Jazykový výkon - Linguistic performance - Wikipedia
| Část série na |
| Lingvistika |
|---|
Termín jazykový výkon byl používán uživatelem Noam Chomsky v roce 1960 popsat „skutečné používání jazyka v konkrétních situacích“.[1] Používá se k popisu obou Výroba, někdy nazývané čestné slovo, stejně jako porozumění jazyku.[2] Výkon je definován na rozdíl od „odborná způsobilost "; druhý popisuje mentální znalosti jazyka nebo řečníka nebo posluchače."[3]
Část motivace pro rozlišení mezi výkonem a kompetencí pochází z chyby řeči: navzdory dokonalému porozumění správným formám může mluvčí jazyka neúmyslně vytvořit nesprávné formy. Je to proto, že výkon se vyskytuje v reálných situacích, a proto podléhá mnoha mimojazykovým vlivům. Například rozptýlení nebo omezení paměti mohou ovlivnit lexikální vyhledávání (Chomsky 1965: 3) a vést k chybám v produkci i ve vnímání.[4] Tyto mimojazykové faktory jsou zcela nezávislé na skutečné znalosti jazyka,[5] a prokázat, že znalost řečníků (jejich kompetence) se liší od skutečného používání jazyka (jejich výkon).[6]
Pozadí
Deskriptor | Obhájce | Vysvětlení |
|---|---|---|
| Jazyk /Čestné slovo | Ferdinand de Saussure (1916)[7] | Jazyk je systém znaků. Langue popisuje sociální konsenzus o tom, jak jsou značky aplikovány. Čestné slovo popisuje fyzický projev jazyk. Zdůrazňuje odhalení struktury jazyka prostřednictvím studia podmínečného propuštění. |
| Odborná způsobilost/Výkon | Noam Chomsky (1965)[8] | Kompetence zavedená do teorie generativní gramatiky popisuje nevědomou a vrozenou znalost jazykových pravidel. Výkon popisuje pozorovatelné použití jazyka. Zdůrazňuje studium kompetencí výkon. |
| I-jazyk /E-jazyk | Noam Chomsky (1986)[9] | Podobně jako u výkonu / kompetence je I-Language internalizovanou vrozenou znalostí jazyka; E-jazyk je externalizovaným pozorovatelným výstupem. Zdůrazňuje studium I-jazyka nad E-jazykem. |
Langue versus podmínečné propuštění
Publikováno v roce 1916, Ferdinand de Saussure je Kurz obecné lingvistiky popisuje Jazyk tak jako "systém značek, které vyjadřují myšlenky".[7] de Saussure popisuje dvě součásti jazyka: jazyk a čestné slovo. Langue se skládá ze strukturních vztahů, které definují jazyk, který zahrnuje gramatika, syntax a fonologie. Čestné slovo je fyzickým projevem znamení; zejména konkrétní projev jazyk tak jako mluvený projev nebo psaní. Zatímco jazyk lze na něj pohlížet striktně jako na systém pravidel, nejedná se o takový absolutní systém čestné slovo musí zcela odpovídat jazyk.[10] Kreslení analogie k šachu, de Saussure srovnává jazyk pravidla šachu, která definují, jak by se hra měla hrát, a čestné slovo na individuální volby hráče vzhledem k možným tahům povoleným v systému pravidel.[7]
Kompetence versus výkon
Navrhl v padesátých letech 20. století Noam Chomsky, generativní gramatika je analytický přístup k jazyku jako strukturálnímu rámci lidské mysli.[11] Formální analýzou komponent, jako jsou syntax, morfologie, sémantika a fonologie, a generativní gramatika snaží se modelovat implicitní jazykové znalosti, s nimiž řečníci určují gramatičnost.
v transformační generativní teorie gramatiky, Chomsky rozlišuje mezi dvěma složkami jazyková produkce: odborná způsobilost a výkon.[5] Odborná způsobilost popisuje mentální znalost jazyka, vnitřní porozumění mluvčího vztahů zvukového významu, jak je stanoveno lingvistickými pravidly. Výkon - to je skutečné pozorované používání jazyka - zahrnuje více faktorů než foneticko-sémantické porozumění. Výkon vyžaduje mimojazykové znalosti, jako je povědomí mluvčího, publika a kontextu, což rozhodujícím způsobem určuje, jak je řeč konstruována a analyzována. Řídí se také principy kognitivních struktur, které se nepovažují za aspekty jazyka, jako např Paměť, rozptýlení, Pozornost, a chyby řeči.
I-jazyk versus e-jazyk
V roce 1986 Chomsky navrhl rozdíl podobný rozdílu mezi kompetencí a výkonem, který pobavil představu o I-jazyk (interní jazyk) což jsou vnitřní jazykové znalosti v rodném mluvčím a E-jazyk (externí jazyk) což je pozorovatelný jazykový výstup řečníka. Byl to jazyk I Chomsky argumentem by mělo být zaměření výzkumu, a ne e-jazyk.[9]
E-jazyk byl použit k popisu aplikace umělých systémů, například v počet, teorie množin a s přirozený jazyk nahlíženo jako na sady, zatímco výkon byl použit čistě k popisu aplikací přirozeného jazyka.[12] Mezi I-jazykem a odborná způsobilost „I-Language označuje naši vnitřní fakultu jazyků, kompetence používá Chomsky jako neformální, obecný termín nebo jako termín s odkazem na konkrétní kompetenci, jako je„ gramatická kompetence “nebo„ pragmatická kompetence “.[12]
Hypotéza korespondence výkonové gramatiky
John A. Hawkins 'Performance-Grammar Correspondence Hypothesis (PGCH) uvádí, že syntaktické struktury gramatiky jsou konvencionalizovány na základě toho, zda a nakolik jsou struktury preferovány ve výkonu.[13] Preference výkonu souvisí se složitostí struktury a zpracovává se nebo porozumění, účinnost. Komplexní struktura konkrétně odkazuje na strukturu obsahující více jazykových prvků nebo slov na konci struktury než na začátku. Právě tato strukturní složitost vede ke snížení efektivity zpracování, protože větší struktura vyžaduje další zpracování.[13] Tento model se snaží vysvětlit slovosled v různých jazycích na základě zamezení zbytečné složitosti ve prospěch zvýšení efektivity zpracování. Řečníci provádějí automatický výpočet Okamžitá složka (IC) poměr slov k slovu a vytvořit strukturu s nejvyšším poměrem.[13] Struktury s vysokým IC-to-word order jsou struktury, které obsahují nejmenší počet slov potřebných pro posluchače k analýze struktury na složky, což má za následek efektivnější zpracování.[13]
Počáteční struktury hlavy
v hlavy-počáteční struktury, který obsahuje příklad SVO a slovosled VSO, cílem mluvčího je uspořádat větné složky od nejméně složitých.
Slovosled SVO
Příklad slovníku SVO lze doložit angličtinou; vezměte v úvahu příklady vět v (1). V bodě (1a) jsou v IA přítomny tři bezprostřední složky (IC) slovesná fráze, jmenovitě VP, PP1 a PP2, a existují čtyři slova (šel do Londýna dovnitř) povinen analyzovat VP na jeho voliče. Proto je poměr IC k slovu 3/4 = 75%. Naproti tomu v (1b) je VP stále složeno ze tří integrovaných obvodů, ale k určení základní struktury VP je nyní zapotřebí šest slov (šel, dovnitř, pozdě, odpoledne, do). Poměr pro (1b) je tedy 3/6 = 50%. Hawkins navrhuje, aby reproduktory raději produkovaly (1a), protože má vyšší poměr IC-to-word, což vede k rychlejšímu a efektivnějšímu zpracování.[13]
1a. John [VP šel [PP1 do Londýna] [[PP2 v pozdě odpoledne]] 1b. John [VP šel [PP2 pozdě odpoledne]] [[PP1 na Londýn]]
Hawkins podporuje výše uvedenou analýzu poskytnutím údajů o výkonu k prokázání preferencí, které mají reproduktory pro objednávání krátkých frází před dlouhými frázemi při výrobě struktur na počátku hlavy. Níže uvedená tabulka založená na datech z angličtiny ilustruje, že krátká předložková fráze (PP1) je přednostně objednáno před dlouhým PP (PP2) a že tato preference se zvyšuje, jak se zvětšuje rozdíl velikosti mezi dvěma PP. Například 60% vět je seřazeno jako krátké (PP1) až dlouhé (PP2), když byl PP2 o 1 slovo delší než PP1. Naproti tomu 99% vět je seřazeno od krátkých po dlouhé, když je PP2 delší než PP1 o 7+ slov.
Anglické předložkové fráze seřazené podle relativní hmotnosti[13]
| n = 323 | PP2> PP1 o 1 slovo | o 2-4 | o 5-6 | od 7+ |
|---|---|---|---|---|
| [V PP1 PP2] | 60% (58) | 86% (108) | 94% (31) | 99% (68) |
| [V PP2 PP1] | 40% (38) | 14% (17) | 6% (2) | 1% (1) |
PP2 = delší PP; PP1 = kratší PP. Podíl short-long na long-short v procentech; skutečný počet sekvencí v závorkách. Dalších 71 sekvencí mělo PP stejné délky (celkem n = 394)
VSO slovosled
Hawkins tvrdí, že preference pro krátké, následované dlouhými frázemi platí pro všechny jazyky, které mají strukturu počáteční. To zahrnuje jazyky s VSO slovosled jako od maďarský. Výpočtem poměru IC k slovu pro maďarské věty stejným způsobem, jako tomu bylo pro Angličtina věty, 2a. se ukazuje, že má vyšší poměr než 2b.[13]
2a. VP [Döngetik NP [facipöink NP [az utcakat]] těsto dřevěné boty-1PL ulice-ACC Naše dřevěné boty otlučou do ulic 2b. VP [Döngetik NP [az utcakat] NP [[ facipöink ] ]
Maďarská data o výkonu (níže) ukazují stejný vzor preferencí jako anglická data. Tato studie zkoumala pořadí dvou po sobě jdoucích podstatné jméno fráze (NP) a zjistili, že výkonnější je kratší NP následovaný delším NP a že tato preference se zvyšuje s rostoucím rozdílem velikosti mezi NP1 a NP2.
Uspořádání fráze maďarského podstatného jména podle relativní hmotnosti[13]
| n = 85 | mNP2> mNP1 o 1 slovo | o 2 | od 3+ |
|---|---|---|---|
| [V mNP1 mNP2] | 85% (50) | 96% (27) | 100% (8) |
| [V mNP2 mNP1] | 15% (9) | 4% (1) | 0% (0) |
mNP = jakýkoli NP konstruovaný na jeho levém obvodu. NP2 = delší NP; NP1 = kratší NP. Podíl short-longto long-short udávaný v procentech; skutečný počet sekvencí uvedených v závorkách. Dalších 21 sekvencí mělo NP stejné délky (celkem n = 16).
Hlavové konečné struktury
Hawkinsovo vysvětlení výkonu a slovosledu sahá i do struktur hlavy-finále. Například od japonský je SOV jazyk hlava (V) je na konci věty. Tato teorie předpovídá, že řečníci upřednostní řazení frází v hlavových závěrečných větách od dlouhých frází po krátké, na rozdíl od krátkých po dlouhé, jak je vidět v počátečních jazycích.[13] Toto obrácení předvolby řazení je způsobeno skutečností, že v hlavových závěrečných větách má vyšší poměr IC k slovu dlouhé následované krátkým frázovým uspořádáním.
3a. Tanaka ga vp [pp [Hanako kara] np [takže ne hon o] katta] Tanaka NOM Hanako z této knihy ACC koupil Tanako koupil tu knihu od Hanako 3b. Tanaka ga vp [np [sono hon Ó] pp [Hanako kara] [katta]
VP a jeho složky ve 4. jsou konstruovány z hlav na pravé straně. To znamená, že počet slov použitých k výpočtu poměru se počítá od hlavy první věty (PP v 3a. A NP v 3b.) Po sloveso (jak je uvedeno výše tučně). Poměr IC k slovu pro VP v 3a. je 3/5 = 60%, zatímco poměr pro VP v 3b. je 3/4 = 75%. Proto 3b. by měl být preferován japonskými reproduktory, protože má vyšší poměr IC-to-word, což vede k rychlejší analýze vět posluchačem.[13]
Preference výkonu pro dlouhé až krátké frázové řazení v jazycích SVO je podporována údaji o výkonu. Tabulka níže ukazuje, že je upřednostňována výroba dlouhých až krátkých frází a že tato preference se zvyšuje, jak se zvětšuje velikost rozdílu mezi těmito dvěma frázemi. Například objednávání delší 2ICm (kde ICm je buď přímý objekt NP s akuzativem částice případu nebo PP konstruované z pravé periferie) před kratší 1ICm je častější a frekvence se zvyšuje na 91%, pokud je 2ICm delší než 1ICm o 9+ slov.
Japonské objednávky NPo a PPm podle relativní hmotnosti[13]
| n = 153 | 2ICm> 1ICm o 1-2 slova | o 3-4 | o 5-8 | od 9+ |
|---|---|---|---|---|
| [2ICm 1ICm V] | 66% (59) | 72% (21) | 83% (20) | 91% (10) |
| [1ICm 2ICm V] | 34% (30) | 28% (8) | 17% (4) | 9% (1) |
Npo = přímý objekt NP s akuzativním případem. PPm = PP konstruovaný na jeho pravém okraji P (ostposition). ICm = buď NPo nebo PPm. 2IC = delší IC; 1IC = kratší IC. Podíl dlouhých až krátkých a krátkých a dlouhých objednávek uveden v procentech; skutečný počet sekvencí v závorkách. dalších 91 sekvencí mělo IC stejné délky (celkem n = 244)
Hypotéza plánování promluvy
Tom Wasow navrhuje, aby slovosled vznikl v důsledku plánování promluvy ve prospěch řečníka.[14] Představuje koncepty časného a pozdního závazku, kde závazek je bod v promluvě, kde je možné předvídat následnou strukturu.[14] Konkrétně časný závazek odkazuje na bod závazku přítomný dříve v promluvě a pozdní závazek odkazuje na bod závazku přítomný později v promluvě.[14] Vysvětluje, že včasný závazek zvýhodní posluchače, protože včasná předpověď následné struktury umožňuje rychlejší zpracování. Srovnatelně pozdní závazek zvýhodní řečníka tím, že odloží rozhodování, což řečníkovi poskytne více času na plánování promluvy.[14] Wasow ilustruje, jak plánování promluvy ovlivňuje syntaktický slovosled testováním včasného a pozdního závazku heavy-NP posunul Věty (HNPS). Cílem je prozkoumat vzorce HNPS a určit, zda údaje o výkonu ukazují věty, které jsou strukturovány tak, aby upřednostňovaly mluvčího nebo posluchače.[14]
Příklady časného / pozdního závazku a posunu těžkých NP
Následující příklady ilustrují, co se rozumí podčasným a pozdním závazkem a jak se na tyto věty vztahuje posun těžkého NP. Wasow se podíval na dva typy sloves:[14]
Vt (přechodná slovesa ): vyžadují objekty NP.
4a. Pat VP [přinesl NP [krabici se stuhou kolem] PP [[na večírek]] 4b. Pat VP [přinesl PP [na večírek] NP [[krabičku se stuhou kolem]]]
V 4a. nebyl použit žádný posun těžkého NP. NP je k dispozici brzy, ale neposkytuje žádné další informace o struktuře věty - příklad „pozdě“ ve větě je příkladem pozdního závazku. Naproti tomu v bodě 4b., Kde posun těžkého NP posunul NP doprava, jakmile je vysloveno „to“, posluchač ví, že VP musí obsahovat NP a PP. Jinými slovy, když je vysloveno „to“, umožňuje posluchači předvídat zbývající strukturu věty hned na začátku. U přechodných sloves tedy HNPS vede k včasnému závazku a upřednostňuje posluchače.
Vp (předložková slovesa ): může vzít NP objekt nebo bezprostředně následující PP bez NP objektu
5a. Pat VP [napsal NP [něco o Chrisovi] PP [[na tabuli]]. 5b. Pat VP [napsal PP [na tabuli] NP [[něco o Chrisovi.]]
Na 5a nebyl použit žádný HNPS. V 5b. posluchač potřebuje slyšet slovo „něco“, aby věděl, že promluva obsahuje PP a NP, protože objekt NP je volitelný, ale „něco“ bylo ve větě posunuto později. U předložkových sloves tedy HNPS vede k pozdnímu závazku a upřednostňuje řečníka.
Předpovědi a zjištění
Na základě výše uvedených informací Wasow předpověděl, že pokud jsou věty konstruovány z pohledu mluvčího, pak by se posun těžkého NP zřídka vztahoval na věty obsahující přechodné sloveso, ale často by se vztahoval na věty obsahující předložkové sloveso. Opačná předpověď byla učiněna, pokud jsou věty konstruovány z pohledu posluchače.[14]
| Perspektiva řečníka | Perspektiva posluchače | |
|---|---|---|
| Vt | Posun těžkého NP = vzácný | Posun těžkého NP = relativně běžný |
| Vp | Posun těžkého NP = relativně běžný | Posun těžkého NP = velmi vzácný |
Aby otestoval své předpovědi, analyzoval Wasow údaje o výkonu (z údajů o korpusech) pro míru výskytu HNPS pro Vt a Vp a zjistil, že HNPS se vyskytoval dvakrát častěji ve Vp než ve Vt, a proto podporoval předpovědi z pohledu mluvčího.[14] Naproti tomu nenašel důkazy na podporu předpovědí učiněných na základě pohledu posluchače. Jinými slovy, vzhledem k výše uvedeným údajům, když se HNPS použije na věty obsahující přechodné sloveso, výsledek zvýhodňuje posluchače. Wasow zjistil, že HNPS aplikovaný na přechodné slovesné věty je v datech o výkonu vzácný, což podporuje perspektivu mluvčího. Když je navíc HNPS aplikován na předložkové slovesné struktury, výsledek zvýhodňuje mluvčího. Ve své studii údajů o výkonu našel Wasow důkazy o tom, že HNPS se často aplikuje na předložkové slovesné struktury, které dále podporují perspektivu mluvčího.[14] Na základě těchto zjištění Wasow dochází k závěru, že HNPS koreluje s preferencí mluvčího pro pozdní závazek, což ukazuje, jak může preference výkonu reproduktoru ovlivnit slovosled.
Alternativní gramatické modely
Zatímco dominantní pohledy na gramatiku jsou do značné míry zaměřeny na kompetence, mnozí, včetně samotného Chomského, tvrdili, že úplný model gramatiky by měl být schopen odpovídat za údaje o výkonu. Ale zatímco Chomsky tvrdí, že nejprve by měla být studována kompetence, což umožňuje další studium výkonu,[6] některé systémy, jako např omezovací gramatiky jsou postaveny s výkonem jako výchozím bodem (porozumění, v případě omezovacích gramatik[15] Zatímco tradiční modely generativní gramatiky měly velký úspěch při popisu struktury jazyků, byly méně úspěšné při popisu toho, jak je jazyk interpretován v reálných situacích. Například tradiční gramatika popisuje větu tak, že má „základní strukturu“, která se liší od „povrchové struktury“, kterou reproduktory ve skutečnosti vytvářejí. Ve skutečné konverzaci však posluchač interpretuje význam věty v reálném čase, jak povrchová struktura prochází.[16] Tento druh on-line zpracování, který zohledňuje jevy, jako je dokončení věty jiné osoby a zahájení věty, aniž byste věděli, jak to skončí, se v tradičních generativních modelech gramatiky přímo nepočítá.[16] Existuje několik alternativních gramatických modelů, které mohou lépe zachytit tento povrchový aspekt jazykového výkonu, včetněOmezovací gramatika, Lexikální funkční gramatika, a Gramatika struktury fráze řízené hlavou.
Chyby v jazykovém výkonu
K chybám v lingvistickém výkonu dochází nejen u dětí, které si nově osvojují svůj rodný jazyk, u studentů druhého jazyka, u osob se zdravotním postižením nebo se zraněním mozku, ale také u kompetentních mluvčích. Zde se zaměří na typy chyb výkonu, které zahrnují chyby syntax, v systému Windows se mohou vyskytnout další typy chyb fonologický, sémantický vlastnosti slov, další informace viz chyby řeči. Fonologické a sémantické chyby mohou být způsobeny opakováním slov, nesprávnými výslovnostmi, omezeními ve slovech pracovní paměť a délka promluva.[17] Sklouznutí jazyka jsou nejčastější v mluvených jazycích a vyskytují se, když mluvčí buď: řekne něco, co nechtěli; vytváří nesprávné pořadí zvuků nebo slov; nebo použije nesprávné slovo.[18] Další případy chyb v lingvistickém výkonu jsou tikety podepsané jazyky, skluzy ucha, což jsou chyby v porozumění promluv a sklouznutí pera, ke kterým dochází při psaní. Řečník i posluchač vnímá chyby v jazykovém výkonu, a proto mohou mít mnoho interpretací v závislosti na úsudku osoby a kontextu, ve kterém byla věta vyslovena.[19]
Navrhuje se úzký vztah mezi jazykovými jednotkami gramatiky a psychologickými řečovými jednotkami, z čehož vyplývá, že existuje vztah mezi jazykovými pravidly a psychologickými procesy, které vytvářejí promluvy.[20] K chybám ve výkonu může dojít na jakékoli úrovni těchto psychologických procesů. Lise Menn navrhuje, aby v produkci řeči existuje pět úrovní zpracování, každá s vlastní možnou chybou, která by mohla nastat.[18] Podle navrhované struktury zpracování řeči Mennem dojde k chybě ve syntaktických vlastnostech promluvy poziční úroveň.
- Úroveň zprávy
- Funkční úroveň
- Poziční úroveň
- Fonologické kódování
- Gesto řeči
Další návrh úrovní zpracování řeči předkládá Willem J. M. Levelt být strukturován takto:[21]
- Konceptualizace
- Formulace
- Artikulace
- Vlastní monitorování
Levelt (1993) uvádí, že my jako řečníci si neuvědomujeme většinu těchto úrovní výkonu, jako je artikulace, který zahrnuje hnutí a umístění artikulátorů, formulace výpovědi, která zahrnuje vybraná slova a jejich výslovnost a pravidla, která je třeba dodržovat, aby byla výpověď gramatická. Úrovně reproduktorů si vědomě uvědomují záměr zprávy, která se vyskytuje na úrovni konceptualizace a pak znovu v vlastní monitorování což je situace, kdy by řečník zjistil jakékoli chyby, které by se mohly vyskytnout, a sám by se opravil.[21]
Klouzání jazyka
Jeden typ skluzu jazyka, který způsobí chybu v syntaxi promluvy, se nazývá transformační chyby. Transformační chyby jsou mentální operací navrženou Chomsky ve své Transformační hypotéze a má tři části, ke kterým může dojít k chybám ve výkonu. Tyto transformace se používají na úrovni podkladových struktur a předpovídají způsoby, jakými může dojít k chybě.[20]
- Strukturální analýza
- Strukturální změna
- Podmínky
Strukturální analýzachyby mohou nastat v důsledku aplikace (a) pravidla, které nesprávně analyzuje napjatou značku způsobující nesprávné použití pravidla, (b) pravidla, která se neuplatňuje, když by měla, nebo (c) pravidla, která se používá, když by neměla.
Tento příklad z Fromkin (1980) demonstruje pravidlo nesprávně analyzující napjatý marker a nesprávné použití inverze subjektu a pomocné inverze. The předmět-pomocná inverze je nesprávně analyzováno, na kterou strukturu se vztahuje, přičemž platí bez slovesa být v čase, když se pohybuje do polohy C. To způsobí, žedělat podporu "vyskytnout se a sloveso postrádat čas způsobující syntaktickou chybu.
6a. Chyba: Proč jsi někdy oaf? 6b. Cílová: Proč jsi někdy oaf?


| Transformace omylem | Chyba | Transformace v cíli | cílová |
|---|---|---|---|
| Základní struktura | [CP[C+ q] [TP[T '[T PRES] [VP[DP vy][PROTI'[PROTIbýt][[DP oaf]] [AdvP někdy][DP proč] | Základní struktura | [CP [C '[C + q] [TP [T' [T PRES] [VP[DP ty] [V '[V být][DP[D an][[NPoaf]] [AdvPněkdy][DP proč] |
| Pohyb Wh | [CP [DP Why] [C '[C + q] [TP [T' [T pres] [VP [DP you] [V '[V be] [AP [AP [A' [A an] [DP [ oaf]]]] [AdvP [Adv '[Adv někdy] [DP e] | Pohyb Wh | [CP [DP Why] [C '[C + q] [TP [T' [T pres] [VP [DP you] [V '[V be] [AP [AP [A' [A an] [DP [ oaf]]]] [AdvP [Adv '[Adv někdy] [DP e] |
| Subjekt-pomocná inverze | [CP [DP Why] [C '[C [T Pres] [[Cq e]] [TP [T' [T e] [VP [DP you] [V '[V be] [AP [AP [A' ' [A]] [DP [oaf]]]] [AdvP [Adv '[Adv někdy] [DP e] | Pohyb DP | [CP [DP Proč] [C '[C + q] [TP [DP vy] [T' [T PRES] [VP [V '[V be] [AP [AP [A' [A]] [DP [ oaf]]]] [AdvP [Adv '[Adv někdy] [DP e] |
| Do-podpora | [CP [DP Proč] [C '[C [T [V do] [[T PRES]] [[Cq e]] [TP [T' [T e] [VP [DP vy] [V '[V be ] [AP [AP [A '[A]] [DP [oaf]]]] [AdvP [Adv' [Adv někdy] [DP e] | Pomocná inverze subjektu | [CP [DP Proč] [C '[C [T [V být] [[T PRES]] Cq] [TP [DP vy] [T' [T [VP [V '[AP [AP [A' [A an] [DP [oaf]]]] [AdvP [Adv '[Adv někdy] [DP e] |
| Morfofonemický | Proč jsi někdy oaf? | Morfofonemický | Proč jsi někdy oaf? |
Následující příklad z Fromkin (1980) ukazuje, jak je pravidlo aplikováno, když by nemělo. Pravidlo inverze subjektu a pomocné inverze je v chybovém projevu vynecháno, což způsobí přeskakování přípony a uvedení času na sloveso „řekni“, které vytváří syntaktickou chybu. V cíli platí pravidlo předmět-pomocné a poté podpora, což vytváří gramaticky správnou strukturu.
7a. Chyba: A co řekl? 7b. Cíl: A co řekl?


| Transformace omylem | Chyba | Transformace v cíli | cílová |
|---|---|---|---|
| Základní struktura | [CP [CONJ And] [CP [C '[C + q] [TP [T' [T PAST] [VP [DP on] [V '[V říci] [DP co] | Základní struktura | [CP [CONJ And] [CP [C '[C + q] [TP [T' [T PAST] [VP [DP on] [V '[V říci] [DP co] |
| Pohyb Wh | [CP [CONJ And] [CP [DP what] [C '[C + q] [TP [T' [T PAST] [VP [DP he] [V '[V say] [DP e] | Pohyb DP a Wh | [CP [CONJ And] [CP [DP what] [C '[C + q] [TP [DP he] [T' [T PAST] [VP [V '[V say] |
| Affix Hopping | [CP [CONJ And] [CP [DP what] [C '[C + q] [TP [T' [T e] [VP [DP he] [V '[V say + PAST] [DP e] | Subjekt-pomocná inverze + podpora | [CP [CONJ And] [CP [DP what] [C '[C [T [V do] [[T PAST]] [[Cq]] [TP [DP he] [T' [T e] [VP [ DP e] [V '[V říci] [DPe] |
| Morfofonemický | A co řekl? | Morfofonemický | A co řekl? |
Tento příklad z Fromkin (1980) ukazuje, jak je pravidlo aplikováno, když by nemělo. Subjekt-pomocná inverze a podpora byla aplikována na idiomatické vyjádření způsobující vložení „dělat“, když by nemělo být použito v ungrammatickém projevu.
8a. Chyba: Jak to jde !! 8b. Cíl: Jak jdeme !!

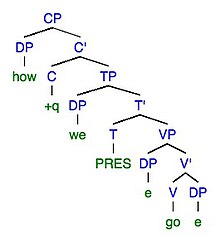
| Transformace omylem | Chyba | Transformace v cíli | cílová |
|---|---|---|---|
| Základní struktura | [CP [C '[C + q] [TP [T' [T PRES] [VP [DP jsme] [V '[V jít] [DP jak] | Základní struktura | [CP [C '[C + q] [TP [T' [T PRES] [VP [DP jsme] [V '[V jít] [DP jak] |
| Pohyb Wh | [CP [DP jak] [C '[C + q] [TP [T' [T PRES] [VP [DP my] [V '[V go] [DP e] | Pohyb Wh | [CP [DP jak] [C '[C + q] [TP [T' [T PRES] [VP [DP my] [V '[V go] [DP e] |
| Pohyb DP | [CP [DP jak] [C '[C + q] [TP [DP my] [T' [T PRES] [VP [DP e] [V '[V go] [DP e] | Pohyb DP | [CP [DP jak] [C '[C + q] [TP [DP my] [T' [T PRES] [VP [DP e] [V '[V go] [DP e] |
| Subjekt-pomocná inverze + podpora | [CP [DP How] [C '[C [T [V do] [[T PRES]] [[Cq]] [TP [DP we] [T' [T e] [VP [DP e] [V ' [V go] [DP e] | [CP [DP jak] [C '[C + q] [TP [DP my] [T' [T PRES] [VP [DP e] [V '[V go] [DP e] | |
| Morfofonemický | Jak to jde | Morfofonemický | Jak jdeme! |
Strukturální změnaPři provádění pravidel může dojít k chybám, i když je analýza značky fráze provedena správně. K tomu může dojít, když analýza vyžaduje více pravidel.
Následující příklad z Fromkin (1980) ukazuje, že pravidlo relativní klauze kopíruje určující fráze "chlapec" uvnitř doložka a to způsobí, že se přední strana připevní k značce Wh. Odstranění je poté přeskočeno a zanechá determinující frázi v klauzuli v chybové promluvě, což způsobí, že bude ungrammatická.
9a. Chyba: Chlapec, o kterém vím, že má kluka, má vlasy až sem. 9b. Cíl: Chlapec, o kterém vím, že má vlasy až sem.
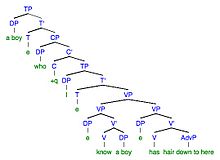
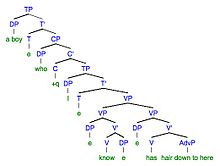
| Transformace omylem | Chyba | Transformace v cíli | cílová |
|---|---|---|---|
| Základní struktura | [TP [T '[Te] [CP [C' [C + q] [TP [T '[T e] [VP [VP [DP I] [V' [V vědět] [DP chlapec]]]] [ VP [DP who] [V '[V has] [AdvP hair down to here] | Základní struktura | [TP [T '[Te] [CP [C' [C + q] [TP [T '[T e] [VP [VP [DP I] [V' [V vědět] [DP chlapec]]]] [ VP [DP kdo] [V '[V má] [vlasy AdvP až sem] |
| Pohyb Wh | [TP [T '[Te] [CP [DP kdo] [C' [C + q] [TP [T '[T e] [VP [VP [DP I] [V' [V vědět] [DP chlapec ]]] [VP [DP kdo] [V '[V má] [AdvP vlasy až sem] | Pohyb Wh | [TP [T '[Te] [CP [DP kdo] [C' [C + q] [TP [T '[T e] [VP [VP [DP I] [V' [V vědět] [DP chlapec ]]] [VP [DP e] [V '[V má] [vlasy AdvP až sem] |
| Pohyb DP | [TP [DP chlapec]] [T '[Te] [CP [DP kdo] [C' [C + q] [TP [DP I] [T '[T e] [VP [VP [DP e] [ V '[V know] [DP a boy]]] [VP [DP e] [V' [V has] [AdvP hair down to here] | Pohyb DP | [TP [DP chlapec]] [T '[Te] [CP [DP kdo] [C' [C + q] [TP [DP I] [T '[T e] [VP [VP [DP e] [ V '[V know] [DP e]]] [VP [DP e] [V' [V má] [AdvP vlasy až sem] |
| Morfofonemický | Chlapec, o kterém vím, že má kluka, má vlasy až sem | Morfofonemický | Chlapec, kterého znám, má vlasy až sem |
Podmínky chyby omezují, kdy pravidlo lze a nelze použít.
Tento poslední příklad od Fromkina (1980) ukazuje, že pravidlo bylo aplikováno za určité podmínky, ve které je omezeno. Pravidlo subjektu-pomocné inverze nelze použít na vložené klauzule. V případě tohoto příkladu způsobuje syntaktickou chybu.
10a. Chyba: Vím, kde je pro to vrchol. 10b. Cíl: Vím, kde je vrchol.
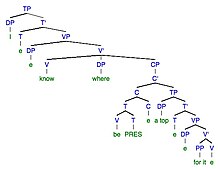
| Chybné transformace | Chyba | Transformace v cíli | cílová |
|---|---|---|---|
| Základní struktura | [TP [T '[T e] [VP [DP I] [V' [V vědět] [DP kde] [CP [C '[C e] [TP [T' [T PRES] [VP [DP nahoru ] [V '[PP za to] [V be] | Základní struktura | [TP [T '[T e] [VP [DP I] [V' [V vědět] [DP kde] [CP [C '[C e] [TP [T' [T PRES] [VP [DP nahoru ] [V '[PP za to] [V be] |
| Pohyb DP | [TP [DP I] [T '[T e] [VP [DP e] [V' [V vědět] [DP kde] [CP [C '[C e] [TP [DP nahoře] [T' [ T PRES] [VP [DP e] [V '[PP za to] [V be] | Pohyb DP | [TP [DP I] [T '[T e] [VP [DP e] [V' [V vědět] [DP kde] [CP [C '[C e] [TP [DP nahoře] [T' [ T PRES] [VP [DP e] [V '[PP za to] [V be] |
| Subjekt-pomocná inverze | [TP [DP I] [T '[T e] [VP [DP e] [V' [V vědět] [DP kde] [CP [C '[C [T [V být] [[T PRES]] [ [C e]] [TP [DP nahoru] [T '[T e] [VP [DP e] [V' [PP pro něj] [V e] | Affix Hopping | TP [DP I] [T '[T e] [VP [DP e] [V' [V vědět] [DP kde] [CP [C '[C e] [TP [DP nahoře] [T' [T e] [VP [DP e] [V '[PP za to] [V be + PRES] |
| Morfofonemický | Vím, kde je pro to vrchol | Morfofonemický | Vím, kde je vrchol |
Studie neslyšících Italů zjistila, že druhá osoba jednotného čísla indikativů se rozšíří na odpovídající formy imperativů a negativních imperativů.[22]
| Chyba | cílová |
|---|---|
| "pensi" | "pensa" |
| think-2nd PERS-SG-PRES-IND | think-2nd PERS-SG-IMP |
| "(myslíš" | "myslím" |
| Chyba | cílová |
|---|---|
| „non fa“ | „non fare“ |
| nedělat 2. PERS-SG-IMP | do-inf |
| "nedělat" | "nedělej" |
Následuje příklad převzatý z nizozemských dat, ve kterém je ve vložené klauzi promluvy (která není v holandštině povolena) vynechání slovesa, což má za následek chybu výkonu.[22]
| Chyba | cílová |
|---|---|
| „dit is de jongen die de tomaat snijdt en dit is de jongen die het brood“ | „deze jongen snijdt de tomaat en deze jongen het brood“ |
| „to je ten chlapec, co krájí rajče a to je ten chlapec, který chléb | „tento chlapec krájí rajče a tento chlapec chleba“ |
Studie provedená se Zulu mluvícími dětmi s jazykovým zpožděním zobrazovala chyby v jazykovém výkonu postrádající správnou morfologii pasivního slovesa.[22]
| Chyba | cílová |
|---|---|
| „Ulumile ihnashi“ | „Ulunywe yihnashi“ |
| „U-lum-ile i-hnashi | U-luny-w-e y-i-hnashi |
| sm1-skus-POSLEDNÍ NC5-kůň | sm1-bite-PASS-PAST COP-NC5-kůň |
| „Kousl, kůň ano.“ | „Kůň ho kousl.“ |
| Chyba | cílová |
|---|---|
| „Ulumile ifish“ | „Ulunywe yifish“ |
| sm1-kousnutí-POSLEDNÍ NC5-ryby | sm1-kousnutí-PASS-PAST COP-NC5-ryby |
| „Kousl, ryba ano.“ | „Ryba ho kousla.“ |
Klouby ruky
Jazykové složky Americký znakový jazyk (ASL) lze rozdělit na čtyři části; konfigurace ruky, místo artikulace, pohyb a další drobné parametry. Ruční konfigurace je dáno tvarem ruky, prstů a palců a je specifické pro používané znaménko. Umožňuje podepisujícímu vyjádřit, co chtějí komunikovat, rozšířením, ohnutím, ohnutím nebo rozšířením číslic; poloha palce k prstům; nebo zakřivení ruky. Existuje však neomezené množství možných konfigurací rukou, existuje 19 tříd připravených konfigurací rukou, jak je uvedeno v Slovník amerického znakového jazyka. Místo artikulace je konkrétní místo, kde se značka provádí, známé jako „místo podpisu“. „Místem podpisu“ může být celá tvář nebo její určitá část, oči, nos, tvář, ucho, krk, trup, jakákoli část paže nebo neutrální oblast před hlavou a tělem podpisujících. Hnutí je nejsložitější, protože může být obtížné jej analyzovat. Pohyb je omezen na směr, rotace zápěstí, lokální pohyby ruky a interakce rukou. Tyto pohyby mohou nastat jednotlivě, v pořadí nebo současně. Drobné parametry v ASL zahrnují kontaktní oblast, orientaci a uspořádání ruky. Jsou to podtřídy ruční konfigurace.
Chyby výkonu vedoucí k ungrammatickým znamením mohou být výsledkem procesů, které mění konfiguraci ruky, místo, pohyb nebo jiný parametr znaménka. Těmito procesy mohou být předvídání, konzervace nebo metateze. Očekávání je způsobeno, když je některá charakteristika dalšího znaménka začleněna do znaménka, které se právě provádí. Zachování je opakem očekávání, kdy se některá charakteristika předcházejícího znaménka přenáší do výkonu dalšího znaménka. Metateze nastane, když jsou dvě vlastnosti sousedních znaků spojeny do jedné při výkonu obou znaků.[20] Každá z těchto chyb bude mít za následek provedení nesprávného znaménka. To by mohlo mít za následek, že místo zamýšleného označení bude provedeno jiné označení, nebo neexistující znaky, které formy jsou možné a které formy nejsou možné kvůli strukturálním pravidlům.[20] Toto jsou hlavní typy chyb výkonu ve znakové řeči, ale ve výjimečných případech existuje také možnost chyb v pořadí provedených značek, což má za následek jiný význam, než jaký měl podepisující osoba v úmyslu.[20]
Jiné typy chyb
Nepřijatelné větyjsou ty, které, i když jsou gramatické, nejsou považovány za správné promluvy. Jsou považovány za nepřijatelné kvůli nedostatku našich kognitivních systémů pro jejich zpracování. Řečníkům a posluchačům může pomoci při provádění a zpracování těchto vět eliminováním časových a paměťových omezení, zvýšením motivace ke zpracování těchto promluv a použitím pera a papíru.[17] V angličtině existují tři typy vět, které jsou gramatické, ale reproduktory a posluchači je považují za nepřijatelné.[17]
- Opakované vložené klauzule: Sýr, který krysa, kterou kočka pronásledovala, je na stole.
- Multi Right Branching: To je kočka, která chytila krysu, která snědla sýr, který je na stole.
- Ambiguity or Garden Path Sentences: The horse raced past the barn fell
When a speaker makes an utterance they must translate their ideas into words, then syntactically proper phrases with proper pronunciation.[23] The speaker must have prior world knowledge and an understanding of the grammatical rules that their language enforces. When learning a second language or with children acquiring their first language, speakers usually have this knowledge before they are able to produce them.[23] Their speech is usually slow and deliberate, using phrases they have already mastered, and with practice their skills increase. Errors of linguistic performance are judged by the listener giving many interpretations if an utterance is well-formed or ungrammatical depending on the individual. As well the context in which an utterance is used can determine if the error would be considered or not.[24] When comparing "Who must telephone her?" and "Who need telephone her?" the former would be considered the ungrammatical phrase. However, when comparing it to "Who want telephone her?" it would be considered the grammatical phrase.[24] The listener may also be the speaker. When repeating sentences with errors if the error is not comprehended then it is performed. As well if the speaker does notice the error in the sentence they are supposed to repeat they are unaware of the difference between their well-formed sentence and the ungrammatical sentence.[20]An unacceptable utterance can also be performed due to a brain injury. Three types of brain injuries that could cause errors in performance were studied by Fromkin are dysarthria, apraxia and literal paraphasia. Dysartrie je vada v neuromuskulární connection that involves speech movement. The speech organs involved can be paralyzed or weakened, making it difficult or impossible for the speaker to produce a target utterance. Apraxie is when there is damage to the ability to initiate speech sounds with no paralysis or weakening of the articulators. Doslovný parafázie causes disorganization of linguistic properties, resulting in errors of slovosled z phonemes.[20] Having a brain injury and being unable to perform proper linguistic utterances, some individuals are still able to process complex sentences and formulate syntactically well formed sentences in their mind.[17]Child productions when they are acquiring language are full of errors of linguistic performance. Children must go from imitating adult speech to create new phrases of their own. They will need to use their cognitive operations of the knowledge of their language they are learning to determine the rules and properties of that language.[23] The following are examples of errors in English speaking children's productions.
- "I goed"
- "He runned"
In an elicited production experiment a child, Adam, was prompted to ask questions to an Old Lady[17]
| Experimentátor | Adam, ask the Old Lady what she'll do next. |
| Adam | Old Lady, what will you do now? |
| Stařenka | I'll fly to the moon. |
| Experimentátor | Adam, ask the Old Lady why she can't sit down. |
| Adam | Old Lady, why you can't sit down? |
| Stařenka | You haven't given me a chair. |
Měření výkonu
Průměrná délka promluvy
The most commonly used measure of syntax complexity is the mean length of utterance, also known as MLU.[25] This measure is independent from how often children talk and focuses on the complexity and development of their grammatical systems, including morphological and syntactic development.[26] The number representing a person's MLU corresponds to the complexity of the syntax being used. In general, as the MLU increases, the syntactic complexity also increases. Typically, the average MLU corresponds to a child's age due to their increase in working memory, which allows for sentences to be of greater syntactic complexity.[27] For example, the average MLU of a 7-year-old child is 7 words. However, children show more individual variability of syntactic performance with more complex syntax.[26] Complex syntax have a higher number of phrases and clause levels, therefore adding more words to the overall syntactic structure. Seeing as there are more individual differences in MLU and syntactic development as children get older, MLU is particularly used to measure grammatical complexity among school-aged children.[26] Other types of segmentation strategies for discourse are the T-unit and C-unit (communicative unit). If these two measurements are used to account for discourse, the average length of the sentence will be lower than if MLU is used alone. Both the T-units and C-units count each clause as a new unit, hence a lower number of units.
Typical MLU per age group can be found in the following table, according to Roger Brown 's five stages of syntactic and morphological development:[28]
| Etapa | MLU | Approximate Age (in months) |
|---|---|---|
| 1 | 1.0-2.0 | 12-26 |
| 2 | 2.0-2.5 | 27-30 |
| 3 | 2.5-3.0 | 31-34 |
| 4 | 3.0-3.75 | 35-40 |
| 5 | 3.75-4.5 | 41-46 |
| 6 | 4.5+ | 47+ |
Here are the steps for calculating MLU:[27]
- Acquire a language sample of about 50-100 utterances
- Count the number of morfémy said by the child, then divide by the number of utterances
- The investigator can assess what stage of syntactic development the child is at, based on their MLU
Here's an example of how to calculate MLU:
| Example utterance | Morpheme and MLU Analysis | Total MLU |
|---|---|---|
| go home now | go (=1) home (=1) now (=1) | 3 |
| I live in Billingham | I (=1) live (=1) in (=1) Billingham (=1) | 4 |
| Mommy kissed my Daddy | Mommy (=1) kiss (=1) -ed (=1) my (=1) daddy (=1) | 5 |
| I like your dogs | I (=1) like (=1) your (=1) dog (=1) -s (=1) | 5 |
In total there are 17 morphemes in this data set. In order to find the MLU, we divide the total number of morphemes (17) by the total number of utterances (4). In this particular data set, the mean length of utterance is 17/4 = 4.25.[29]
Clause density
Clause density refers to the degree to which utterances contain dependent doložky. This density is calculated as a ratio of the total number of clauses across sentences, divide by the number of sentences in a discourse sample.[25] For example, if the clause density is 2.0, the ratio would indicate that the sentence being analyzed has 2 clauses on average: one main clause and one subordinate clause.
Here is an example of how clause density is measured, using T-units, adapted from Silliman & Wilkinson 2007:[30]
| T-unit | Number of words | Number of clauses | Example sentences from a story |
|---|---|---|---|
| 1 | 12 | 2 | When the night was dark I was watching TV in my room |
| 2 | 5 | 1 | I heard a howling noise |
| 3 | 3 | 1 | I looked outside |
Indices of syntactic performance
Indices track structures to show a more comprehensive picture of a person's syntactic complexity. Some examples of indices are Development Sentence Scoring, the Index of Productive Syntax and the Syntactic Complexity Measure.
Developmental sentence scoring
Developmental Sentence Scoring is another method to measure syntactic performance as a clinical tool.[31] In this indice, each consecutive utterance, or sentence, elicited from a child is scored.[32] This is a commonly applied measurement of syntax for first and druhý jazyk learners, with samples gathered from both elicited and spontaneous oral discourse. Methods for eliciting speech for these samples come in many forms, such having the participant answering questions or re-telling a story. These elicited conversations are commonly tape-recorded for playback during analysis to see how well the person can incorporate syntax among other linguistic cues.[31] For every utterance elicited, the utterance will receive one point if it is a correct form used in adult speech. A score of 1 indicates the least complex syntactic form in the category, whereas a higher score reflects higher level grammaticality.[31] Points are specifically awarded to an utterance based on whether or not it contains any of the eight categories outlined below.[31]
Syntactic categories measured by developmental sentence scoring with examples:
Neurčitá zájmena 11a. Score of 1: it, this, that 11b. Score of 6: both, many, several, most, least
Osobní zájmena 12a. Score of 1: I, me, my, mine, you, your(s) 12b. Score of 6: Wh-pronouns (i.e. who, which, what, how) and wh-word + infinitiv (i.e. I know co to do)
Hlavní verb 13a. Score of 1: Uninflected verb (i.e. I "see" you) and copula, is or 's (i.e. It je red) 13b. Score of 6: Must, shall + verb (i.e. He "must come" or We "shall see"), have + verb + '-en' (i.e. I have eaten)
Sekundární verb 14a. Score of 1: Infinitival complements (i.e. I wan"na see" = I want vidět) 14b. Score of 6: Gerundium (tj. Houpání is fun)
Negativní 15a. Score of 1: it, this or that + spona nebo pomocný 'is' or 's + not (i.e. It's "not" mine) 15b. Score of 5: Uncontracted negative with 'have' (i.e. I have "not" eaten it), auxiliary'have'-negative contraction (i.e. I had"n't" eaten it), pronoun auxiliary 'have' contraction (i.e. I've "not" eaten it)
Conjunctions 16a. Score of 1: and 16b. Score of 6: where, than, how
Tázací reversals 17a. Score of 1: Reversal of copula (i.e. "Is it" red?) 17b. Score of 5: Reversal with three auxiliaries (i.e. "Could he" have been going?)
Otázky, které mají na začátku What, Whery, Why 18a. Score of 1: who or what (i.e. "What" do you mean?), what + noun (i.e. "What book" are you reading?) 18b. Score of 5: whose or which (i.e. "Which" do you want?), which + noun (i.e. "Which book" do you want?)
In particular, those categories that appear the earliest in speech receive a lower score, whereas later-appearing categories receive a higher score. If an entire sentence is correct according to adult-like forms, then the utterance would receive an extra point.[31] The eight categories above are the most commonly used structures in syntactic formation, thus structures such as possessives, articles, plurals, prepositional phrases, adverbs and descriptive adjectives were omitted and not scored.[31] Additionally, the scoring system is arbitrary when applied to certain structures. For example, there is no indication as to why "if" would receive four points rather than five. The scores of all the utterances are totalled in the end of the analysis and then averaged to get a final score. This means that the individual's final score reflects their entire syntactic complexity level, rather than syntactic level in a specific category.[31] The main advantage of development sentence scoring is that the final score represents the individual's general syntactic development and allows for easier tracking of changes in language development, making this tool effective for longitudinal studies.[31]
Index of productive syntax
Similar to Development Sentence Scoring, the Index of Productive Syntax evaluates the grammatical complexity of spontaneous language samples. After age 3, Index of Productive Syntax becomes more widely used than MLU to measure syntactic complexity in children.[33] This is because at around age 3, MLU does not distinguish between children of similar language competency as well as Index of Productive Syntax does. For this reason, MLU is initially used in early childhood development to track syntactic ability, then Index of Productive Syntax is used to maintain validity. Individual utterances in a discourse sample are scored based on the presence of 60 different syntactic forms, placed more generally under four subscales: jmenná fráze, slovesná fráze, question/negation and sentence structure forms.[34] After a sample is recorded, a corpus is then formed based on 100 utterance transcriptions with 60 different language structures being measured in each utterance. Not included in the corpus are imitations, self-repetitions and routines, which constitute language that does not represent productive language usage.[35] In each of the four sub-scales previously mentioned, the first two unique occurrences of a form are scored. After this, occurrences of a sub-scale are not scored. However, if a child has mastered a complex syntax structure earlier than expected, they will receive extra points.[35]
Standardizované testy
The six main tasks in standardized testing for syntax:[25]
- What is the level of syntactic complexity?
- What specific syntactic structures are found? (a syntactic content analysis)
- Are specific structures representative of what is known about syntactic development within the age range of standardization sample?
- What are the processing requirements of the test format? (a task analysis)
- Are processing requirements similar to or different from language processing in more naturalistic contexts?
- Is syntactic ability in naturalistic language predicted by performance on the test?
Some of the common standardized tests for measuring syntactic performance are the TOLD-2 Intermediate (Test of Language Development), the TOAL-2 (Test of Adolescent Language) and the CELF-R (Clinical Evaluation of Language Fundamentals, Revised Screening Test).
| Task being tested | TOLD-2 Intermediate | TOAL-2 | CELF-R |
|---|---|---|---|
| Naslouchání | Grammaticality Judgement (hears 1 sentence: judges correct/incorrect) | Syntactic Paraphrase (hears 3 sentences; marks 2 with similar meaning) | |
| Mluvení | Sentence Combining (hears 2-4 sentences, says 1 sentence that combines input sentences) | Sentence Imitation (hears 1 sentence, repeats verbatim) | Formulating Sentences (hears 1-2 words and sees a picture; makes up a sentence using words), Imitating Sentences (hears 1 sentence, repeats verbatim), Scrambled Sentences (hears/sees/reads sentence components out of order; says 2 different recorded/correct versions) |
| Čtení | Syntactic paraphrase (read 5 sentences; marks 2 with similar meaning) | ||
| Psaní | Sentence combining (reads 2-6 sentences; writes 1 sentence that combines input sentences) |
Viz také
- Langue a podmínečné propuštění
- Jazyková kompetence
- Generativní gramatika
- Transformační gramatika
- Psycholingvistika
- Syntax
Reference
- ^ Matthews, P. H. "performance." Oxfordská reference. 30. října 2014. http://www.oxfordreference.com/view/10.1093/acref/9780199202720.001.0001/acref-9780199202720-e-2494.
- ^ Reishaan, Abdul-Hussein Kadhim (2008). "The Relationship between Competence and Performance: Towards a Comprehensive TG Grammar". اداب الكـوفة. 1 (2).
- ^ Carlson, Marvin (2013), Výkon: Kritický úvod (revised ed.), Routledge, ISBN 9781136498657
- ^ Myers, David G. (December 2011), "8", Psychologie (10 ed.), worth publishers, p. 301, ISBN 9781429261784
- ^ A b Noam Chomsky.(2006).Language and Mind Third Edition. Cambridge University Press. ISBN 0-521-85819-4
- ^ A b Chomsky, Noame (1965), Aspekty teorie syntaxe, str.4, ISBN 0-262-53007-4
- ^ A b C de Saussure, F. (1986). Course in general linguistics (3rd ed.). (R. Harris, Trans.). Chicago: Open Court Publishing Company. (Původní práce publikovaná v roce 1972). p. 9-10, 15, 102.
- ^ Chomsky, Noam (1965). Aspekty teorie syntaxe. Cambridge: MA: MIT Press.
- ^ A b Chomsky, Noam (1986).Knowledge of Language. New York:Praeger. ISBN 0-275-90025-8.
- ^ Lacey, Nick (1998). Image and Representation: Key Concepts in Media Studies. Palgrave.
- ^ A Chomsky, Noam (1956). "Three Models for the Description of Language ". IRE Transactions on Information Theory 2 (2): 113 123.doi:10.1109/TIT.1956.1056813.
- ^ A b Smith, Neilson Voyne (1999). Chomsky: Nápady a ideály. Cambridge University Press. 37–39.
- ^ A b C d E F G h i j k Hawkins, John A. (2004). Efficiency and Complexity in Grammars. Oxford University Press. ISBN 978-0-199-25268-8.
- ^ A b C d E F G h i Wasow, Thomas (2002). Postverbal behavior. lecture notes, No. 145. Centre for the Study of Language and Information. ISBN 978-1-57586-401-3.
- ^ Karlsson, Fred; Voutilainen, Atro; Heikkilae, Juha; Anttila, Arto (January 1995), Constraint Grammar: A Language-Independent System for Parsing Unrestricted Text, Walter de Gruyter, ISBN 9783110882629
- ^ A b Sag, I. A. & Wasow, T., 2011. Performance-Compatible Competence Grammar. In: R. Borsley & K. Börjars, eds. Non-Transformational Syntax: Formal and Explicit Models of Grammar. s.l.:John Wiley & Sons, pp. 359-377.
- ^ A b C d E Stephen Crain; Rosalind Thornton (2000). Investigations in Universal Grammar: A Guide to Experiments on the Acquisition of Syntax and Semantics. MIT Stiskněte. ISBN 978-0-262-53180-1.
- ^ A b Lise Menn (2011). Psycholinguistics: Introduction and Applications. Plural Pub. ISBN 978-1-59756-283-6.
- ^ Montserrat Sanz; Itziar Laka; Michael K. Tanenhaus (29. srpna 2013). Language Down the Garden Path: The Cognitive and Biological Basis for Linguistic Structures. Oxford University Press. s. 2–. ISBN 978-0-19-967713-9.
- ^ A b C d E F G Victoria Fromkin (1980). Errors in linguistic performance: slips of the tongue, ear, pen, and hand. Akademický tisk. ISBN 978-0-12-268980-2.
- ^ A b Willem J. M. Levelt (1993). Speaking: From Intention to Articulation. MIT Stiskněte. ISBN 978-0-262-62089-5.
- ^ A b C Elisabetta Fava (2002). Clinical Linguistics: Theory and Applications in Speech Pathology and Therapy. Nakladatelství John Benjamins. str. 5–. ISBN 1-58811-223-3.
- ^ A b C Michael W. Eysenck; Mark T. Keane (2000). Kognitivní psychologie: Příručka pro studenty. Taylor & Francis. ISBN 978-0-86377-550-5.
- ^ A b Montserrat Sanz; Itziar Laka; Michael K. Tanenhaus (29. srpna 2013). Language Down the Garden Path: The Cognitive and Biological Basis for Linguistic Structures. Oxford University Press. str. 258–. ISBN 978-0-19-967713-9.
- ^ A b C Scott, CM & Stokes, SL 1995 'Measures of Syntax in School Age Children and Adolescents', Language, Speech & Hearing Services in Schools, vol.56, pp. 309-320
- ^ A b C Huttenlocher, J, Vasilyeva, M, Cymerman, E & Levine, S 2002, 'Language input and child syntax', Kognitivní psychologie, sv. 45, pp. 337–374.
- ^ A b Everyday Language Discovering the Hidden Powers of Speech and Language 2014, Morphology and MLU. Dostupné z: <http://everydaylanguage.qwriting.qc.cuny.edu/2014/03/08/morphology-and-mlu/ >. [12 November 2014].
- ^ Brown, R 1973, První jazyk: Raná stadia, George Allen & Unwin, London.
- ^ Speech Language Therapy Info 2014, Mean Length of Utterance. Dostupné z: <http://www.sltinfo.com/mean-length-of-utterance/ >. [12 November 2014].
- ^ Silliman, ER & Wilkinson, LC 2007, Language and Literacy Learning in Schools. The Guilford Press, New York.
- ^ A b C d E F G h Rheinhardt, KM 1972, 'The Developmental Sentence Scoring Procedure ', Independent Studies and Capstones, sv. 314.
- ^ Politzer, RL, 1974, 'Developmental Sentence Scoring as a Method of Measuring Second Language Acquisition ', Modern Language Journal, sv. 58, č. 5/6, pp. 245.
- ^ Lavie, A, Sagae, K, MacWhinney, B, 'Automatic Measurement of Syntactic Development in Child Language ', Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, pp.197-204.
- ^ Springer Reference 2014, Index of Productive Syntax (IPSyn). Dostupné z: <http://www.springerreference.com/docs/html/chapterdbid/333184.html >. [26 October 2014].
- ^ A b Moyle, M & Long, S 2013, 'Index of Productive Syntax (IPSyn)', Encyklopedie poruch autistického spektra, pp. 1566-1568