Prioritní fronta - Priority queue - Wikipedia
v počítačová věda, a prioritní fronta je abstraktní datový typ podobný běžnému fronta nebo zásobník datová struktura, ve které má každý prvek navíc přidruženou „prioritu“. V prioritní frontě je prvek s vysokou prioritou obsluhován před prvkem s nízkou prioritou. V některých implementacích, pokud mají dva prvky stejnou prioritu, jsou obsluhovány podle pořadí, ve kterém byly zařazeny, zatímco v jiných implementacích je pořadí prvků se stejnou prioritou nedefinováno.
Zatímco prioritní fronty jsou často implementovány s hromady, jsou koncepčně odlišné od hromad. Fronta priorit je koncept jako „a seznam „nebo“ a mapa "; stejně jako lze seznam implementovat pomocí spojový seznam nebo pole, prioritní fronta může být implementována hromadou nebo řadou dalších metod, jako je neuspořádané pole.
Operace
Fronta priority musí podporovat alespoň následující operace:
- je prázdný: zkontrolujte, zda fronta neobsahuje žádné prvky.
- insert_with_priority: přidat živel do fronta s přidruženou prioritou.
- pull_highest_priority_element: odebrat prvek z fronty, která má Nejvyšší prioritoua vrátit jej.
- Toto se také nazývá „pop_element (vypnuto)", "get_maximum_element„nebo“get_front (most) _element".
- Některé konvence mění pořadí priorit a považují nižší hodnoty za vyšší priority, takže to může být známé také jako „get_minimum_element„a často se označuje jako„dostat-min" v literatuře.
- To může být místo toho specifikováno jako samostatné "peek_at_highest_priority_element" a "delete_element"funkce, které lze kombinovat k výrobě"pull_highest_priority_element".
Navíc, nahlédnout (v této souvislosti se často nazývá najít-max nebo najít-min), který vrací prvek s nejvyšší prioritou, ale nezmění frontu, je velmi často implementován a téměř vždy se provádí v Ó(1) čas. Tato operace a její Ó(1) výkon je zásadní pro mnoho aplikací prioritních front.
Pokročilejší implementace mohou podporovat složitější operace, například pull_lowest_priority_element, kontrola prvních několika prvků s nejvyšší nebo nejnižší prioritou, vyčištění fronty, vymazání podmnožin fronty, provedení dávkového vložení, sloučení dvou nebo více front do jedné, zvýšení priority libovolného prvku atd.
Lze si představit prioritní frontu jako upravenou fronta, ale když by někdo dostal další prvek z fronty, nejprve se načte prvek s nejvyšší prioritou.
Zásobníky a fronty lze modelovat jako konkrétní druhy prioritních front. Připomínáme, že zde se chovají hromádky a fronty:
- zásobník - prvky jsou vtaženy dovnitř last-in první-out - objednávka (např. stoh papírů)
- fronta - prvky jsou vtaženy dovnitř first-in first-out -řádek (např. linka v jídelně)
V zásobníku se priorita každého vloženého prvku monotónně zvyšuje; poslední vložený prvek je tedy vždy první načtený. Ve frontě se priorita každého vloženého prvku monotónně snižuje; tedy první vložený prvek je vždy první načtený.
Implementace
Naivní implementace
Existuje řada jednoduchých, obvykle neúčinných způsobů implementace prioritní fronty. Poskytují analogii, která člověku pomůže pochopit, co je to prioritní fronta.
Například je možné ponechat všechny prvky v netříděném seznamu ( Ó(1) doba vložení). Kdykoli je požadován prvek s nejvyšší prioritou, prohledejte všechny prvky pro prvek s nejvyšší prioritou. (Ó(n) doba tahu),
vložit(uzel) {list.append (uzel)}sem() {foreach node in list {if higher.priority V jiném případě je možné ponechat všechny prvky v seznamu seřazeném podle priority (Ó(n) čas řazení), kdykoli je požadován prvek s nejvyšší prioritou, může být vrácen první v seznamu. ( Ó(1) doba vytažení)
vložit(uzel) {foreach (index, element) v seznamu {if node.priority sem() {nejvyšší = list.get_at_index (list.length-1) list.remove (nejvyšší) návrat nejvyšší}Obvyklá implementace
Ke zlepšení výkonu prioritní fronty obvykle používají a halda jako jejich páteř, dávat Ó(log n) výkon pro vložky a vyjmutí a Ó(n) sestavit původně ze sady n elementy. Varianty základní haldy datové struktury, jako je párování hromad nebo Fibonacci se hromadí může poskytnout lepší hranice pro některé operace.[1]
Alternativně, když a samovyvažující binární vyhledávací strom je použito, také vložení a vyjmutí Ó(log n) čas, i když budování stromů ze stávajících sekvencí prvků trvá Ó(n log n) čas; to je typické tam, kde by člověk již mohl mít přístup k těmto datovým strukturám, například s knihovnami třetích stran nebo se standardními knihovnami.
Z hlediska výpočetní složitosti jsou prioritní fronty shodné s třídicími algoritmy. Sekce o ekvivalence prioritních front a třídicích algoritmů níže popisuje, jak efektivní třídicí algoritmy mohou vytvářet efektivní fronty priorit.
Specializované hromady
Existuje několik specializovaných halda datové struktury které buď dodávají další operace, nebo překonávají implementace založené na haldě pro konkrétní typy klíčů, konkrétně celočíselné klíče. Předpokládejme, že sada možných klíčů je {1, 2, ..., C}.
- Pouze když vložit, najít-min a extrakt-min jsou potřebné a v případě celočíselných priorit, a fronta na kbelík lze zkonstruovat jako pole C propojené seznamy plus ukazatel horní, zpočátku C. Vložení položky pomocí klíče k připojí položku k ka aktualizace nahoru ← min (nahoru, k), oba v konstantním čase. Výpis-min odstraní a vrátí jednu položku ze seznamu s indexem horní, poté přírůstky horní v případě potřeby, dokud znovu neukáže na neprázdný seznam; to trvá Ó(C) v nejhorším případě čas. Tyto fronty jsou užitečné pro třídění vrcholů grafu podle stupně.[2]:374
- A van Emde Boas strom podporuje minimální, maximum, vložit, vymazat, Vyhledávání, extrakt-min, extrakt-max, předchůdce a nástupce operace v Ó(log log C) čas, ale má náklady na prostor pro malé fronty o Ó(2m/2), kde m je počet bitů v hodnotě priority.[3] Prostor lze významně zmenšit hašováním.
- The Fúzní strom podle Fredmane a Willard implementuje minimální provoz v Ó(1) čas a vložit a extrakt-min operace v čas. Autor však uvádí, že „Naše algoritmy mají pouze teoretický zájem; konstantní faktory podílející se na době provádění vylučují praktičnost.“[4]
Pro aplikace, které umí mnoho “nahlédnout „operace pro každou operaci„ extrakce – min “, lze časovou složitost pro peek akce zredukovat na Ó(1) ve všech implementacích stromu a haldy ukládáním do mezipaměti prvek s nejvyšší prioritou po každém vložení a odebrání. Pro vložení to přidává maximálně konstantní cenu, protože nově vložený prvek je porovnáván pouze s dříve uloženým minimálním prvkem. V případě odstranění to nanejvýš přidá další „peek“ náklady, které jsou obvykle levnější než náklady na odstranění, takže celková časová složitost není významně ovlivněna.
Monotónní prioritní fronty jsou specializované fronty, které jsou optimalizovány pro případ, kdy není nikdy vložena žádná položka, která má nižší prioritu (v případě min. haldy) než jakákoli dříve extrahovaná položka. Toto omezení splňuje několik praktických aplikací prioritních front.
Shrnutí provozních časů
Tady jsou časové složitosti[5] různých haldy datových struktur. Názvy funkcí předpokládají minimální hromadu. Ve smyslu „Ó(F)" a "Θ(F) „viz Velká O notace.
Úkon najít-min vymazat-min vložit zmenšovací klíč splynout Binární[5] Θ(1) Θ(logn) Ó(logn) Ó(logn) Θ(n) Levicový Θ(1) Θ(log n) Θ(log n) Ó(log n) Θ(log n) Binomický[5][6] Θ(1) Θ(log n) Θ(1)[A] Θ(log n) Ó(logn)[b] Fibonacci[5][7] Θ(1) Ó(logn)[A] Θ(1) Θ(1)[A] Θ(1) Párování[8] Θ(1) Ó(log n)[A] Θ(1) Ó(logn)[A][C] Θ(1) Brodal[11][d] Θ(1) Ó(logn) Θ(1) Θ(1) Θ(1) Hodnostní párování[13] Θ(1) Ó(log n)[A] Θ(1) Θ(1)[A] Θ(1) Přísný Fibonacci[14] Θ(1) Ó(log n) Θ(1) Θ(1) Θ(1) 2–3 hromada[15] Ó(log n) Ó(log n)[A] Ó(log n)[A] Θ(1) ?
Ekvivalence prioritních front a třídicích algoritmů
Třídění pomocí prioritní fronty
The sémantika prioritních front přirozeně navrhuje metodu třídění: vložte všechny prvky, které mají být tříděny, do prioritní fronty a postupně je odeberte; vyjdou v seřazeném pořadí. Toto je vlastně postup používaný několika třídicí algoritmy, jakmile vrstva abstrakce poskytované prioritní frontou je odstraněno. Tato metoda řazení je ekvivalentní následujícím třídicím algoritmům:
název Prioritní implementace fronty Nejlepší Průměrný Nejhorší Heapsort Halda Smoothsort Leonardo Heap Třídění výběru Neuspořádané Pole Třídění vložení Objednané Pole Třídění stromů Samovyvažující binární vyhledávací strom
Použití třídicího algoritmu k vytvoření prioritní fronty
Algoritmus řazení lze také použít k implementaci prioritní fronty. Thorup konkrétně říká:[16]
Představujeme obecnou deterministickou redukci lineárního prostoru z prioritních front na třídění, což znamená, že pokud se můžeme seřadit n klíče dovnitř S(n) čas na klíč, pak existuje podpora prioritní fronty vymazat a vložit v Ó(S(n)) čas a najít-min v konstantním čase.
To znamená, že pokud existuje třídicí algoritmus, který lze třídit Ó(S) čas na klíč, kde S je nějaká funkce n a velikost slova,[17] pak lze použít daný postup k vytvoření fronty priorit, kde je tahání prvku s nejvyšší prioritou Ó(1) čas a vkládání nových prvků (a mazání prvků) je Ó(S) čas. Například pokud má jeden Ó(n logn) třídicí algoritmus, lze vytvořit prioritní frontu pomocí Ó(1) tahání a Ó(n logn) vložení.
Knihovny
Za prioritní frontu se často považujedatová struktura kontejneru ".
The Standardní knihovna šablon (STL) a C ++ Specifikuje standard z roku 1998 prioritní_kategorie jako jeden z STL kontejner adaptér šablony tříd. Nezadává však, jak mají být obsluhovány dva prvky se stejnou prioritou, a běžné implementace je skutečně nevrátí podle jejich pořadí ve frontě. Implementuje frontu s maximální prioritou a má tři parametry: srovnávací objekt pro třídění, například funkční objekt (výchozí hodnota je menší , pokud není uvedena), základní kontejner pro ukládání datových struktur (výchozí hodnota pro std :: vector ) a dva iterátory na začátek a konec sekvence. Na rozdíl od skutečných kontejnerů STL to neumožňuje opakování jejích prvků (striktně dodržuje svoji abstraktní definici datového typu). STL má také obslužné funkce pro manipulaci s jiným kontejnerem s náhodným přístupem jako binární max. Halda. The Posilujte knihovny mít také implementaci v haldě knihovny.
Pythonův heapq modul implementuje binární min haldu na začátek seznamu.
Jáva Knihovna obsahuje a Prioritní fronta třída, která implementuje frontu min. priority.
Scala Knihovna obsahuje a Prioritní fronta třída, která implementuje frontu maximální priority.
Jít Knihovna obsahuje a kontejner / hromada modul, který implementuje min hromadu nad jakoukoli kompatibilní datovou strukturu.
The Standardní knihovna PHP rozšíření obsahuje třídu SplPriorityQueue.
Apple Základní nadace rámec obsahuje a CFBinaryHeap struktura, která implementuje min. hromadu.
Aplikace
Správa šířky pásma
Prioritní řazení do fronty lze použít ke správě omezených zdrojů, jako je šířka pásma na přenosovém vedení z a síť router. V případě odchozího provoz zařazování do fronty kvůli nedostatečné šířce pásma, všechny ostatní fronty lze zastavit, aby se po příjezdu odeslal provoz z fronty s nejvyšší prioritou. Tím je zajištěno, že prioritní provoz (například provoz v reálném čase, např RTP proud a VoIP připojení) je předáváno s nejmenším zpožděním a nejmenší pravděpodobností odmítnutí z důvodu dosažení maximální kapacity fronty. Veškerý další provoz lze zpracovat, když je fronta s nejvyšší prioritou prázdná. Dalším použitým přístupem je odesílání nepoměrně většího provozu z front s vyšší prioritou.
Mnoho moderních protokolů pro místní sítě zahrnout také koncept prioritních front na řízení přístupu k médiím (MAC) podvrstva, aby bylo zajištěno, že aplikace s vysokou prioritou (např VoIP nebo IPTV ) mají nižší latenci než jiné aplikace, se kterými lze pracovat nejlepší úsilí servis. Mezi příklady patří IEEE 802.11e (pozměňovací návrh k) IEEE 802.11 který poskytuje kvalita služeb ) a ITU-T G.hn (standard pro vysokou rychlost místní síť pomocí stávajícího domácího vedení (elektrické vedení, telefonní linky a koaxiální kabely ).
Obvykle je omezení (policer) nastaveno na omezení šířky pásma, které může provoz z fronty s nejvyšší prioritou trvat, aby se zabránilo tomu, aby pakety s vysokou prioritou udusily veškerý ostatní provoz. Tohoto limitu se obvykle nikdy nedosáhne kvůli instancím řízení na vysoké úrovni, jako je Cisco Callmanager, které lze naprogramovat tak, aby blokovaly hovory, které by překročily naprogramovaný limit šířky pásma.
Diskrétní simulace událostí
Dalším použitím prioritní fronty je správa událostí v a diskrétní simulace událostí. Události jsou přidány do fronty s jejich simulačním časem použitým jako priorita. Provedení simulace probíhá opakovaným tažením horní části fronty a provedením události na ní.
Viz také: Plánování (výpočet), teorie front
Dijkstrův algoritmus
Když je graf uložen ve formě seznam sousedství nebo matice, prioritní fronta může být použita k efektivnímu extrahování při implementaci Dijkstrův algoritmus, i když jeden také potřebuje schopnost efektivně měnit prioritu konkrétního vrcholu v prioritní frontě.
Huffmanovo kódování
Huffmanovo kódování vyžaduje, aby jeden opakovaně získal dva stromy s nejnižší frekvencí. Fronta priorit je jeden způsob, jak toho dosáhnout.
Nejlepší první vyhledávací algoritmy
Nejlepší první vyhledávání algoritmy, jako * Vyhledávací algoritmus, najděte nejkratší cestu mezi dvěma vrcholy nebo uzly a vážený graf, nejprve vyzkoušet nejslibnější trasy. Prioritní fronta (známá také jako třásně) slouží ke sledování neprozkoumaných tras; ten, u kterého je odhad (dolní mez v případě A *) nejmenší délky cesty, má nejvyšší prioritu. Pokud omezení paměti způsobí, že je vyhledávání prvního pokusu nepraktické, varianty jako SMA * místo toho lze použít algoritmus s a oboustranná prioritní fronta umožnit odebrání položek s nízkou prioritou.
Algoritmus ROAM triangulace
Optimální přizpůsobení sítí v reálném čase (TOULAT SE ) algoritmus počítá dynamicky se měnící triangulaci terénu. Funguje to rozdělením trojúhelníků tam, kde je potřeba více detailů, a jejich sloučením tam, kde je potřeba méně detailů. Algoritmus přiřadí každému trojúhelníku v terénu prioritu, obvykle související s poklesem chyb, pokud by byl tento trojúhelník rozdělen. Algoritmus používá dvě prioritní fronty, jednu pro trojúhelníky, které lze rozdělit, a druhou pro trojúhelníky, které lze sloučit. V každém kroku je trojúhelník z rozdělené fronty s nejvyšší prioritou rozdělen, nebo je trojúhelník ze slučovací fronty s nejnižší prioritou sloučen s jeho sousedy.
Primův algoritmus pro minimální kostru
Použitím min. fronta priority haldy v Primův algoritmus najít minimální kostra a připojeno a neorientovaný graf, lze dosáhnout dobré doby chodu. Tato fronta priority min haldy používá datovou strukturu haldy min, která podporuje operace jako např vložit, minimální, extrakt-min, zmenšovací klíč.[18] V této implementaci hmotnost hran se používá k rozhodnutí o prioritě vrcholy. Snižte hmotnost, vyšší prioritu a vyšší hmotnost, nižší prioritu.[19]
Paralelní prioritní fronta
Parallelization can be used to speed up priority queues, but requires some changes to the priority queue interface. Důvodem těchto změn je, že sekvenční aktualizace má obvykle pouze nebo náklady a neexistuje žádný praktický zisk pro paralelizaci takové operace. Jednou z možných změn je umožnit souběžný přístup více procesorů ke stejné frontě priorit. Druhou možnou změnou je povolení dávkových operací, na kterých se pracuje prvků, místo pouze jednoho prvku. Například, extraktMin odstraní první prvky s nejvyšší prioritou.
Souběžný paralelní přístup
Pokud prioritní fronta umožňuje souběžný přístup, může na této prioritní frontě souběžně provádět operace více procesů. To však vyvolává dva problémy. Nejprve již není zřejmá definice sémantiky jednotlivých operací. Například pokud dva procesy chtějí extrahovat prvek s nejvyšší prioritou, měly by získat stejný prvek nebo odlišné? To omezuje paralelismus na úrovni programu pomocí prioritní fronty. Navíc, protože více procesů má přístup ke stejnému prvku, vede to ke sporu.
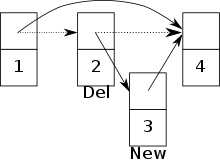 Vloží se uzel 3 a nastaví ukazatel uzlu 2 na uzel 3. Ihned poté se uzel 2 vymaže a ukazatel uzlu 1 se nastaví na uzel 4. Nyní uzel 3 již není dosažitelný.
Vloží se uzel 3 a nastaví ukazatel uzlu 2 na uzel 3. Ihned poté se uzel 2 vymaže a ukazatel uzlu 1 se nastaví na uzel 4. Nyní uzel 3 již není dosažitelný.Souběžný přístup k prioritní frontě lze implementovat na modelu PRAM Concurrent Read, Concurrent Write (CRCW). V následujícím je prioritní fronta implementována jako přeskočit seznam.[20][21] Kromě toho primitivní atomová synchronizace, CAS, se používá k vytvoření seznamu přeskočení zámek -volný, uvolnit. Uzly seznamu přeskočení se skládají z jedinečného klíče, priority a pole z ukazatele, pro každou úroveň, do dalších uzlů a vymazat označit. The vymazat označte značky, pokud má být uzel procesem odstraněn. Tím je zajištěno, že ostatní procesy mohou na odstranění reagovat odpovídajícím způsobem.
- příloha (e): Nejprve se vytvoří nový uzel s klíčem a prioritou. Kromě toho je uzlu přiřazena řada úrovní, která určuje velikost pole ukazatelů. Poté se provede hledání, aby se našlo správné umístění, kam se má vložit nový uzel. Hledání začíná od prvního uzlu a od nejvyšší úrovně. Poté je seznam přeskočen procházen dolů na nejnižší úroveň, dokud není nalezena správná poloha. Během hledání se pro každou úroveň uloží poslední procházející uzel jako nadřazený uzel pro nový uzel na dané úrovni. Kromě toho bude uzel, na který směřuje ukazatel na nadřazeném uzlu, nasměrován jako nástupnický uzel nového uzlu na této úrovni. Poté se pro každou úroveň nového uzlu nastaví ukazatele nadřazeného uzlu na nový uzel. Nakonec budou ukazatele nového uzlu pro každou úroveň nastaveny na odpovídající uzly nástupce.
- extrakt-min: Nejprve se prochází seznam přeskočení, dokud se nedosáhne uzlu, jehož vymazat značka není nastavena. Tento vymazat mark je pak nastaven na true pro daný uzel. Nakonec se aktualizují ukazatele nadřazených uzlů odstraněného uzlu.
Pokud je povolen souběžný přístup k prioritní frontě, může dojít ke konfliktům mezi dvěma procesy. Konflikt například nastane, pokud se jeden proces pokouší vložit nový uzel, ale současně se jiný proces chystá odstranit předchůdce daného uzlu.[20] Existuje riziko, že je nový uzel přidán do seznamu přeskočení, ale již není dosažitelný. (Viz obrázek )
Operace s K-prvky
V tomto nastavení jsou operace na prioritní frontě zobecněny na dávku prvky. Například k_extract-min odstraní nejmenší prvky prioritní fronty a vrátí je.
V nastavení sdílené paměti, frontu paralelních priorit lze snadno implementovat pomocí paralelních binární vyhledávací stromy a algoritmy stromů založené na spojení. Zejména, k_extract-min odpovídá a rozdělit na binárním vyhledávacím stromu, který má stojí a přináší strom, který obsahuje nejmenší prvky. k_ vložení lze aplikovat a svaz původní fronty priorit a dávky vložení. Pokud je dávka již seřazená podle klíče, k_ vložení má náklady. Jinak musíme nejprve dávku seřadit, takže náklady budou . Podobně lze použít i další operace pro prioritní frontu. Například, k_decrease-key lze provést první aplikací rozdíl a pak svaz, který nejprve odstraní prvky a poté je vloží zpět pomocí aktualizovaných klíčů. Všechny tyto operace jsou vysoce paralelní a teoretickou a praktickou účinnost lze nalézt v souvisejících výzkumných dokumentech[22][23].
Zbytek této části pojednává o algoritmu založeném na frontách v distribuované paměti. Předpokládáme, že každý procesor má svou vlastní lokální paměť a lokální (sekvenční) prioritní frontu. Prvky globální (paralelní) prioritní fronty jsou distribuovány napříč všemi procesory.
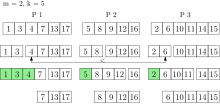 k_extract-min se provádí v prioritní frontě se třemi procesory. Zelené prvky jsou vráceny a odebrány z prioritní fronty.
k_extract-min se provádí v prioritní frontě se třemi procesory. Zelené prvky jsou vráceny a odebrány z prioritní fronty.A k_ vložení operace přiřadí prvky rovnoměrně náhodně procesorům, které vkládají prvky do svých místních front. Jednotlivé prvky lze do fronty stále vložit. Při použití této strategie jsou globální nejmenší prvky ve spojení místních nejmenších prvků každého procesoru s vysokou pravděpodobností. Každý procesor tedy drží reprezentativní část fronty globální priority.
Tato vlastnost se používá, když k_extract-min je proveden jako nejmenší prvky každé místní fronty jsou odebrány a shromážděny v sadě výsledků. Prvky ve výsledkové sadě jsou stále spojeny s původním procesorem. Počet prvků , který je odebrán z každé místní fronty, závisí na a počet procesorů . [24]Paralelním výběrem jsou určeny nejmenší prvky sady výsledků. S vysokou pravděpodobností se jedná o globální nejmenší prvky. Pokud ne, prvky jsou opět odebrány z každé místní fronty a vloženy do sady výsledků. To se děje až do globálního nejmenší prvky jsou ve výsledkové sadě. Nyní tyto prvky lze vrátit. Všechny ostatní prvky sady výsledků jsou vloženy zpět do jejich místních front. Provozní doba k_extract-min se očekává , kde a je velikost prioritní fronty.[24]
Frontu priorit lze dále vylepšit tak, že po přesunutí zbývajících prvků sady výsledků přímo zpět do místních front k_extract-min úkon. To šetří pohyblivé prvky tam a zpět mezi časovou sadou výsledků a místními frontami.
Odstraněním několika prvků najednou lze dosáhnout značného zrychlení. Ale ne všechny algoritmy mohou použít tento druh prioritní fronty. Dijkstrův algoritmus například nemůže fungovat na několika uzlech najednou. Algoritmus vezme uzel s nejmenší vzdáleností od prioritní fronty a vypočítá nové vzdálenosti pro všechny sousední uzly. Pokud byste si vzali uzly, práce na jednom uzlu mohla změnit vzdálenost dalšího z uzlů uzly. Takže použití operací k-prvku zničí vlastnost nastavení štítku Dijkstraova algoritmu.
Viz také
Reference
- ^ Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001) [1990]. „Kapitola 20: Fibonacciho hromady“. Úvod do algoritmů (2. vyd.). MIT Press a McGraw-Hill. 476–497. ISBN 0-262-03293-7. Třetí vydání, str. 518.
- ^ Skiena, Steven (2010). Příručka pro návrh algoritmu (2. vyd.). Springer Science + Business Media. ISBN 978-1-849-96720-4.
- ^ P. van Emde Boas. Zachování pořádku v lese za méně než logaritmický čas. v Sborník ze 16. ročníku sympozia o základech informatiky, strany 75-84. IEEE Computer Society, 1975.
- ^ Michael L. Fredman a Dan E. Willard. Překonání teoretické informace vázané na fúzní stromy. Journal of Computer and System Sciences, 48(3):533-551, 1994
- ^ A b C d Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L. (1990). Úvod do algoritmů (1. vyd.). MIT Press a McGraw-Hill. ISBN 0-262-03141-8.
- ^ "Binomická halda | Brilliant Math & Science Wiki". brilliant.org. Citováno 2019-09-30.
- ^ Fredman, Michael Lawrence; Tarjan, Robert E. (Červenec 1987). „Fibonacciho hromady a jejich použití ve vylepšených algoritmech optimalizace sítě“ (PDF). Časopis Asociace pro výpočetní techniku. 34 (3): 596–615. CiteSeerX 10.1.1.309.8927. doi:10.1145/28869.28874.
- ^ Iacono, Johne (2000), „Vylepšené horní hranice pro párování hromad“, Proc. 7. skandinávský seminář o teorii algoritmu (PDF), Přednášky v informatice, 1851, Springer-Verlag, str. 63–77, arXiv:1110.4428, CiteSeerX 10.1.1.748.7812, doi:10.1007 / 3-540-44985-X_5, ISBN 3-540-67690-2
- ^ Fredman, Michael Lawrence (Červenec 1999). „O efektivitě párování hromad a souvisejících datových struktur“ (PDF). Časopis Asociace pro výpočetní techniku. 46 (4): 473–501. doi:10.1145/320211.320214.
- ^ Pettie, Seth (2005). Směrem ke konečné analýze párování hromad (PDF). FOCS '05 Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science. 174–183. CiteSeerX 10.1.1.549.471. doi:10.1109 / SFCS.2005.75. ISBN 0-7695-2468-0.
- ^ Brodal, Gerth S. (1996), „Nejhorší efektivní fronty priorit“ (PDF), Proc. 7. ročník sympozia ACM-SIAM o diskrétních algoritmech, str. 52–58
- ^ Goodrich, Michael T.; Tamassia, Roberto (2004). „7.3.6. Konstrukce haldy zdola nahoru“. Datové struktury a algoritmy v Javě (3. vyd.). 338–341. ISBN 0-471-46983-1.
- ^ Haeupler, Bernhard; Sen, Siddhartha; Tarjan, Robert E. (Listopad 2011). „Hromadné párování“ (PDF). SIAM J. Computing. 40 (6): 1463–1485. doi:10.1137/100785351.
- ^ Brodal, Gerth Stølting; Lagogiannis, George; Tarjan, Robert E. (2012). Přísné hromady Fibonacci (PDF). Sborník 44. sympozia o teorii práce na počítači - STOC '12. str. 1177–1184. CiteSeerX 10.1.1.233.1740. doi:10.1145/2213977.2214082. ISBN 978-1-4503-1245-5.
- ^ Takaoka, Tadao (1999), Teorie 2–3 hromád (PDF), str. 12
- ^ Thorup, Mikkel (2007). "Ekvivalence mezi prioritními frontami a tříděním". Deník ACM. 54 (6): 28. doi:10.1145/1314690.1314692. S2CID 11494634.
- ^ „Archivovaná kopie“ (PDF). Archivováno (PDF) od originálu na 2011-07-20. Citováno 2011-02-10.CS1 maint: archivovaná kopie jako titul (odkaz)
- ^ Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Úvod do algoritmů (3. vyd.). MIT Press a McGraw-Hill. ISBN 0-262-03384-4.
- ^ „Primův algoritmus“. Geek pro Geeks. Archivováno z původního dne 9. září 2014. Citováno 12. září 2014.
- ^ A b Sundell, Håkan; Tsigas, Philippas (2005). „Rychlé a bezzámkové souběžné prioritní fronty pro vícevláknové systémy“. Journal of Parallel and Distributed Computing. 65 (5): 609–627. doi:10.1109 / IPDPS.2003.1213189. S2CID 20995116.
- ^ Lindén, Jonsson (2013), „Souběžná prioritní fronta založená na skiplistu s minimálním obsahem paměti“, Technická zpráva 2018-003 (v němčině)
- ^ Blelloch, Guy E .; Ferizovic, Daniel; Sun, Yihan (2016), „Just Join for Parallel Ordered Sets“, Symposium on Parallel Algorithms and Architectures, Proc. 28. ACM Symp. Paralelní algoritmy a architektury (SPAA 2016), ACM, str. 253–264, arXiv:1602.02120, doi:10.1145/2935764.2935768, ISBN 978-1-4503-4210-0, S2CID 2897793
- ^ Blelloch, Guy E .; Ferizovic, Daniel; Sun, Yihan (2018), „PAM: parallel augmented maps“, Sborník 23. sympozia ACM SIGPLAN o zásadách a praxi paralelního programování, ACM, s. 290–304
- ^ A b Sanders, Peter; Mehlhorn, Kurt; Dietzfelbinger, Martin; Dementiev, Roman (2019). Sekvenční a paralelní algoritmy a datové struktury - základní sada nástrojů. Springer International Publishing. str. 226–229. doi:10.1007/978-3-030-25209-0. ISBN 978-3-030-25208-3. S2CID 201692657.
Další čtení
- Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2001) [1990]. "Oddíl 6.5: Prioritní fronty". Úvod do algoritmů (2. vyd.). MIT Press a McGraw-Hill. str. 138–142. ISBN 0-262-03293-7.
externí odkazy
- C ++ reference pro
std :: priority_queue - Popisy podle Lee Killough
- PQlib - Otevřená knihovna prioritních front pro C.
- libpqueue je implementace obecné fronty priorit (haldy) (v C) používaná projektem Apache HTTP Server.
- Průzkum známých prioritních struktur front napsal Stefan Xenos
- UC Berkeley - Computer Science 61B - Lecture 24: Priority Queues (video) - úvod do prioritních front pomocí binární haldy


















{kind=link}