzických detailech. Diagram konkrétně ukazuje fiktivní vstupy poskytující správné aktivace v čele větví beta uzlu. Motory mohou implementovat další přístupy, například adaptéry, které umožňují alfa pamětím přímo provádět správné aktivace.
- Diagram neilustruje všechny možnosti sdílení uzlů.
Podrobnější a úplnější popis algoritmu Rete najdete v kapitole 2 Produkce shody pro velké výukové systémy od Roberta Doorenbose (viz odkaz níže).
Alternativy
Síť Alpha
Možnou variantou je zavedení dalších pamětí pro každý mezilehlý uzel v diskriminační síti. To zvyšuje režii Rete, ale může to mít výhody v situacích, kdy jsou pravidla dynamicky přidávána nebo odstraňována z Rete, což usnadňuje dynamickou změnu topologie diskriminační sítě.
Alternativní implementaci popisuje Doorenbos.[5] V tomto případě je diskriminační síť nahrazena sadou pamětí a indexem. Index lze implementovat pomocí a hash tabulka. Každá paměť obsahuje WME, které odpovídají jedinému podmíněnému vzoru, a index se používá k odkazování na paměti podle jejich vzoru. Tento přístup je praktický, pouze když WME představují n-tice pevné délky a délka každé n-tice je krátká (např. 3-n-tice). Tento přístup se navíc vztahuje pouze na podmíněné vzory, které fungují rovnost testy proti konstantní hodnoty. Když WME vstoupí na Rete, použije se index k vyhledání sady pamětí, jejichž podmíněný vzor odpovídá atributům WME, a WME se poté přidá přímo do každé z těchto pamětí. Samo o sobě tato implementace neobsahuje žádné 1-vstupní uzly. Aby však bylo možné implementovat testy nerovnosti, může Rete obsahovat další 1-vstupní sítě uzlů, kterými jsou před umístěním do paměti předávány WME. Alternativně mohou být testy nerovnosti prováděny v beta verzi popsané níže.
Síť Beta
Běžnou variantou je stavět propojené seznamy tokenů, kde každý token obsahuje jeden WME. V tomto případě jsou seznamy WME pro částečnou shodu reprezentovány propojeným seznamem tokenů. Tento přístup může být lepší, protože eliminuje potřebu kopírovat seznamy WME z jednoho tokenu do druhého. Místo toho musí uzel beta pouze vytvořit nový token, který bude obsahovat WME, který si přeje připojit k seznamu částečných shod, a poté nový token propojit s nadřazeným tokenem uloženým ve vstupní paměti beta. Nový token nyní tvoří hlavu seznamu tokenů a je uložen ve výstupní beta paměti.
Beta uzly zpracovávají tokeny. Token je jednotka úložiště v paměti a také jednotka výměny mezi paměti a uzly. V mnoha implementacích se tokeny zavádějí do alfa pamětí, kde se používají k uložení jednotlivých WME. Tyto tokeny jsou poté předány do sítě beta.
Každý beta uzel vykonává svoji práci a jako výsledek může vytvářet nové tokeny, které obsahují seznam WME představujících částečnou shodu. Tyto rozšířené tokeny se poté uloží do beta pamětí a předají se dalším uzlům beta. V tomto případě beta uzly obvykle předávají seznamy WME prostřednictvím sítě beta kopírováním existujících seznamů WME z každého přijatého tokenu do nových tokenů a následným přidáním dalších WME do seznamů v důsledku provedení spojení nebo jiné akce. Nové tokeny se poté uloží do výstupní paměti.
Různé úvahy
Ačkoli to není definováno algoritmem Rete, některé motory poskytují rozšířené funkce, které podporují lepší kontrolu nad udržování pravdy. Například když je nalezena shoda pro jednu produkci, může to mít za následek uplatnění nových WME, které zase odpovídají podmínkám pro jinou produkci. Pokud následná změna pracovní paměti způsobí, že se první shoda stane neplatnou, může to znamenat, že to znamená, že druhá shoda je také neplatná. Algoritmus Rete nedefinuje žádný mechanismus k jejich definování a zpracování logická pravda závislosti automaticky. Některé motory však podporují další funkce, ve kterých lze automaticky udržovat závislosti na pravdě. V tomto případě může stažení jedné WME vést k automatickému stažení dalších WME, aby byla zachována logická tvrzení pravdy.
Algoritmus Rete nedefinuje žádný přístup k ospravedlnění. Odůvodnění odkazuje na mechanismy běžně vyžadované v expertních a rozhodovacích systémech, v nichž systém v nejjednodušším případě hlásí každé z vnitřních rozhodnutí použitých k dosažení určitého konečného závěru. Například expertní systém může ospravedlnit závěr, že zvíře je slon, a to oznámením, že je velké, šedé, má velké uši, kmen a kly. Některé motory poskytují integrované systémy zarovnání ve spojení s implementací algoritmu Rete.
Tento článek neposkytuje vyčerpávající popis všech možných variant nebo rozšíření algoritmu Rete. Existují i další úvahy a inovace. Například motory mohou poskytovat specializovanou podporu v rámci sítě Rete za účelem použití zpracování pravidel porovnávání vzorů na konkrétní typy dat a zdroje jako programové objekty, XML data nebo tabulky relačních dat. Další příklad se týká dalších časových razítek poskytovaných mnoha motory pro každý WME vstupující do sítě Rete a použití těchto časových razítek ve spojení se strategiemi řešení konfliktů. Motory vykazují značné rozdíly ve způsobu, jakým umožňují programový přístup k motoru a jeho pracovní paměti, a mohou rozšířit základní model Rete tak, aby podporoval formy paralelního a distribuovaného zpracování.
Optimalizace a výkon
V akademické literatuře bylo identifikováno a popsáno několik optimalizací pro Rete. Několik z nich však platí pouze ve velmi konkrétních scénářích, a proto mají často malou nebo žádnou aplikaci ve stroji s obecnými pravidly. Kromě toho alternativní algoritmy, jako je TREAT, vyvinuté Daniel P. Miranker[6] Byly formulovány LEAPS a Design Time Inferencing (DeTI), které mohou poskytnout další vylepšení výkonu.
Algoritmus Rete je vhodný pro scénáře, kde se pro výpočet nových faktů ze stávajících faktů nebo pro filtrování a vyřazení faktů, aby se dospělo k nějakému závěru, používá dopředné řetězení a „odvozování“. Využívá se také jako přiměřeně efektivní mechanismus pro provádění vysoce kombinatorických hodnocení faktů, kde mezi n-ticemi faktů musí být provedeno velké množství spojení. Jiné přístupy k provádění vyhodnocení pravidel, například použití rozhodovací stromy, nebo implementace sekvenčních motorů, může být vhodnější pro jednoduché scénáře a mělo by být považováno za možnou alternativu.
Výkon Rete je také do značné míry záležitostí volby implementace (nezávisle na topologii sítě), z nichž jedna (použití hash tabulek) vede k významným vylepšením. Většina výkonnostních měřítek a srovnání dostupných na webu je nějakým způsobem ovlivněna nebo jiný. Zmínit jen časté zaujatost a nespravedlivý typ srovnání: 1) používání problémů s hračkami, jako jsou příklady Manners a Waltz; takové příklady jsou užitečné pro odhad konkrétních vlastností implementace, ale nemusí odrážet skutečný výkon složitých aplikací; 2) použití staré implementace; například odkazy v následujících dvou částech (Rete II a Rete-NT) porovnávají některé komerční produkty se zcela zastaralými verzemi CLIPS a tvrdí, že komerční produkty mohou být řádově rychlejší než CLIPS; to zapomíná, že CLIPS 6.30 (se zavedením hash tabulek jako v Rete II) je řádově rychlejší než verze použitá pro srovnání (CLIPS 6.04).
Varianty
Rete II
V 80. letech Charles Forgy vyvinul nástupce pojmenovaného algoritmu Rete Rete II.[7] Na rozdíl od původního Rete (který je public domain) nebyl tento algoritmus zveřejněn. Rete II požaduje lepší výkon pro složitější problémy (dokonce i řádové[8]), a je oficiálně implementován v CLIPS / R2, implementaci C / ++ a v OPSJ, implementaci Java v roce 1998. Rete II poskytuje zlepšení výkonu o 100 až 1 řád ve složitějších problémech, jak ukazuje KnowledgeBased Systems Corporation[9] měřítka.
Rete II lze charakterizovat dvěma oblastmi zlepšení; konkrétní optimalizace týkající se obecného výkonu sítě Rete (včetně použití hašovaných pamětí za účelem zvýšení výkonu s většími soubory dat) a zahrnutí zpětné řetězení algoritmus přizpůsobený tak, aby běžel na vrcholu sítě Rete. Samotné zpětné řetězení může odpovídat za nejextrémnější změny v benchmarcích týkajících se Rete vs. Rete II. Rete II je implementován v komerčním produktu Advisor od FICO, dříve nazývaného Fair Isaac [10]
Jess (alespoň verze 5.0 a novější) také přidává komerční algoritmus zpětného zřetězení na síť Rete, ale nelze říci, že plně implementuje Rete II, částečně kvůli skutečnosti, že veřejně není k dispozici žádná úplná specifikace.
Rete-III
Na začátku roku 2000 vyvinul motor Rete III Charles Forgy ve spolupráci s inženýry FICO. Algoritmus Rete III, který není Rete-NT, je ochrannou známkou FICO pro Rete II a je implementován jako součást modulu FICO Advisor. Je to v podstatě motor Rete II s API, který umožňuje přístup k motoru Advisor, protože motor Advisor může přistupovat k dalším produktům FICO.[11]
Rete-NT
V roce 2010 společnost Forgy vyvinula novou generaci algoritmu Rete. V benchmarku InfoWorld byl algoritmus považován za 500krát rychlejší než původní algoritmus Rete a 10krát rychlejší než jeho předchůdce Rete II.[12] Tento algoritmus je nyní licencován společnosti Sparkling Logic, společnosti, ke které se Forgy připojil jako investor a strategický poradce,[13][14] jako odvozovací modul produktu SMARTS.
Viz také
Reference
- ^ Charles Forgy: Rete: Rychlý algoritmus pro řešení problému Mnoho vzorů / Mnoho vzorů objektů. In: Artificial Intelligence, sv. 19, s. 17–37, 1982.
- ^ „Rete Algorithm Demystified! - Part 1“ Carole-Ann Matignon
- ^ Ian Wright; James Marshall. „Execution Kernel of RC ++: RETE * a Faster Rete with TREAT as a Special Case“ (PDF). Archivovány od originál (PDF) dne 2004-07-25. Citováno 2013-09-13.
- ^ Anurag Acharya; Milind Tambe. „Shoda s kolekcí (PDF). CIKM '93 Sborník z druhé mezinárodní konference o řízení informací a znalostí. doi:10.1145/170088.170411. Archivovány od originál (PDF) dne 18.03.2012.
- ^ Výroba odpovídající velkým vzdělávacím systémům ze SCS Technical Report Collection, School of Computer Science, Carnegie Mellon University
- ^ http://dl.acm.org/citation.cfm?id=39946 „TREAT: nový a efektivní algoritmus shody pro produkční systémy AI“
- ^ RETE2 od Production Systems Technologies
- ^ Benchmarking CLIPS / R2 od Production Systems Technologies
- ^ KBSC
- ^ http://dmblog.fico.com/2005/09/what_is_rete_ii.html
- ^ http://dmblog.fico.com/2005/09/what_is_rete_ii.html
- ^ Owen, James (2010-09-20). "Nejrychlejší motor pravidel na světě | Systémy správy obchodních pravidel". InfoWorld. Citováno 2012-04-07.
- ^ „Je to oficiální, Dr. Charles Forgy se připojuje k Sparkling Logic jako strategický poradce“. PR.com. 2011-10-31. Citováno 2012-04-07.
- ^ „Dr. Charles Forgy, PhD“. www.sparklinglogic.com. Citováno 2012-04-07.
Tento článek obsahuje seznam obecných Reference, ale zůstává z velké části neověřený, protože postrádá dostatečné odpovídající vložené citace. (Srpna 2011) (Zjistěte, jak a kdy odstranit tuto zprávu šablony) |
- Charles Forgy, "Síťová rutina shody pro produkční systémy." Working Paper, 1974.
- Charles Forgy, “„O efektivní implementaci produkčních systémů.“ Ph.D. Diplomová práce, Carnegie-Mellon University, 1979.
- Charles, Forgy (1982). "Rete: Rychlý algoritmus pro problém Mnoho vzorů / Mnoho vzorů objektů". Umělá inteligence. 19: 17–37. doi:10.1016/0004-3702(82)90020-0.
externí odkazy
- Rete Algorithm vysvětlil Bruce Schneier, Dr. Dobb's Journal
- Odpovídající výroba pro velké výukové systémy - R Doorenbos Podrobný a přístupný popis Rete, také popisuje variantu s názvem Rete / UL, optimalizovanou pro velké systémy (PDF)
- Podle pravidel (Krátký úvod od cut-the-uzel )