Rekurzivní metoda nejmenších čtverců (RLS) je adaptivní filtr algoritmus, který rekurzivně najde koeficienty, které minimalizují a vážené lineární nejmenší čtverce nákladová funkce týkající se vstupních signálů. Tento přístup je na rozdíl od jiných algoritmů, jako je například nejméně střední čtverce (LMS), jejichž cílem je snížit střední kvadratická chyba . Při odvození RLS jsou brány v úvahu vstupní signály deterministický , zatímco pro LMS a podobný algoritmus jsou brány v úvahu stochastický . Ve srovnání s většinou svých konkurentů vykazuje RLS extrémně rychlou konvergenci. Tato výhoda však přichází za cenu vysoké výpočetní složitosti.
Motivace RLS objevil Gauss ale ležel nepoužívaný nebo ignorovaný až do roku 1950, kdy Plackett znovu objevil původní Gaussovo dílo z roku 1821. Obecně lze RLS použít k řešení jakéhokoli problému, který lze vyřešit adaptivní filtry . Předpokládejme například, že jde o signál d ( n ) { displaystyle d (n)} hlučný kanál který způsobí, že bude přijímán jako
X ( n ) = ∑ k = 0 q b n ( k ) d ( n − k ) + proti ( n ) { displaystyle x (n) = součet _ {k = 0} ^ {q} b_ {n} (k) d (n-k) + v (n)} kde proti ( n ) { displaystyle v (n)} aditivní hluk . Účelem filtru RLS je obnovit požadovaný signál d ( n ) { displaystyle d (n)} str + 1 { displaystyle p + 1} JEDLE filtr, w { displaystyle mathbf {w}}
d ( n ) ≈ ∑ k = 0 str w ( k ) X ( n − k ) = w T X n { displaystyle d (n) přibližně součet _ {k = 0} ^ {p} w (k) x (nk) = mathbf {w} ^ { mathit {T}} mathbf {x} _ { n}} kde X n = [ X ( n ) X ( n − 1 ) … X ( n − str ) ] T { displaystyle mathbf {x} _ {n} = [x (n) quad x (n-1) quad ldots quad x (n-p)] ^ {T}} vektor sloupce obsahující str + 1 { displaystyle p + 1} X ( n ) { displaystyle x (n)}
d ^ ( n ) = ∑ k = 0 str w n ( k ) X ( n − k ) = w n T X n { displaystyle { hat {d}} (n) = součet _ {k = 0} ^ {p} w_ {n} (k) x (nk) = mathbf {w} _ {n} ^ { mathit {T}} mathbf {x} _ {n}} Cílem je odhadnout parametry filtru w { displaystyle mathbf {w}} n { displaystyle n} w n { displaystyle mathbf {w} _ {n}} w n + 1 { displaystyle mathbf {w} _ {n + 1}} w n { displaystyle mathbf {w} _ {n}} přemístit , w n T { displaystyle mathbf {w} _ {n} ^ { mathit {T}}} řádek vektor . The maticový produkt w n T X n { displaystyle mathbf {w} _ {n} ^ { mathit {T}} mathbf {x} _ {n}} Tečkovaný produkt z w n { displaystyle mathbf {w} _ {n}} X n { displaystyle mathbf {x} _ {n}} d ^ ( n ) { displaystyle { hat {d}} (n)} "dobrý" -li d ^ ( n ) − d ( n ) { displaystyle { hat {d}} (n) -d (n)} nejmenší čtverce smysl.
Jak se čas vyvíjí, je žádoucí vyhnout se zcela přepracování algoritmu nejmenších čtverců pro nalezení nového odhadu pro w n + 1 { displaystyle mathbf {w} _ {n + 1}} w n { displaystyle mathbf {w} _ {n}}
Výhodou algoritmu RLS je, že není nutné převracet matice, což šetří výpočetní náklady. Další výhodou je, že poskytuje intuici za takovými výsledky jako Kalmanův filtr .
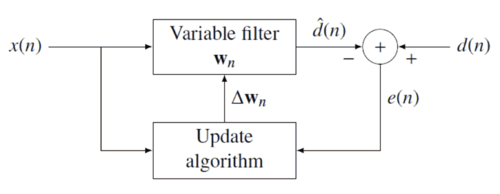
Diskuse Myšlenkou filtrů RLS je minimalizovat a nákladová funkce C { displaystyle C} w n { displaystyle mathbf {w} _ {n}} E ( n ) { displaystyle e (n)} d ( n ) { displaystyle d (n)} negativní zpětná vazba níže uvedený diagram:
Chyba implicitně závisí na koeficientech filtru prostřednictvím odhadu d ^ ( n ) { displaystyle { hat {d}} (n)}
E ( n ) = d ( n ) − d ^ ( n ) { displaystyle e (n) = d (n) - { hat {d}} (n)} Vážená chybová funkce nejmenších čtverců C { displaystyle C} E ( n ) { displaystyle e (n)}
C ( w n ) = ∑ i = 0 n λ n − i E 2 ( i ) { displaystyle C ( mathbf {w} _ {n}) = součet _ {i = 0} ^ {n} lambda ^ {n-i} e ^ {2} (i)} kde 0 < λ ≤ 1 { displaystyle 0 < lambda leq 1}
Funkce nákladů je minimalizována převzetím částečných derivací pro všechny položky k { displaystyle k} w n { displaystyle mathbf {w} _ {n}}
∂ C ( w n ) ∂ w n ( k ) = ∑ i = 0 n 2 λ n − i E ( i ) ∂ E ( i ) ∂ w n ( k ) = − ∑ i = 0 n 2 λ n − i E ( i ) X ( i − k ) = 0 k = 0 , 1 , ⋯ , str { displaystyle { frac { částečné C ( mathbf {w} _ {n})} { částečné w_ {n} (k)}} = součet _ {i = 0} ^ {n} , 2 lambda ^ {ni} e (i) , { frac { částečné e (i)} { částečné w_ {n} (k)}} = {-} součet _ {i = 0} ^ {n } , 2 lambda ^ {ni} e (i) , x (ik) = 0 qquad k = 0,1, cdots, p} Dále vyměňte E ( n ) { displaystyle e (n)}
∑ i = 0 n λ n − i [ d ( i ) − ∑ l = 0 str w n ( l ) X ( i − l ) ] X ( i − k ) = 0 k = 0 , 1 , ⋯ , str { displaystyle sum _ {i = 0} ^ {n} lambda ^ {ni} left [d (i) - sum _ {l = 0} ^ {p} w_ {n} (l) x ( il) right] x (ik) = 0 qquad k = 0,1, cdots, p} Přeskupení výtěžků rovnice
∑ l = 0 str w n ( l ) [ ∑ i = 0 n λ n − i X ( i − l ) X ( i − k ) ] = ∑ i = 0 n λ n − i d ( i ) X ( i − k ) k = 0 , 1 , ⋯ , str { displaystyle sum _ {l = 0} ^ {p} w_ {n} (l) left [ sum _ {i = 0} ^ {n} lambda ^ {ni} , x (il) x (ik) right] = sum _ {i = 0} ^ {n} lambda ^ {ni} d (i) x (ik) qquad k = 0,1, cdots, p} Tuto formu lze vyjádřit pomocí matic
R X ( n ) w n = r d X ( n ) { displaystyle mathbf {R} _ {x} (n) , mathbf {w} _ {n} = mathbf {r} _ {dx} (n)} kde R X ( n ) { displaystyle mathbf {R} _ {x} (n)} kovarianční vzorek matice pro X ( n ) { displaystyle x (n)} r d X ( n ) { displaystyle mathbf {r} _ {dx} (n)} křížová kovariance mezi d ( n ) { displaystyle d (n)} X ( n ) { displaystyle x (n)}
w n = R X − 1 ( n ) r d X ( n ) { displaystyle mathbf {w} _ {n} = mathbf {R} _ {x} ^ {- 1} (n) , mathbf {r} _ {dx} (n)} Toto je hlavní výsledek diskuse.
Výběr λ { displaystyle lambda} Menší λ { displaystyle lambda} více citlivé na nedávné vzorky, což znamená více fluktuací koeficientů filtru. The λ = 1 { displaystyle lambda = 1} rostoucí okno RLS algoritmus . V praxi, λ { displaystyle lambda} [1] λ { displaystyle lambda} [2]
Rekurzivní algoritmus Výsledkem diskuse byla jediná rovnice pro určení vektoru koeficientu, který minimalizuje nákladovou funkci. V této části chceme odvodit rekurzivní řešení formuláře
w n = w n − 1 + Δ w n − 1 { displaystyle mathbf {w} _ {n} = mathbf {w} _ {n-1} + Delta mathbf {w} _ {n-1}} kde Δ w n − 1 { displaystyle Delta mathbf {w} _ {n-1}} n − 1 { displaystyle {n-1}} r d X ( n ) { displaystyle mathbf {r} _ {dx} (n)} r d X ( n − 1 ) { displaystyle mathbf {r} _ {dx} (n-1)}
r d X ( n ) { displaystyle mathbf {r} _ {dx} (n)} = ∑ i = 0 n λ n − i d ( i ) X ( i ) { displaystyle = součet _ {i = 0} ^ {n} lambda ^ {n-i} d (i) mathbf {x} (i)} = ∑ i = 0 n − 1 λ n − i d ( i ) X ( i ) + λ 0 d ( n ) X ( n ) { displaystyle = sum _ {i = 0} ^ {n-1} lambda ^ {ni} d (i) mathbf {x} (i) + lambda ^ {0} d (n) mathbf { x} (n)} = λ r d X ( n − 1 ) + d ( n ) X ( n ) { displaystyle = lambda mathbf {r} _ {dx} (n-1) + d (n) mathbf {x} (n)}
kde X ( i ) { displaystyle mathbf {x} (i)} str + 1 { displaystyle {p + 1}}
X ( i ) = [ X ( i ) , X ( i − 1 ) , … , X ( i − str ) ] T { displaystyle mathbf {x} (i) = [x (i), x (i-1), tečky, x (i-p)] ^ {T}} Podobně vyjadřujeme R X ( n ) { displaystyle mathbf {R} _ {x} (n)} R X ( n − 1 ) { displaystyle mathbf {R} _ {x} (n-1)}
R X ( n ) { displaystyle mathbf {R} _ {x} (n)} = ∑ i = 0 n λ n − i X ( i ) X T ( i ) { displaystyle = sum _ {i = 0} ^ {n} lambda ^ {n-i} mathbf {x} (i) mathbf {x} ^ {T} (i)} = λ R X ( n − 1 ) + X ( n ) X T ( n ) { displaystyle = lambda mathbf {R} _ {x} (n-1) + mathbf {x} (n) mathbf {x} ^ {T} (n)}
Abychom vygenerovali vektor koeficientu, zajímá nás inverzní funkce deterministické auto-kovarianční matice. Pro tento úkol Identita matice Woodburyho přijde vhod. S
A { displaystyle A} = λ R X ( n − 1 ) { displaystyle = lambda mathbf {R} _ {x} (n-1)} ( str + 1 ) { displaystyle (p + 1)} ( str + 1 ) { displaystyle (p + 1)} U { displaystyle U} = X ( n ) { displaystyle = mathbf {x} (n)} ( str + 1 ) { displaystyle (p + 1)} PROTI { displaystyle V} = X T ( n ) { displaystyle = mathbf {x} ^ {T} (n)} ( str + 1 ) { displaystyle (p + 1)} C { displaystyle C} = Já 1 { displaystyle = mathbf {I} _ {1}} matice identity
Následuje identita matice Woodbury
R X − 1 ( n ) { displaystyle mathbf {R} _ {x} ^ {- 1} (n)} = { displaystyle =} [ λ R X ( n − 1 ) + X ( n ) X T ( n ) ] − 1 { displaystyle left [ lambda mathbf {R} _ {x} (n-1) + mathbf {x} (n) mathbf {x} ^ {T} (n) right] ^ {- 1 }} = { displaystyle =} λ − 1 R X − 1 ( n − 1 ) { displaystyle lambda ^ {- 1} mathbf {R} _ {x} ^ {- 1} (n-1)} − λ − 1 R X − 1 ( n − 1 ) X ( n ) { displaystyle - lambda ^ {- 1} mathbf {R} _ {x} ^ {- 1} (n-1) mathbf {x} (n)} { 1 + X T ( n ) λ − 1 R X − 1 ( n − 1 ) X ( n ) } − 1 X T ( n ) λ − 1 R X − 1 ( n − 1 ) { displaystyle left {1+ mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {R} _ {x} ^ {- 1} (n-1) mathbf { x} (n) vpravo } ^ {- 1} mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {R} _ {x} ^ {- 1} (n- 1)}
Abychom se přizpůsobili standardní literatuře, definujeme ji
P ( n ) { displaystyle mathbf {P} (n)} = R X − 1 ( n ) { displaystyle = mathbf {R} _ {x} ^ {- 1} (n)} = λ − 1 P ( n − 1 ) − G ( n ) X T ( n ) λ − 1 P ( n − 1 ) { displaystyle = lambda ^ {- 1} mathbf {P} (n-1) - mathbf {g} (n) mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {P} (n-1)}
Kde vektor zisku G ( n ) { displaystyle g (n)}
G ( n ) { displaystyle mathbf {g} (n)} = λ − 1 P ( n − 1 ) X ( n ) { 1 + X T ( n ) λ − 1 P ( n − 1 ) X ( n ) } − 1 { displaystyle = lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n) left {1+ mathbf {x} ^ {T} (n) lambda ^ {-1} mathbf {P} (n-1) mathbf {x} (n) doprava } ^ {- 1}} = P ( n − 1 ) X ( n ) { λ + X T ( n ) P ( n − 1 ) X ( n ) } − 1 { displaystyle = mathbf {P} (n-1) mathbf {x} (n) levý { lambda + mathbf {x} ^ {T} (n) mathbf {P} (n-1 ) mathbf {x} (n) vpravo } ^ {- 1}}
Než půjdeme dál, je třeba vzít G ( n ) { displaystyle mathbf {g} (n)}
G ( n ) { 1 + X T ( n ) λ − 1 P ( n − 1 ) X ( n ) } { displaystyle mathbf {g} (n) vlevo {1+ mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {P} (n-1) mathbf {x } (n) doprava }} = λ − 1 P ( n − 1 ) X ( n ) { displaystyle = lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n)} G ( n ) + G ( n ) X T ( n ) λ − 1 P ( n − 1 ) X ( n ) { displaystyle mathbf {g} (n) + mathbf {g} (n) mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n)} = λ − 1 P ( n − 1 ) X ( n ) { displaystyle = lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n)}
Odečtením druhého členu na levé straně se získá výnos
G ( n ) { displaystyle mathbf {g} (n)} = λ − 1 P ( n − 1 ) X ( n ) − G ( n ) X T ( n ) λ − 1 P ( n − 1 ) X ( n ) { displaystyle = lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n) - mathbf {g} (n) mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {P} (n-1) mathbf {x} (n)} = λ − 1 [ P ( n − 1 ) − G ( n ) X T ( n ) P ( n − 1 ) ] X ( n ) { displaystyle = lambda ^ {- 1} left [ mathbf {P} (n-1) - mathbf {g} (n) mathbf {x} ^ {T} (n) mathbf {P} (n-1) vpravo] mathbf {x} (n)}
S rekurzivní definicí P ( n ) { displaystyle mathbf {P} (n)}
G ( n ) = P ( n ) X ( n ) { displaystyle mathbf {g} (n) = mathbf {P} (n) mathbf {x} (n)} Nyní jsme připraveni rekurzi dokončit. Jak bylo diskutováno
w n { displaystyle mathbf {w} _ {n}} = P ( n ) r d X ( n ) { displaystyle = mathbf {P} (n) , mathbf {r} _ {dx} (n)} = λ P ( n ) r d X ( n − 1 ) + d ( n ) P ( n ) X ( n ) { displaystyle = lambda mathbf {P} (n) , mathbf {r} _ {dx} (n-1) + d (n) mathbf {P} (n) , mathbf {x} (n)}
Druhý krok vyplývá z rekurzivní definice r d X ( n ) { displaystyle mathbf {r} _ {dx} (n)} P ( n ) { displaystyle mathbf {P} (n)} G ( n ) { displaystyle mathbf {g} (n)}
w n { displaystyle mathbf {w} _ {n}} = λ [ λ − 1 P ( n − 1 ) − G ( n ) X T ( n ) λ − 1 P ( n − 1 ) ] r d X ( n − 1 ) + d ( n ) G ( n ) { displaystyle = lambda vlevo [ lambda ^ {- 1} mathbf {P} (n-1) - mathbf {g} (n) mathbf {x} ^ {T} (n) lambda ^ {-1} mathbf {P} (n-1) vpravo] mathbf {r} _ {dx} (n-1) + d (n) mathbf {g} (n)} = P ( n − 1 ) r d X ( n − 1 ) − G ( n ) X T ( n ) P ( n − 1 ) r d X ( n − 1 ) + d ( n ) G ( n ) { displaystyle = mathbf {P} (n-1) mathbf {r} _ {dx} (n-1) - mathbf {g} (n) mathbf {x} ^ {T} (n) mathbf {P} (n-1) mathbf {r} _ {dx} (n-1) + d (n) mathbf {g} (n)} = P ( n − 1 ) r d X ( n − 1 ) + G ( n ) [ d ( n ) − X T ( n ) P ( n − 1 ) r d X ( n − 1 ) ] { displaystyle = mathbf {P} (n-1) mathbf {r} _ {dx} (n-1) + mathbf {g} (n) left [d (n) - mathbf {x} ^ {T} (n) mathbf {P} (n-1) mathbf {r} _ {dx} (n-1) vpravo]}
S w n − 1 = P ( n − 1 ) r d X ( n − 1 ) { displaystyle mathbf {w} _ {n-1} = mathbf {P} (n-1) mathbf {r} _ {dx} (n-1)}
w n { displaystyle mathbf {w} _ {n}} = w n − 1 + G ( n ) [ d ( n ) − X T ( n ) w n − 1 ] { displaystyle = mathbf {w} _ {n-1} + mathbf {g} (n) vlevo [d (n) - mathbf {x} ^ {T} (n) mathbf {w} _ {n-1} vpravo]} = w n − 1 + G ( n ) α ( n ) { displaystyle = mathbf {w} _ {n-1} + mathbf {g} (n) alpha (n)}
kde α ( n ) = d ( n ) − X T ( n ) w n − 1 { displaystyle alpha (n) = d (n) - mathbf {x} ^ {T} (n) mathbf {w} _ {n-1}} a priori a posteriori po filtr je aktualizován:
E ( n ) = d ( n ) − X T ( n ) w n { displaystyle e (n) = d (n) - mathbf {x} ^ {T} (n) mathbf {w} _ {n}} To znamená, že jsme našli korekční faktor
Δ w n − 1 = G ( n ) α ( n ) { displaystyle Delta mathbf {w} _ {n-1} = mathbf {g} (n) alfa (n)} Tento intuitivně uspokojivý výsledek naznačuje, že korekční faktor je přímo úměrný jak chybě, tak vektoru zisku, který řídí váhu požadované citlivosti, prostřednictvím váhového faktoru, λ { displaystyle lambda}
Shrnutí algoritmu RLS Algoritmus RLS pro a str Filtr RLS -th order lze shrnout jako
Parametry: str = { displaystyle p =} λ = { displaystyle lambda =} δ = { displaystyle delta =} P ( 0 ) { displaystyle mathbf {P} (0)} Inicializace: w ( n ) = 0 { displaystyle mathbf {w} (n) = 0} X ( k ) = 0 , k = − str , … , − 1 { displaystyle x (k) = 0, k = -p, tečky, -1} d ( k ) = 0 , k = − str , … , − 1 { displaystyle d (k) = 0, k = -p, tečky, -1} P ( 0 ) = δ Já { displaystyle mathbf {P} (0) = delta I} Já { displaystyle I} matice identity hodnosti str + 1 { displaystyle p + 1} Výpočet: Pro n = 1 , 2 , … { displaystyle n = 1,2, tečky} X ( n ) = [ X ( n ) X ( n − 1 ) ⋮ X ( n − str ) ] { displaystyle mathbf {x} (n) = vlevo [{ začátek {matice} x (n) x (n-1) vdots x (np) konec {matice}} že jo]}
α ( n ) = d ( n ) − X T ( n ) w ( n − 1 ) { displaystyle alpha (n) = d (n) - mathbf {x} ^ {T} (n) mathbf {w} (n-1)} G ( n ) = P ( n − 1 ) X ( n ) { λ + X T ( n ) P ( n − 1 ) X ( n ) } − 1 { displaystyle mathbf {g} (n) = mathbf {P} (n-1) mathbf {x} (n) left { lambda + mathbf {x} ^ {T} (n) mathbf {P} (n-1) mathbf {x} (n) doprava } ^ {- 1}} P ( n ) = λ − 1 P ( n − 1 ) − G ( n ) X T ( n ) λ − 1 P ( n − 1 ) { displaystyle mathbf {P} (n) = lambda ^ {- 1} mathbf {P} (n-1) - mathbf {g} (n) mathbf {x} ^ {T} (n) lambda ^ {- 1} mathbf {P} (n-1)} w ( n ) = w ( n − 1 ) + α ( n ) G ( n ) { displaystyle mathbf {w} (n) = mathbf {w} (n-1) + , alpha (n) mathbf {g} (n)}
Rekurze pro P { displaystyle P} Algebraická Riccatiho rovnice a tak přitahuje paralely k Kalmanův filtr .[3]
Mřížkový rekurzivní filtr nejmenších čtverců (LRLS) The Mřížkové rekurzivní nejméně čtverce adaptivní filtr souvisí se standardním RLS kromě toho, že vyžaduje méně aritmetických operací (pořadí N). Nabízí další výhody oproti běžným algoritmům LMS, jako jsou rychlejší rychlosti konvergence, modulární struktura a necitlivost na variace v šíření vlastních čísel vstupní korelační matice. Popsaný algoritmus LRLS je založen na a posteriori chyby a zahrnuje normalizovanou formu. Odvození je podobné standardnímu algoritmu RLS a je založeno na definici d ( k ) { displaystyle d (k) , !} d ( k ) = X ( k ) { displaystyle d (k) = x (k) , !} X ( k − 1 ) { displaystyle x (k-1) , !} d ( k ) = X ( k − i − 1 ) { displaystyle d (k) = x (k-i-1) , !} X ( k ) { displaystyle x (k) , !} [4]
Souhrn parametrů κ F ( k , i ) { displaystyle kappa _ {f} (k, i) , !} κ b ( k , i ) { displaystyle kappa _ {b} (k, i) , !} E F ( k , i ) { displaystyle e_ {f} (k, i) , !} a posteriori chyba předpovědi vpřed E b ( k , i ) { displaystyle e_ {b} (k, i) , !} a posteriori chyba zpětné predikce ξ b m i n d ( k , i ) { displaystyle xi _ {b_ {min}} ^ {d} (k, i) , !} ξ F m i n d ( k , i ) { displaystyle xi _ {f_ {min}} ^ {d} (k, i) , !} y ( k , i ) { displaystyle gamma (k, i) , !} a priori a a posteriori chyby proti i ( k ) { displaystyle v_ {i} (k) , !} ϵ { displaystyle epsilon , !} Shrnutí algoritmu LRLS Algoritmus pro filtr LRLS lze shrnout jako
Inicializace: Pro i = 0,1, ..., N δ ( − 1 , i ) = δ D ( − 1 , i ) = 0 { displaystyle delta (-1, i) = delta _ {D} (- 1, i) = 0 , !} ξ b m i n d ( − 1 , i ) = ξ F m i n d ( − 1 , i ) = ϵ { displaystyle xi _ {b_ {min}} ^ {d} (- 1, i) = xi _ {f_ {min}} ^ {d} (- 1, i) = epsilon} y ( − 1 , i ) = 1 { displaystyle gamma (-1, i) = 1 , !} E b ( − 1 , i ) = 0 { displaystyle e_ {b} (- 1, i) = 0 , !} Konec Výpočet: Pro k ≥ 0 y ( k , 0 ) = 1 { displaystyle gamma (k, 0) = 1 , !} E b ( k , 0 ) = E F ( k , 0 ) = X ( k ) { displaystyle e_ {b} (k, 0) = e_ {f} (k, 0) = x (k) , !} ξ b m i n d ( k , 0 ) = ξ F m i n d ( k , 0 ) = X 2 ( k ) + λ ξ F m i n d ( k − 1 , 0 ) { displaystyle xi _ {b_ {min}} ^ {d} (k, 0) = xi _ {f_ {min}} ^ {d} (k, 0) = x ^ {2} (k) + lambda xi _ {f_ {min}} ^ {d} (k-1,0) , !} E ( k , 0 ) = d ( k ) { displaystyle e (k, 0) = d (k) , !} Pro i = 0,1, ..., N δ ( k , i ) = λ δ ( k − 1 , i ) + E b ( k − 1 , i ) E F ( k , i ) y ( k − 1 , i ) { displaystyle delta (k, i) = lambda delta (k-1, i) + { frac {e_ {b} (k-1, i) e_ {f} (k, i)} { gama (k-1, i)}}} y ( k , i + 1 ) = y ( k , i ) − E b 2 ( k , i ) ξ b m i n d ( k , i ) { displaystyle gamma (k, i + 1) = gamma (k, i) - { frac {e_ {b} ^ {2} (k, i)} { xi _ {b_ {min}} ^ {d} (k, i)}}} κ b ( k , i ) = δ ( k , i ) ξ F m i n d ( k , i ) { displaystyle kappa _ {b} (k, i) = { frac { delta (k, i)} { xi _ {f_ {min}} ^ {d} (k, i)}}} κ F ( k , i ) = δ ( k , i ) ξ b m i n d ( k − 1 , i ) { displaystyle kappa _ {f} (k, i) = { frac { delta (k, i)} { xi _ {b_ {min}} ^ {d} (k-1, i)}} } E b ( k , i + 1 ) = E b ( k − 1 , i ) − κ b ( k , i ) E F ( k , i ) { displaystyle e_ {b} (k, i + 1) = e_ {b} (k-1, i) - kappa _ {b} (k, i) e_ {f} (k, i) , !} E F ( k , i + 1 ) = E F ( k , i ) − κ F ( k , i ) E b ( k − 1 , i ) { displaystyle e_ {f} (k, i + 1) = e_ {f} (k, i) - kappa _ {f} (k, i) e_ {b} (k-1, i) , !} ξ b m i n d ( k , i + 1 ) = ξ b m i n d ( k − 1 , i ) − δ ( k , i ) κ b ( k , i ) { displaystyle xi _ {b_ {min}} ^ {d} (k, i + 1) = xi _ {b_ {min}} ^ {d} (k-1, i) - delta (k, i) kappa _ {b} (k, i)} ξ F m i n d ( k , i + 1 ) = ξ F m i n d ( k , i ) − δ ( k , i ) κ F ( k , i ) { displaystyle xi _ {f_ {min}} ^ {d} (k, i + 1) = xi _ {f_ {min}} ^ {d} (k, i) - delta (k, i) kappa _ {f} (k, i)} Filtrování zpětné vazby δ D ( k , i ) = λ δ D ( k − 1 , i ) + E ( k , i ) E b ( k , i ) y ( k , i ) { displaystyle delta _ {D} (k, i) = lambda delta _ {D} (k-1, i) + { frac {e (k, i) e_ {b} (k, i) } { gamma (k, i)}}} proti i ( k ) = δ D ( k , i ) ξ b m i n d ( k , i ) { displaystyle v_ {i} (k) = { frac { delta _ {D} (k, i)} { xi _ {b_ {min}} ^ {d} (k, i)}}} E ( k , i + 1 ) = E ( k , i ) − proti i ( k ) E b ( k , i ) { displaystyle e (k, i + 1) = e (k, i) -v_ {i} (k) e_ {b} (k, i) , !} KonecKonec
Normalizovaný mřížkový rekurzivní filtr nejmenších čtverců (NLRLS) Normalizovaná forma LRLS má méně rekurzí a proměnných. Lze jej vypočítat aplikací normalizace na vnitřní proměnné algoritmu, která udrží jejich velikost ohraničenou jednou. Toto se obecně nepoužívá v aplikacích v reálném čase z důvodu počtu operací dělení a druhé odmocniny, které přicházejí s vysokou výpočetní zátěží.
Souhrn algoritmu NLRLS Algoritmus pro filtr NLRLS lze shrnout jako
Inicializace: Pro i = 0,1, ..., N δ ¯ ( − 1 , i ) = 0 { displaystyle { overline { delta}} (- 1, i) = 0 , !} δ ¯ D ( − 1 , i ) = 0 { displaystyle { overline { delta}} _ {D} (- 1, i) = 0 , !} E ¯ b ( − 1 , i ) = 0 { displaystyle { overline {e}} _ {b} (- 1, i) = 0 , !} Konec σ X 2 ( − 1 ) = λ σ d 2 ( − 1 ) = ϵ { displaystyle sigma _ {x} ^ {2} (- 1) = lambda sigma _ {d} ^ {2} (- 1) = epsilon , !} Výpočet: Pro k ≥ 0 σ X 2 ( k ) = λ σ X 2 ( k − 1 ) + X 2 ( k ) { displaystyle sigma _ {x} ^ {2} (k) = lambda sigma _ {x} ^ {2} (k-1) + x ^ {2} (k) , !} σ d 2 ( k ) = λ σ d 2 ( k − 1 ) + d 2 ( k ) { displaystyle sigma _ {d} ^ {2} (k) = lambda sigma _ {d} ^ {2} (k-1) + d ^ {2} (k) , !} E ¯ b ( k , 0 ) = E ¯ F ( k , 0 ) = X ( k ) σ X ( k ) { displaystyle { overline {e}} _ {b} (k, 0) = { overline {e}} _ {f} (k, 0) = { frac {x (k)} { sigma _ {x} (k)}} , !} E ¯ ( k , 0 ) = d ( k ) σ d ( k ) { displaystyle { overline {e}} (k, 0) = { frac {d (k)} { sigma _ {d} (k)}} , !} Pro i = 0,1, ..., N δ ¯ ( k , i ) = δ ( k − 1 , i ) ( 1 − E ¯ b 2 ( k − 1 , i ) ) ( 1 − E ¯ F 2 ( k , i ) ) + E ¯ b ( k − 1 , i ) E ¯ F ( k , i ) { displaystyle { overline { delta}} (k, i) = delta (k-1, i) { sqrt {(1 - { overline {e}} _ {b} ^ {2} (k -1, i)) (1 - { overline {e}} _ {f} ^ {2} (k, i))}} + { overline {e}} _ {b} (k-1, i ) { overline {e}} _ {f} (k, i)} E ¯ b ( k , i + 1 ) = E ¯ b ( k − 1 , i ) − δ ¯ ( k , i ) E ¯ F ( k , i ) ( 1 − δ ¯ 2 ( k , i ) ) ( 1 − E ¯ F 2 ( k , i ) ) { displaystyle { overline {e}} _ {b} (k, i + 1) = { frac {{ overline {e}} _ {b} (k-1, i) - { overline { delta}} (k, i) { overline {e}} _ {f} (k, i)} { sqrt {(1 - { overline { delta}} ^ {2} (k, i)) (1 - { overline {e}} _ {f} ^ {2} (k, i))}}}} E ¯ F ( k , i + 1 ) = E ¯ F ( k , i ) − δ ¯ ( k , i ) E ¯ b ( k − 1 , i ) ( 1 − δ ¯ 2 ( k , i ) ) ( 1 − E ¯ b 2 ( k − 1 , i ) ) { displaystyle { overline {e}} _ {f} (k, i + 1) = { frac {{ overline {e}} _ {f} (k, i) - { overline { delta} } (k, i) { overline {e}} _ {b} (k-1, i)} { sqrt {(1 - { overline { delta}} ^ {2} (k, i)) (1 - { overline {e}} _ {b} ^ {2} (k-1, i))}}}} Filtr zpětné vazby δ ¯ D ( k , i ) = δ ¯ D ( k − 1 , i ) ( 1 − E ¯ b 2 ( k , i ) ) ( 1 − E ¯ 2 ( k , i ) ) + E ¯ ( k , i ) E ¯ b ( k , i ) { displaystyle { overline { delta}} _ {D} (k, i) = { overline { delta}} _ {D} (k-1, i) { sqrt {(1 - { overline {e}} _ {b} ^ {2} (k, i)) (1 - { overline {e}} ^ {2} (k, i))}} + { overline {e}} (k , i) { overline {e}} _ {b} (k, i)} E ¯ ( k , i + 1 ) = 1 ( 1 − E ¯ b 2 ( k , i ) ) ( 1 − δ ¯ D 2 ( k , i ) ) [ E ¯ ( k , i ) − δ ¯ D ( k , i ) E ¯ b ( k , i ) ] { displaystyle { overline {e}} (k, i + 1) = { frac {1} { sqrt {(1 - { overline {e}} _ {b} ^ {2} (k, i )) (1 - { overline { delta}} _ {D} ^ {2} (k, i))}}} [{ overline {e}} (k, i) - { overline { delta }} _ {D} (k, i) { overline {e}} _ {b} (k, i)]} KonecKonec
Viz také Reference Hayes, Monson H. (1996). „9.4: Rekurzivní nejméně čtverců“. Statistické zpracování a modelování digitálního signálu . Wiley. p. 541. ISBN 0-471-59431-8 Simon Haykin, Teorie adaptivního filtru , Prentice Hall, 2002, ISBN 0-13-048434-2 M.H.A Davis, R.B. Vinter, Stochastické modelování a řízení Springer, 1985, ISBN 0-412-16200-8 Weifeng Liu, Jose Principe a Simon Haykin, Adaptivní filtrování jádra: komplexní úvod , John Wiley, 2010, ISBN 0-470-44753-2 R.L. Plackett, Některé věty na nejméně čtvercích , Biometrika, 1950, 37, 149-157, ISSN 0006-3444 CF Gauss, Theoria combinationis observumum erroribus minimis obnoxiae , 1821, Werke, 4. Gottinge Poznámky ^ Výroční C. Ifeacor, Barrie W. Jervis. Digitální zpracování signálu: praktický přístup, druhé vydání. Indianapolis: Pearson Education Limited, 2002, str. 718 ^ Steven Van Vaerenbergh, Ignacio Santamaría, Miguel Lázaro-Gredilla "Odhad faktoru zapomnění v rekurzivních nejmenších čtvercích jádra" , 2012 IEEE International Workshop on Machine Learning for Signal Processing, 2012, accessed 23. června 2016. ^ Welch, Greg a Bishop, Gary „Úvod do Kalmanova filtru“ , Department of Computer Science, University of North Carolina at Chapel Hill, 17. září 1997, accessed July 19, 2011. ^ Albu, Kadlec, Softley, Matoušek, Hermanek, Coleman, Fagan "Implementace (normalizované) RLS Lattice na Virtexu" , Digital Signal Processing, 2001, zpřístupněno 24. prosince 2011. 






![{ displaystyle mathbf {x} _ {n} = [x (n) quad x (n-1) quad ldots quad x (n-p)] ^ {T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09eb921b307dabe5f3f396085912215d09c02114)

















![sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni}} left [d (i) - sum _ {{l = 0}} ^ {{p}} w_ { {n}} (l) x (il) right] x (ik) = 0 qquad k = 0,1, cdots, p](https://wikimedia.org/api/rest_v1/media/math/render/svg/f227f57b5708e2279ff63386d33c501f76f500b7)
![sum _ {{l = 0}} ^ {{p}} w _ {{n}} (l) left [ sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni }} , x (il) x (ik) right] = sum _ {{i = 0}} ^ {{n}} lambda ^ {{ni}} d (i) x (ik) qquad k = 0,1, cdots, str](https://wikimedia.org/api/rest_v1/media/math/render/svg/43bb38e8f5f1fa0bb012d33ae44308679a9707c2)














![{ mathbf {x}} (i) = [x (i), x (i-1), dots, x (i-p)] ^ {{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dab2ea44a54d82de74ac9f6d26e3f5f6c2a44d8a)













![left [ lambda { mathbf {R}} _ {{x}} (n-1) + { mathbf {x}} (n) { mathbf {x}} ^ {{T}} (n) right] ^ {{- 1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f12c798517a6c530e616e5915429e3e16370785e)














![= lambda ^ {{- 1}} left [{ mathbf {P}} (n-1) - { mathbf {g}} (n) { mathbf {x}} ^ {{T}} ( n) { mathbf {P}} (n-1) vpravo] { mathbf {x}} (n)](https://wikimedia.org/api/rest_v1/media/math/render/svg/3baaff4ae27f9cfc51e54ada85a9de0999978262)



![= lambda left [ lambda ^ {{- 1}} { mathbf {P}} (n-1) - { mathbf {g}} (n) { mathbf {x}} ^ {{T} } (n) lambda ^ {{- 1}} { mathbf {P}} (n-1) right] { mathbf {r}} _ {{dx}} (n-1) + d (n ) { mathbf {g}} (n)](https://wikimedia.org/api/rest_v1/media/math/render/svg/d1dfdfb80807912183bd47c28d76f65ea9d4c553)

![= { mathbf {P}} (n-1) { mathbf {r}} _ {{dx}} (n-1) + { mathbf {g}} (n) left [d (n) - { mathbf {x}} ^ {{T}} (n) { mathbf {P}} (n-1) { mathbf {r}} _ {{dx}} (n-1) vpravo]](https://wikimedia.org/api/rest_v1/media/math/render/svg/9800c914543c33d7b8ebd7f295efc9fdc51b57e7)

![= { mathbf {w}} _ {{n-1}} + { mathbf {g}} (n) left [d (n) - { mathbf {x}} ^ {{T}} (n ) { mathbf {w}} _ {{n-1}} vpravo]](https://wikimedia.org/api/rest_v1/media/math/render/svg/78ebe76268d69116b2d676aab45f0272977a6df2)














![{ mathbf {x}} (n) = left [{ begin {matrix} x (n) x (n-1) vdots x (np) end {matrix}} right ]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85a8706d78172d40a299b2bb60ae26b22a21f6c)


















































![overline {e} (k, i + 1) = { frac {1} {{ sqrt {(1- overline {e} _ {b} ^ {2} (k, i)) (1- overline { delta} _ {D} ^ {2} (k, i))}}}} [ overline {e} (k, i) - overline { delta} _ {D} (k, i) overline {e} _ {b} (k, i)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/580293031a5a01b0b256042558d14b8ae206561d)