Čerpání lemmatu pro běžné jazyky - Pumping lemma for regular languages
V teorii formální jazyky, čerpání lemmatu pro běžné jazyky je lemma který popisuje základní vlastnost všech běžné jazyky. Neformálně se říká, že všechna dostatečně dlouhá slova v běžném jazyce mohou být čerpáno- to znamená nechat střední část slova libovolně často opakovat - a vytvořit tak nové slovo, které také leží ve stejném jazyce.
Konkrétně čerpací lemma říká, že pro každý běžný jazyk existuje konstanta takové, že každé slovo v alespoň s délkou lze rozdělit na tři podřetězce, , kde je střední část nesmí být prázdné, takže slova vytvořeno opakováním nula nebo vícekrát je stále v . Tento proces opakování se nazývá „čerpání“. Čerpací lemma navíc zaručuje, že délka bude nanejvýš , kterým se stanoví omezení způsobů, jakými mohou být rozděleny. Konečné jazyky vakuově uspokojit čerpací lemma tím, že rovná maximální délce řetězce v plus jedna.







Pumpovací lemma je užitečné pro vyvrácení pravidelnosti konkrétního dotyčného jazyka. Poprvé to prokázal Michael Rabin a Dana Scott v roce 1959,[1] a znovu objeven krátce poté Yehoshua Bar-Hillel, Micha A. Perles, a Eli Shamir v roce 1961, jako jejich zjednodušení čerpání lemmatu pro bezkontextové jazyky.[2][3]
Formální prohlášení
Nechat být běžným jazykem. Pak existuje celé číslo záleží jen na tak, že každý řetězec v alespoň délky ( se nazývá „čerpací délka“[4]) lze psát jako (tj., lze rozdělit na tři podřetězce), splňující následující podmínky:




je podřetězec, který lze čerpat (odebrat nebo opakovat libovolněkrát a výsledný řetězec je vždy v ). (1) znamená smyčku k čerpání musí mít délku alespoň jednu; (2) znamená, že k smyčce musí dojít během první postavy. musí být menší než (závěr bodů (1) a (2)), ale kromě toho neexistuje žádné omezení a .



Jednoduše řečeno, pro každý běžný jazyk , jakékoli dostatečně dlouhé slovo (v ) lze rozdělit na 3 části. tj. , tak, že všechny řetězce pro jsou také v .


Níže je formální vyjádření Pumping Lemma.

Použití lemmatu
Čerpací lemma se často používá k prokázání nepravidelnosti konkrétního jazyka: a důkaz rozporem (pravidelnosti jazyka) může sestávat z vystavení slova (požadované délky) v jazyce, kterému chybí vlastnost uvedená v čerpacím lemmatu.
Například jazyk přes abecedu lze ukázat jako nepravidelné následovně:


Nechat , a být používán v formální prohlášení pro čerpací lemma výše. Předpokládáme, že existuje nějaká konstanta . Nechat v být dán , což je řetězec delší než . U čerpacího lemmatu musí dojít k určitému rozkladu s a takhle v pro každého . Použitím , víme sestává pouze z instancí . Navíc, protože , obsahuje alespoň jednu instanci dopisu . Nyní pumpujeme nahoru: má více instancí dopisu než dopis , protože jsme přidali několik instancí bez přidání instancí . Proto, není v . Došli jsme k rozporu. Proto se předpokládá, že je pravidelný (tj. existuje takový ) musí být nesprávné. Proto není pravidelné.








Důkaz, že jazyk vyvážených (tj. správně vnořených) závorek není pravidelné, sleduje stejnou myšlenku. Dáno , existuje řetězec vyvážených závorek, který začíná více než levé závorky, takže bude sestávat výhradně z levé závorky. Opakováním , můžeme vytvořit řetězec, který neobsahuje stejný počet levé a pravé závorky, a proto je nelze vyvážit.
Důkaz čerpacího lemmatu


Pro každý běžný jazyk existuje a konečný stavový automat (FSA), který jazyk přijímá. Počet států v takovém FSA se počítá a tento počet se použije jako čerpací délka . Minimálně pro řetězec délky , nechť být počátečním stavem a nechat být posloupností dalšího státy navštívené jako řetězec je emitován. Protože FSA má jen státy, v této posloupnosti navštívené státy musí existovat alespoň jeden stát, který se opakuje. Psát si za takový stav. Přechody, které berou stroj z prvního setkání stavu k druhému státnímu střetnutí přiřadit nějaký řetězec. Tento řetězec se nazývá v lematu a protože stroj bude odpovídat řetězci bez porcí nebo s provázkem při libovolném počtu opakování jsou podmínky lemmatu splněny.




Například následující obrázek ukazuje FSA.
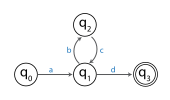
FSA přijímá řetězec: abeceda. Vzhledem k tomu, že tento řetězec má délku alespoň stejně velkou jako počet států, což jsou čtyři, znak princip pigeonhole označuje, že mezi počátečním stavem a dalšími čtyřmi navštívenými státy musí být alespoň jeden opakovaný stav. V tomto příkladu pouze je opakovaný stav. Od podřetězce před naším letopočtem provede stroj přechody, které začínají ve stavu a končí ve stavu , tato část mohla být opakována a FSA by to stále přijal, dal řetězec abcbcd. Případně před naším letopočtem část mohla být odstraněna a FSA by stále souhlasil s poskytnutím řetězce inzerát. Pokud jde o čerpací lemma, řetězec abeceda je rozbit na část A, a část před naším letopočtem a a část d.

Obecná verze čerpání lemmatu pro běžné jazyky
Pokud jazyk je normální, pak existuje číslo (čerpací délka) taková, že každý řetězec v s lze napsat ve formě



s provázky , a takhle , a
- je v pro každé celé číslo .[5]

Z toho je výše standardní verze následuje speciální případ, s oběma a je prázdný řetězec.


Jelikož obecná verze klade na jazyk přísnější požadavky, lze ji použít k prokázání nepravidelnosti mnoha dalších jazyků, například .[6]

Konverze lemmatu není pravdivá
Zatímco čerpací lemma uvádí, že všechny běžné jazyky splňují podmínky popsané výše, obrácení tohoto tvrzení není pravdivé: jazyk, který splňuje tyto podmínky, může být i nadále nepravidelný. Jinými slovy, jak původní, tak obecná verze čerpacího lemmatu dávají a nutné ale ne dostatečný stav aby byl jazyk pravidelný.
Zvažte například následující jazyk:
- .

Jinými slovy, obsahuje všechny řetězce nad abecedou s podřetězcem délky 3 včetně duplicitního znaku, stejně jako všechny řetězce nad touto abecedou, kde přesně 1/7 znaků řetězce jsou 3. Tento jazyk není běžný, ale stále jej lze „pumpovat“ . Předpokládejme nějaký řetězec s má délku alespoň 5. Poté, co má abeceda pouze čtyři znaky, musí být alespoň dva z prvních pěti znaků v řetězci duplikáty. Jsou odděleny nejvýše třemi znaky.


- Pokud jsou duplicitní znaky odděleny 0 znaky nebo 1, načerpejte jeden z dalších dvou znaků v řetězci, což neovlivní podřetězec obsahující duplikáty.
- Pokud jsou duplicitní znaky odděleny 2 nebo 3 znaky, oddělte je dvěma znaky. Při čerpání dolů nebo nahoru se vytvoří podřetězec o velikosti 3, který obsahuje 2 duplicitní znaky.
- Druhá podmínka zajišťuje to není pravidelné: Zvažte řetězec . Tento řetězec je v přesně kdy a tudíž není pravidelná Věta Myhill – Nerode.


The Věta Myhill – Nerode poskytuje test, který přesně charakterizuje běžné jazyky. Typickou metodou pro prokázání, že jazyk je pravidelný, je konstrukce buď a konečný stavový stroj nebo a regulární výraz pro jazyk.
Viz také
Poznámky
- ^ Rabin, Michael; Scott, Dana (Duben 1959). „Konečné automaty a jejich problémy s rozhodováním“ (PDF). IBM Journal of Research and Development. 3 (2): 114–125. doi:10.1147 / kolo 32.0114. Archivovány od originálu dne 14. prosince 2010.CS1 maint: unfit url (odkaz) Zde: Lemma 8, s. 119
- ^ Bar-Hillel, Y.; Perles, M .; Shamir, E. (1961), „O formálních vlastnostech jednoduchých frázových strukturních gramatik“, Zeitschrift für Phonetik, Sprachwissenschaft und Kommunikationsforschung, 14 (2): 143–172
- ^ John E. Hopcroft; Rajeev Motwani; Jeffrey D. Ullman (2003). Úvod do teorie automatů, jazyků a výpočtu. Addison Wesley. Tady: Oddíl 4.6, s. 166
- ^ Berstel, Jean; Lauve, Aaron; Reutenauer, Christophe; Saliola, Franco V. (2009). Kombinatorika slov. Christoffel slova a opakování slov. Série monografií CRM. 27. Providence, RI: Americká matematická společnost. str. 86. ISBN 978-0-8218-4480-9. Zbl 1161.68043.
- ^ Savitch, Walter (1982). Abstraktní stroje a gramatiky. str.49. ISBN 978-0-316-77161-0.
- ^ John E. Hopcroft a Jeffrey D. Ullman (1979). Úvod do teorie automatů, jazyků a výpočtu. Čtení / MA: Addison-Wesley. ISBN 978-0-201-02988-8. Zde: str. 72, Cvičení 3.2 (uvádějící o něco méně obecnou verzi, vyžadující |w|=str) a 3.3
Reference
- Lawson, Mark V. (2004). Konečné automaty. Chapman and Hall / CRC. ISBN 978-1-58488-255-8. Zbl 1086.68074.
- Sipser, Michael (1997). „1.4: Nepravidelné jazyky“. Úvod do teorie výpočtu. PWS Publishing. str.77–83. ISBN 978-0-534-94728-6. Zbl 1169.68300.
- Hopcroft, John E.; Ullman, Jeffrey D. (1979). Úvod do teorie automatů, jazyků a výpočtu. Reading, Massachusetts: Addison-Wesley Publishing. ISBN 978-0-201-02988-8. Zbl 0426.68001. (Viz kapitola 3.)
- Bakhadyr Khoussainov; Anil Nerode (6. prosince 2012). Teorie automatů a její aplikace. Springer Science & Business Media. ISBN 978-1-4612-0171-7.