Binární hromada - Binary heap - Wikipedia
| Binární (min.) Halda | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Typ | binární strom / halda | ||||||||||||||||||||||||
| Vynalezeno | 1964 | ||||||||||||||||||||||||
| Vynalezl | J. W. J. Williams | ||||||||||||||||||||||||
| Časová složitost v velká O notace | |||||||||||||||||||||||||
| |||||||||||||||||||||||||


A binární hromada je halda datová struktura který má podobu a binární strom. Binární hromady jsou běžným způsobem implementace prioritní fronty.[1]:162–163 Binární hromadu představil J. W. J. Williams v roce 1964 jako datová struktura pro heapsort.[2]
Binární halda je definována jako binární strom se dvěma dalšími omezeními:[3]
- Vlastnost Shape: binární halda je a kompletní binární strom; to znamená, že všechny úrovně stromu, s výjimkou poslední (nejhlubší), jsou plně vyplněny, a pokud není poslední úroveň stromu úplná, jsou uzly této úrovně vyplněny zleva doprava.
- Vlastnost haldy: klíč uložený v každém uzlu je podle některých buď větší nebo roven (≥) nebo menší nebo roven (≤) klíčům v podřízených uzlech celková objednávka.
Hromady, kde je nadřazený klíč větší nebo roven (≥) dětským klíčům, jsou volány maximální hromady; volají se ti, kde je menší nebo roven (≤) hromady min. Efektivní (logaritmický čas ) jsou známy algoritmy pro dvě operace potřebné k implementaci prioritní fronty na binární haldě: vložení prvku a odebrání nejmenšího nebo největšího prvku z min-haldy, respektive max-haldy. Binární hromady se také běžně používají v heapsort třídicí algoritmus, což je algoritmus na místě, protože binární hromady lze implementovat jako implicitní datová struktura, ukládání klíčů do pole a použití jejich relativních pozic v tomto poli k reprezentaci vztahů dítě-rodič.
Haldy operace
Operace vložení a odebrání nejprve upraví haldu tak, aby vyhovovala vlastnosti shape, přidáním nebo odebráním z konce haldy. Potom se vlastnost haldy obnoví procházením haldy nahoru nebo dolů. Obě operace trvají O (log n) čas.
Vložit
Chcete-li přidat prvek do haldy, můžeme provést tento algoritmus:
- Přidejte prvek do spodní úrovně haldy v otevřeném prostoru nejvíce vlevo.
- Porovnejte přidaný prvek s jeho nadřazeným prvkem; pokud jsou ve správném pořadí, přestaňte.
- Pokud ne, vyměňte prvek za nadřazený a vraťte se k předchozímu kroku.
Kroky 2 a 3, které obnoví vlastnost haldy porovnáním a případně zaměněním uzlu s jeho nadřazeným prvkem, se nazývají hromada provoz (také známý jako vybublat, perkoleje, prosít, dotek, vyplavat, heapify-upnebo kaskádovitě).
Počet požadovaných operací závisí pouze na počtu úrovní, které musí nový prvek zvýšit, aby vyhověl vlastnosti haldy. Operace vložení má tedy nejhorší časovou složitost O (log n). Pro náhodnou hromadu a pro opakované vložení má operace vložení průměrnou složitost O (1).[4][5]
Jako příklad vložení binární haldy řekněme, že máme haldu max
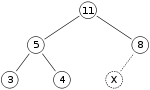
a chceme přidat haldu číslo 15. Nejprve umístíme 15 na pozici označenou X. Vlastnost haldy je však od té doby porušena 15 > 8, takže musíme vyměnit 15 a 8. Takže máme hromadu vypadající takto po první výměně:
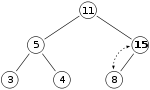
Vlastnost haldy je však od té doby stále porušována 15 > 11, takže musíme znovu vyměnit:
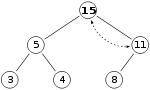
což je platná max. hromada. Po tomto posledním kroku není třeba kontrolovat levé dítě: na začátku byla platná max-heap, což znamená, že kořen byl již větší než jeho levé dítě, takže nahrazení kořene ještě větší hodnotou zachová vlastnost, kterou každý uzel je větší než jeho podřízené (11 > 5; -li 15 > 11, a 11 > 5, pak 15 > 5, kvůli tranzitivní vztah ).
Výpis
Postup pro odstranění kořene z haldy (efektivní extrakce maximálního prvku v haldě max nebo minimálního prvku v haldě) při zachování vlastnosti haldy je následující:
- Nahraďte kořen haldy posledním prvkem na poslední úrovni.
- Porovnejte nový kořen s jeho dětmi; pokud jsou ve správném pořadí, přestaňte.
- Pokud ne, vyměňte prvek za jednu z jeho podřízených položek a vraťte se k předchozímu kroku. (Zaměňte své menší dítě za hromadu min a větší dítě za hromadu max.)
Kroky 2 a 3, které obnovují vlastnost haldy porovnáním a případně zaměněním uzlu s jednou z jejích podřízených jednotek, se nazývají hromada (také známý jako bublina dolů, perkolátkové peří, prosít dolů, potopit, stékat, heapify-down, kaskádově dolů, extrakt-min nebo extrakt-maxnebo jednoduše heapify) úkon.
Takže pokud máme stejnou hromádku jako předtím

Odstraníme 11 a nahradíme ji 4.
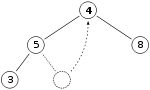
Vlastnost haldy je nyní porušena, protože 8 je větší než 4. V tomto případě je pro obnovení vlastnosti haldy dostačující výměna dvou prvků, 4 a 8, a nemusíme dále zaměňovat prvky:

Uzel pohybující se dolů je zaměněn za větší jejích dětí v max-haldě (v min-haldě by byla vyměněna za své menší dítě), dokud nesplní vlastnost haldy na své nové pozici. Této funkce je dosaženo pomocí Max-Heapify funkce, jak je definováno níže v pseudo kód pro pole -zálohovaná hromada A délky délka(A). Všimněte si, že A je indexován od 1.
// Provedení operace haldy dolů nebo heapify dolů pro maximální hromadu // A: pole představující haldu, indexované od 1 // i: index, od kterého se začíná při hromadění dolůMax-Heapify(A, i): vlevo, odjet ← 2×i že jo ← 2×i + 1 největší ← i -li vlevo, odjet ≤ délka(A) a A[vlevo, odjet]> A [největší] pak: největší ← vlevo, odjet
-li že jo ≤ délka(A) a A[že jo] > A[největší] pak: největší ← že jo -li největší ≠ i pak: vyměnit A[i] a A[největší] Max-Heapify(A, největší)
Pro výše uvedený algoritmus správně re-heapify pole, žádné uzly kromě uzlu v indexu i a jeho dvě přímé děti mohou porušit vlastnost haldy. Operaci down-heap (bez předchozího swapu) lze také použít k úpravě hodnoty kořene, i když prvek není odstraněn.
V nejhorším případě musí být nový kořen vyměněn za své dítě na každé úrovni, dokud nedosáhne spodní úrovně haldy, což znamená, že operace odstranění má časovou složitost vzhledem k výšce stromu, nebo O (log n).
Vložte a extrahujte
Vložení prvku a potom extrahování z haldy lze provést efektivněji než jednoduše volat funkce vložení a extrakce definované výše, což by zahrnovalo operaci upheap i downheap. Místo toho můžeme provést pouze downheap operaci, a to následovně:
- Porovnejte, zda je položka, kterou tlačíme, nebo vykukovaný vrchol hromady, větší (za předpokladu maximální hromady)
- Pokud je kořen haldy větší:
- Nahraďte kořen novou položkou
- Down-heapify počínaje kořenem
- Jinak vraťte položku, kterou tlačíme
Krajta poskytuje takovou funkci pro vložení a potom extrakci s názvem „heappushpop“, která je níže parafrázována.[6][7] Předpokládá se, že pole haldy má svůj první prvek v indexu 1.
// Zatlačte novou položku na haldu (max) a poté extrahujte kořen výsledné haldy. // halda: pole představující haldu, indexované na 1 // položka: element to insert // Vrátí větší ze dvou mezi položka a kořen halda.Push-Pop(halda: Seznam, položka: T) -> T: -li halda není prázdný a halda [1]> položka pak: // vyměnit halda[1] a položka _ dolů (halda počínaje indexem 1) vrátit se položka
Podobnou funkci lze definovat pro vyskakování a následné vkládání, které se v Pythonu nazývá „heapreplace“:
// Extrahujte kořen haldy a vložte novou položku // halda: pole představující haldu, indexované na 1 // položka: element k vložení // Vrátí aktuální kořen haldaNahradit(halda: Seznam, položka: T) -> T: vyměnit halda[1] a položka _ dolů (halda počínaje indexem 1) vrátit se položka
Vyhledávání
Nalezení libovolného prvku zabere O (n) čas.
Vymazat
Odstranění libovolného prvku lze provést následovně:
- Najděte index prvku, který chceme odstranit
- Zaměňte tento prvek za poslední prvek
- Down-heapify nebo up-heapify pro obnovení vlastnosti haldy. V max-heap (min-heap) je up-heapify vyžadován pouze v případě, že je nový klíč elementu je větší (menší) než předchozí, protože by mohla být porušena pouze vlastnost haldy nadřazeného prvku. Za předpokladu, že vlastnost haldy byla platná mezi prvkem a jeho děti před výměnou prvků, nemůže být porušeno nyní větší (menší) hodnotou klíče. Když je nový klíč menší (větší) než předchozí, je vyžadován pouze down-heapify, protože vlastnost haldy může být porušena pouze v podřízených prvcích.

Snižte nebo zvyšte klíč
Operace snížení klíče nahradí hodnotu uzlu danou hodnotou nižší hodnotou a operace zvýšení klíče provede totéž, ale s vyšší hodnotou. To zahrnuje vyhledání uzlu s danou hodnotou, změnu hodnoty a následné down-heapifying nebo up-heapifying k obnovení vlastnosti haldy.
Snížení klíče lze provést následujícím způsobem:
- Najděte index prvku, který chceme upravit
- Snižte hodnotu uzlu
- Down-heapify (za předpokladu maximální haldy) k obnovení vlastnosti haldy
Klíč pro zvýšení lze provést následujícím způsobem:
- Najděte index prvku, který chceme upravit
- Zvyšte hodnotu uzlu
- Up-heapify (za předpokladu maximální haldy) k obnovení vlastnosti haldy
Budování hromady
Budování hromady z řady n vstupní prvky lze provést spuštěním prázdné hromady a následným vložením každého prvku. Tento přístup, nazývaný Williamsovou metodou po vynálezci binárních hromad, je snadno viditelný Ó(n log n) čas: provádí n inzerce na Ó(log n) stojí každý.[A]
Williamsova metoda je však neoptimální. Rychlejší metoda (kvůli Floyd[8]) začíná libovolným umístěním prvků na binární strom, respektující vlastnost tvaru (strom může být reprezentován polem, viz níže). Pak počínaje od nejnižší úrovně a pohybující se nahoru, prosévejte kořen každého podstromu dolů jako v algoritmu odstraňování, dokud není obnovena vlastnost haldy. Přesněji, pokud všechny podstromy začínají v nějaké výšce již byly „heapified“ (nejnižší úroveň odpovídající ), stromy ve výšce mohou být heapified odesláním jejich root dolů podél cesty maximálně hodnotných dětí při budování max-haldy, nebo minimálně hodnotných dětí při budování min-haldy. Tento proces trvá operace (swapy) na uzel. U této metody probíhá většina heapifikace v nižších úrovních. Protože výška hromady je , počet uzlů ve výšce je . Náklady na heapifikaci všech podstromů jsou tedy:







To využívá skutečnost, že daný nekonečno série konverguje.

Je známo, že přesná hodnota výše uvedeného (nejhorší počet srovnání během výstavby haldy) se rovná:

kde s2(n) je součet všech číslic binární reprezentace z n a E2(n) je exponent 2 v primární faktorizaci n.
Průměrný případ je složitější analyzovat, ale lze prokázat asymptoticky 1.8814 n - 2 záznamy2n + Ó(1) srovnání.[10][11]
The Build-Max-Heap následující funkce převede pole A který ukládá kompletníbinární strom s n uzly na maximální hromadu opakovaným používáním Max-Heapify (down-heapify pro maximální haldu) způsobem zdola nahoru. prvky pole indexované podlepodlaha (n/2) + 1, podlaha(n/2) + 2, ..., njsou všechny listy stromu (za předpokladu, že indexy začínají na 1) - každý je tedy halda s jedním prvkem a není třeba ji heapifikovat dolů. Build-Max-Heap běžíMax-Heapify na každém ze zbývajících uzlů stromu.
Build-Max-Heap (A): pro každého index i z podlaha(délka(A)/2) dolů 1 dělat: Max-Heapify(A, i)
Haldy implementace
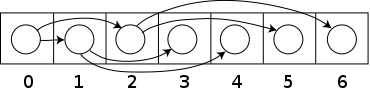

Hromady jsou běžně implementovány pomocí pole. Do pole lze uložit libovolný binární strom, ale protože binární halda je vždy úplný binární strom, lze jej uložit kompaktně. Není potřeba žádný prostor ukazatele; místo toho lze rodiče a děti každého uzlu najít aritmetikou na indexech pole. Díky těmto vlastnostem je tato implementace haldy jednoduchým příkladem implicitní datová struktura nebo Ahnentafel seznam. Podrobnosti závisí na kořenové pozici, což může záviset na omezeních a programovací jazyk použitý pro implementaci nebo preference programátora. Konkrétně je někdy kořen umístěn na indexu 1, aby se zjednodušila aritmetika.
Nechat n být počet prvků v haldě a i být libovolný platný index pole ukládající hromadu. Pokud je kořen stromu na indexu 0, s platnými indexy 0 až n - 1, pak každý prvek A na indexu i má
- děti v indexech 2i + 1 a 2i + 2
- jeho nadřazený v indexu podlaha ((i − 1) ∕ 2).
Alternativně, pokud je kořen stromu na indexu 1, s platnými indexy 1 až n, pak každý prvek A na indexu i má
- děti v indexech 2i a 2i +1
- jeho nadřazený v indexu podlaha (já ∕ 2).
Tato implementace se používá v heapsort algoritmus, kde umožňuje opětovné použití prostoru ve vstupním poli k uložení haldy (tj. algoritmus je hotový na místě ). Implementace je také užitečná pro použití jako Prioritní fronta kde použití a dynamické pole umožňuje vložení neomezeného počtu položek.
Operace upheap / downheap lze potom určit z hlediska pole takto: Předpokládejme, že vlastnost haldy obsahuje indexy b, b+1, ..., E. Funkce sift-down rozšiřuje vlastnost haldy na b−1, b, b+1, ..., EPouze index i = b−1 může porušit vlastnost haldy j být indexem největšího dítěte z A[i] (pro maximální hromadu nebo nejmenší dítě pro minimální hromadu) v rozsahu b, ..., E(Pokud takový index neexistuje, protože 2i > E pak vlastnost haldy platí pro nově rozšířený rozsah a není třeba nic dělat.) Výměnou hodnot A[i] a A[j] vlastnost haldy pro pozici i V tomto okamžiku je jediným problémem to, že vlastnost haldy nemusí obsahovat index jJe použita funkce sift-down ocas rekurzivně indexovat j dokud není pro všechny prvky vytvořena vlastnost haldy.
Funkce sift-down je rychlá. V každém kroku potřebuje pouze dvě srovnání a jeden swap. Hodnota indexu, kde pracuje, se v každé iteraci zdvojnásobuje, takže se nanejvýš přihlásí2 E jsou vyžadovány kroky.
Pro velké hromady a používání virtuální paměť, ukládání prvků do pole podle výše uvedeného schématu je neefektivní: (téměř) každá úroveň je v jiné strana. B-hromady jsou binární hromady, které udržují podstromy na jedné stránce, což snižuje počet stránek přístupných až desetkrát.[12]
Operace sloučení dvou binárních hromád trvá Θ (n) pro hromady stejné velikosti. To nejlepší, co můžete udělat, je (v případě implementace pole) jednoduše zřetězení dvou polí haldy a vytvoření hromady výsledku.[13] Hromadu n prvky lze sloučit s hromadou k prvky používající O (log n log k) srovnání klíčů, nebo v případě implementace založené na ukazateli, v O (log n log k) čas.[14] Algoritmus pro rozdělení hromady n prvky na dvě hromady k a n-k prvků, respektive na základě nového pohledu na hromady, protože byla představena uspořádaná sbírka podsvětí.[15] Algoritmus vyžaduje O (log n * log n) srovnání. Pohled také představuje nový a koncepčně jednoduchý algoritmus pro slučování hromad. Když je sloučení běžným úkolem, doporučuje se implementace jiné haldy, například binomické hromady, které lze sloučit v O (log n).
Navíc lze binární haldu implementovat s tradiční datovou strukturou binárního stromu, ale při přidávání prvku existuje problém s vyhledáním sousedního prvku na poslední úrovni na binární haldě. Tento prvek lze určit algoritmicky nebo přidáním dalších dat do uzlů, které se nazývají „navlékání“ stromu - namísto pouhého ukládání odkazů na děti ukládáme v pořádku nástupce uzlu.
Je možné upravit strukturu haldy tak, aby umožňovala extrakci jak nejmenšího, tak největšího prvku v čas.[16] Za tímto účelem se řádky střídají mezi haldy min a max. Haldy. Algoritmy jsou zhruba stejné, ale v každém kroku je třeba vzít v úvahu střídavé řádky se střídavými porovnáními. Výkon je zhruba stejný jako u běžné haldy s jedním směrem. Tuto myšlenku lze zobecnit na min-max-medián hromady.


Odvození indexových rovnic
V haldě založené na poli mohou být podřízené a nadřazené položky uzlu umístěny pomocí jednoduché aritmetiky na indexu uzlu. Tato část odvozuje příslušné rovnice pro hromady s jejich kořenem v indexu 0, s dalšími poznámkami o hromadách s jejich kořenem v indexu 1.
Abychom předešli nejasnostem, definujeme úroveň uzlu jako jeho vzdálenost od kořene, takže samotný kořen zaujímá úroveň 0.
Podřízené uzly
Pro obecný uzel umístěný v indexu (počínaje od 0) nejdříve odvodíme index jejího pravého potomka, .

Nechejte uzel být umístěn v úrovni , a nezapomeňte, že na jakékoli úrovni obsahuje přesně uzly. Kromě toho existují přesně uzly obsažené ve vrstvách až po vrstvu včetně (přemýšlejte o binární aritmetice; 0111 ... 111 = 1000 ... 000 - 1). Protože kořen je uložen na 0, tento uzel bude uložen v indexu . Spojením těchto pozorování se získá následující výraz pro index posledního uzlu ve vrstvě l.







Ať tam bude uzly za uzlem ve vrstvě L, takhle


Každý z těchto uzly musí mít přesně 2 děti, takže tam musí být oddělující uzly pravé dítě od konce jeho vrstvy ().



Podle potřeby.
Bereme na vědomí, že levé dítě kteréhokoli uzlu je vždy 1 místo před jeho pravým dítětem, dostaneme .

Pokud je kořen umístěn na indexu 1 místo 0, poslední uzel v každé úrovni je místo na indexu . Pomocí tohoto v celém výnosu a pro hromady s kořenem na 1.


Nadřazený uzel
Každý uzel je buď levým nebo pravým dítětem svého rodiče, takže víme, že platí některá z následujících možností.


Proto,

Nyní zvažte výraz .

Pokud uzel je levé dítě, to dává výsledek okamžitě, ale dává také správný výsledek, pokud je uzel je správné dítě. V tomto případě, musí být rovnoměrné, a proto musí být liché.



Proto bez ohledu na to, zda je uzel levým nebo pravým dítětem, lze jeho rodiče najít výrazem:

Související struktury
Vzhledem k tomu, že vlastnost haldy neurčuje pořadí sourozenců v haldě, lze dva potomky jednoho uzlu volně zaměňovat, pokud to neporuší vlastnost tvaru (porovnejte s šlapat ). Všimněte si však, že v běžné haldě založené na poli může jednoduše výměna podřízených také vyžadovat přesun uzlů podřízených podřízených pro zachování vlastnosti haldy.
Binární halda je speciální případ hromada d-ary ve kterém d = 2.
Shrnutí provozních časů
Tady jsou časové složitosti[17] různých haldy datových struktur. Názvy funkcí předpokládají minimální hromadu. Ve smyslu „Ó(F)" a "Θ(F) „viz Velká O notace.
| Úkon | najít-min | vymazat-min | vložit | zmenšovací klíč | splynout |
|---|---|---|---|---|---|
| Binární[17] | Θ(1) | Θ(logn) | Ó(logn) | Ó(logn) | Θ(n) |
| Levicový | Θ(1) | Θ(log n) | Θ(log n) | Ó(log n) | Θ(log n) |
| Binomický[17][18] | Θ(1) | Θ(log n) | Θ(1)[C] | Θ(log n) | Ó(logn)[d] |
| Fibonacci[17][19] | Θ(1) | Ó(logn)[C] | Θ(1) | Θ(1)[C] | Θ(1) |
| Párování[20] | Θ(1) | Ó(log n)[C] | Θ(1) | Ó(logn)[C][E] | Θ(1) |
| Brodal[23][F] | Θ(1) | Ó(logn) | Θ(1) | Θ(1) | Θ(1) |
| Hodnostní párování[25] | Θ(1) | Ó(log n)[C] | Θ(1) | Θ(1)[C] | Θ(1) |
| Přísný Fibonacci[26] | Θ(1) | Ó(log n) | Θ(1) | Θ(1) | Θ(1) |
| 2–3 hromada[27] | Ó(log n) | Ó(log n)[C] | Ó(log n)[C] | Θ(1) | ? |
- ^ Ve skutečnosti lze prokázat, že tento postup trvá Θ (n log n) čas v nejhorším případě, znamenající, že n log n je také asymptotická spodní hranice složitosti.[1]:167 V průměrný případ (průměrně přes všechny obměny z n metoda) však trvá lineárně.[8]
- ^ To neznamená, že třídění lze provést v lineárním čase, protože budování haldy je pouze prvním krokem heapsort algoritmus.
- ^ A b C d E F G h i Amortizovaný čas.
- ^ n je velikost větší hromady.
- ^ Dolní hranice [21] horní hranice [22]
- ^ Brodal a Okasaki později popisují a vytrvalý varianta se stejnými mezemi s výjimkou redukčního klíče, který není podporován n prvky mohou být konstruovány zdola nahoru Ó(n).[24]


Viz také
Reference
- ^ A b Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L.; Stein, Clifford (2009) [1990]. Úvod do algoritmů (3. vyd.). MIT Press a McGraw-Hill. ISBN 0-262-03384-4.
- ^ Williams, J. W. J. (1964), „Algorithm 232 - Heapsort“, Komunikace ACM, 7 (6): 347–348, doi:10.1145/512274.512284
- ^ eEL, CSA_Dept, IISc, Bangalore, „Binární hromady“, Datové struktury a algoritmyCS1 maint: používá parametr autoři (odkaz)
- ^ Porter, Thomas; Simon, Istvan (září 1975). Msgstr "Náhodné vložení do struktury prioritní fronty". Transakce IEEE v softwarovém inženýrství. SE-1 (3): 292–298. doi:10.1109 / TSE.1975.6312854. ISSN 1939-3520. S2CID 18907513.
- ^ Mehlhorn, Kurt; Tsakalidis, A. (únor 1989). "Datové struktury": 27.
Porter a Simon [171] analyzovali průměrné náklady na vložení náhodného prvku do náhodné hromady z hlediska výměn. Dokázali, že tento průměr je omezen konstantou 1,61. Jejich důkazní dokumenty se nezobecňují na sekvence vložení, protože náhodné vložení do náhodných hromad nevytváří náhodné hromady. Problém s opakovaným vkládáním vyřešili Bollobas a Simon [27]; ukazují, že očekávaný počet výměn je omezen 1,7645. Nejhorší cenu inzertů a deleteminů studovali Gonnet a Munro [84]; dávají log log n + O (1) a log n + log n * + O (1) hranice pro počet srovnání.
Citovat deník vyžaduje| deník =(Pomoc) - ^ „python / cpython / heapq.py“. GitHub. Citováno 2020-08-07.
- ^ "heapq - Algoritmus fronty haldy - dokumentace Pythonu 3.8.5". docs.python.org. Citováno 2020-08-07.
heapq.heappushpop (halda, položka): Zatlačte položku na haldu, poté vyskočte a vraťte nejmenší položku z haldy. Kombinovaná akce běží efektivněji než heappush () následovaná samostatným voláním heappop ().
- ^ A b Hayward, Ryan; McDiarmid, Colin (1991). "Průměrná případová analýza haldy opakovaným vkládáním" (PDF). J. Algoritmy. 12: 126–153. CiteSeerX 10.1.1.353.7888. doi:10.1016 / 0196-6774 (91) 90027-v. Archivovány od originál (PDF) dne 2016-02-05. Citováno 2016-01-28.
- ^ Suchenek, Marek A. (2012), „Základní a přesto přesná nejhorší analýza programu výstavby haldy Floyd“, Fundamenta Informaticae, 120 (1): 75–92, doi:10.3233 / FI-2012-751.
- ^ Doberkat, Ernst E. (květen 1984). „Průměrná případová analýza Floydova algoritmu pro konstrukci hromad“ (PDF). Informace a kontrola. 6 (2): 114–131. doi:10.1016 / S0019-9958 (84) 80053-4.
- ^ Pasanen, Tomi (listopad 1996). Základní průměrná případová analýza Floydova algoritmu pro konstrukci hromád (Technická zpráva). Turku Center for Computer Science. CiteSeerX 10.1.1.15.9526. ISBN 951-650-888-X. Technická zpráva TUCS č. 64. Všimněte si, že tento článek používá Floydovu původní terminologii „siftup“ pro to, co se nyní nazývá prosévání dolů.
- ^ Kamp, Poul-Henning (11. června 2010). "Děláš to špatně". Fronta ACM. Sv. 8 č. 6.
- ^ Chris L. Kuszmaul."binární halda" Archivováno 2008-08-08 na Wayback Machine.Dictary of Algorithms and Data Structures, Paul E. Black, ed., US National Institute of Standards and Technology. 16. listopadu 2009.
- ^ J.-R. Sack a T. Strothotte„Algoritmus pro slučování hromad“ Acta Informatica 22, 171-186 (1985).
- ^ Sack, Jörg-Rüdiger; Strothotte, Thomas (1990). "Charakterizace hromad a jejich aplikací". Informace a výpočet. 86: 69–86. doi:10.1016 / 0890-5401 (90) 90026-E.
- ^ Atkinson, M.D .; J.-R. Pytel; Santoro a T. Strothotte (1. října 1986). "Min-max hromady a zobecněné prioritní fronty" (PDF). Programovací techniky a datové struktury. Comm. ACM, 29 (10): 996–1000.
- ^ A b C d Cormen, Thomas H.; Leiserson, Charles E.; Rivest, Ronald L. (1990). Úvod do algoritmů (1. vyd.). MIT Press a McGraw-Hill. ISBN 0-262-03141-8.
- ^ "Binomická halda | Brilliant Math & Science Wiki". brilliant.org. Citováno 2019-09-30.
- ^ Fredman, Michael Lawrence; Tarjan, Robert E. (Červenec 1987). „Fibonacciho hromady a jejich použití ve vylepšených algoritmech optimalizace sítě“ (PDF). Časopis Asociace pro výpočetní techniku. 34 (3): 596–615. CiteSeerX 10.1.1.309.8927. doi:10.1145/28869.28874.
- ^ Iacono, Johne (2000), „Vylepšené horní hranice pro párování hromad“, Proc. 7. skandinávský seminář o teorii algoritmu (PDF), Přednášky v informatice, 1851, Springer-Verlag, str. 63–77, arXiv:1110.4428, CiteSeerX 10.1.1.748.7812, doi:10.1007 / 3-540-44985-X_5, ISBN 3-540-67690-2
- ^ Fredman, Michael Lawrence (Červenec 1999). „O efektivitě párování hromad a souvisejících datových struktur“ (PDF). Časopis Asociace pro výpočetní techniku. 46 (4): 473–501. doi:10.1145/320211.320214.
- ^ Pettie, Seth (2005). Směrem ke konečné analýze párování hromad (PDF). FOCS '05 Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science. 174–183. CiteSeerX 10.1.1.549.471. doi:10.1109 / SFCS.2005.75. ISBN 0-7695-2468-0.
- ^ Brodal, Gerth S. (1996), „Nejhorší efektivní fronty priorit“ (PDF), Proc. 7. ročník sympozia ACM-SIAM o diskrétních algoritmech, str. 52–58
- ^ Goodrich, Michael T.; Tamassia, Roberto (2004). „7.3.6. Konstrukce haldy zdola nahoru“. Datové struktury a algoritmy v Javě (3. vyd.). 338–341. ISBN 0-471-46983-1.
- ^ Haeupler, Bernhard; Sen, Siddhartha; Tarjan, Robert E. (Listopad 2011). „Hromadné párování“ (PDF). SIAM J. Computing. 40 (6): 1463–1485. doi:10.1137/100785351.
- ^ Brodal, Gerth Stølting; Lagogiannis, George; Tarjan, Robert E. (2012). Přísné hromady Fibonacci (PDF). Sborník 44. sympozia o teorii práce na počítači - STOC '12. str. 1177–1184. CiteSeerX 10.1.1.233.1740. doi:10.1145/2213977.2214082. ISBN 978-1-4503-1245-5.
- ^ Takaoka, Tadao (1999), Teorie 2–3 hromád (PDF), str. 12