Místní odlehlý faktor - Local outlier factor
| Část série na |
| Strojové učení a dolování dat |
|---|
Místa pro strojové učení |
Související články |
v detekce anomálií, místní odlehlý faktor (LOF) je algoritmus navržený Markusem M. Breunigem, Hans-Peter Kriegel, Raymond T. Ng a Jörg Sander v roce 2000 za nalezení anomálních datových bodů měřením lokální odchylky daného datového bodu vzhledem k jeho sousedům.[1]
LOF sdílí některé koncepty DBSCAN a OPTIKA například pojmy „vzdálenost jádra“ a „vzdálenost dosažitelnosti“, které se používají pro odhad místní hustoty.[2]
Základní myšlenka

Lokální odlehlý faktor je založen na konceptu místní hustoty, kde je lokalita dána k nejbližší sousedé, jejichž vzdálenost se používá k odhadu hustoty. Porovnáním místní hustoty objektu s místní hustotou jeho sousedů lze identifikovat oblasti podobné hustoty a body, které mají podstatně nižší hustotu než jejich sousedé. Ty jsou považovány za odlehlé hodnoty.
Místní hustota se odhaduje podle typické vzdálenosti, ve které lze bod „dosáhnout“ od jeho sousedů. Definice „vzdálenosti dosažitelnosti“ použitá v LOF je dalším opatřením k dosažení stabilnějších výsledků v klastrech. „Vzdálenost dosažitelnosti“ používaná LOF má některé jemné detaily, které jsou často považovány za nesprávné v sekundárních zdrojích, např. V učebnici Ethem Alpaydin.[3]
Formální
Nechat k-vzdálenost(A) být vzdálenost objektu A do k- nejbližší soused. Všimněte si, že sada k nejbližší sousedé zahrnuje všechny objekty v této vzdálenosti, což může být v případě „kravaty“ více než k předměty. Označujeme množinu k nejbližší sousedé jako Nk(A).

Tato vzdálenost se používá k definování toho, co se nazývá dosažitelná vzdálenost:
dosažitelnost-vzdálenostk(A,B) = max {k-vzdálenost(B), d (A,B)}
Řečeno slovy dosažitelná vzdálenost objektu A z B je skutečná vzdálenost dvou objektů, ale alespoň k-vzdálenost z B. Předměty, které patří do k nejbližší sousedé B ("jádro") Bviz Klastrová analýza DBSCAN ) jsou považovány za stejně vzdálené. Důvodem pro tuto vzdálenost je dostat se stabilnější výsledky[Citace je zapotřebí ]. Všimněte si, že to není vzdálenost v matematické definici, protože to není symetrické. (I když je to běžná chyba[4] vždy použít k-vzdálenost (A), čímž se získá mírně odlišná metoda, označovaná jako Simplified-LOF[4])
The místní hustota dosažitelnosti objektu A je definováno
lrdk(A): = 1/(∑B∈ Nk(A)dosažitelnost-vzdálenostk(A, B)/|Nk(A)|)
což je inverzní hodnota k průměrné dosažitelné vzdálenosti objektu A z jeho sousedy. Všimněte si, že to není průměrná dosažitelnost sousedů z A (což by podle definice bylo k-vzdálenost (A)), ale vzdálenost, ve které A lze „dosáhnout“ z jeho sousedy. U duplicitních bodů se tato hodnota může stát nekonečnou.
Místní hustoty dosažitelnosti jsou poté porovnány s hustotami sousedů
LOFk(A): =∑B∈ Nk(A)lrdk(B)/lrdk(A)/|Nk(A)|= ∑B∈ Nk(A)lrdk(B)/|Nk(A)| · Lrdk(A)
který je průměrná hustota místní dostupnosti sousedů děleno místní hustotou dosažitelnosti objektu. Hodnota přibližně 1 označuje, že objekt je srovnatelný se svými sousedy (a tedy ne odlehlý). Hodnota níže 1 označuje hustší oblast (což by byl inlier), zatímco hodnoty výrazně větší než 1 označte odlehlé hodnoty.
LOF (k) ~ 1 prostředek Podobná hustota jako sousedé,
LOF (k) <1 prostředek Vyšší hustota než sousedé (Inlier),
LOF (k)> 1 prostředek Nižší hustota než sousedé (Outlier)
Výhody
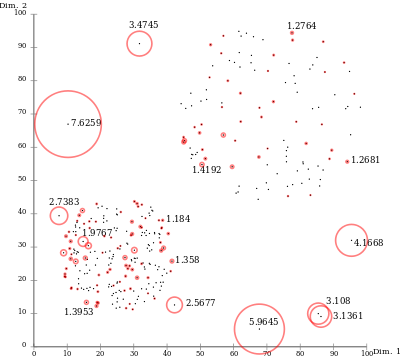
Vzhledem k místnímu přístupu je LOF schopen identifikovat odlehlé hodnoty v souboru dat, které by nebyly odlehlými hodnotami v jiné oblasti souboru dat. Například bod v „malé“ vzdálenosti od velmi hustého shluku je odlehlá hodnota, zatímco bod v řídkém shluku může vykazovat podobné vzdálenosti jako jeho sousedé.
Zatímco geometrická intuice LOF je použitelná pouze pro nízkodimenzionální vektorové prostory, algoritmus lze použít v jakémkoli kontextu a lze definovat funkci odlišnosti. Bylo experimentálně prokázáno, že funguje velmi dobře v mnoha nastaveních, často překonává konkurenty, například v detekce vniknutí do sítě[5] a na zpracovaných srovnávacích údajích klasifikace.[6]
Skupinu metod LOF lze snadno zobecnit a poté aplikovat na různé další problémy, jako je detekce odlehlých hodnot v geografických datech, video streamech nebo autorských sítích.[4]
Nevýhody a rozšíření
Výsledné hodnoty jsou kvocient - hodnoty a těžko interpretovatelné. Hodnota 1 nebo dokonce menší označuje jasný inlier, ale neexistuje jasné pravidlo, když je bod outlier. V jedné datové sadě může být hodnota 1,1 již odlehlá, v jiné datové sadě a parametrizaci (se silnými lokálními fluktuacemi) může být hodnota 2 inlierem. Tyto rozdíly se mohou také vyskytnout v rámci datové sady kvůli umístění metody. Existují rozšíření LOF, která se snaží zlepšit oproti LOF v těchto aspektech:
- Pytlování funkcí pro detekci odlehlých hodnot[7] provozuje LOF na více projekcích a kombinuje výsledky pro lepší detekční vlastnosti ve vysokých rozměrech. Toto je první souborové učení přístup k detekci odlehlých hodnot, další varianty viz ref.[8]
- Pravděpodobnost místního odlehlosti (Smyčka)[9] je metoda odvozená z LOF, ale s využitím levných místních statistik se stává méně citlivou na výběr parametru k. Kromě toho jsou výsledné hodnoty škálovány na rozsah hodnot [0:1].
- Interpretace a sjednocení odlehlých skóre[10] navrhuje normalizaci odlehlých skóre LOF na interval [0:1] zvýšení statistického měřítka použitelnost a je vidět vylepšenou verzi LoOP nápadů.
- O hodnocení odlehlých hodnocení a odlehlých skóre[11] navrhuje metody pro měření podobnosti a rozmanitosti metod pro budování pokročilé detekce odlehlých hodnot soubory pomocí variant LOF a dalších algoritmů a zdokonalením přístupu Featuring Bagging popsaného výše.
- Znovu zváženo zjišťování odlehlých míst: obecný pohled na lokalitu s aplikacemi pro zjišťování odlehlých míst, videa a sítí[4] popisuje obecný vzorec v různých metodách detekce odlehlých míst (včetně např. LOF, zjednodušené verze LOF a LoOP) a abstrakty z toho do obecného rámce. Tento rámec se poté použije například k detekci odlehlých hodnot v geografických datech, video streamech a autorských sítích.
Reference
- ^ Breunig, M. M .; Kriegel, H.-P.; Ng, R. T .; Sander, J. (2000). LOF: Identifikace místních odlehlých hodnot založených na hustotě (PDF). Sborník mezinárodní konference ACM SIGMOD o správě dat z roku 2000. SIGMOD. 93–104. doi:10.1145/335191.335388. ISBN 1-58113-217-4.
- ^ Breunig, M. M .; Kriegel, H.-P.; Ng, R. T .; Sander, J. R. (1999). „OPTICS-OF: Identifikace místních odlehlých hodnot“ (PDF). Zásady dolování dat a získávání znalostí. Přednášky z informatiky. 1704. p. 262. doi:10.1007/978-3-540-48247-5_28. ISBN 978-3-540-66490-1.
- ^ Alpaydin, Ethem (2020). Úvod do strojového učení (Čtvrté vydání). Cambridge, Massachusetts. ISBN 978-0-262-04379-3. OCLC 1108782604.
- ^ A b C d Schubert, E .; Zimek, A .; Kriegel, H. -P. (2012). "Znovu zváženo zjišťování odlehlých míst: Zobecněný pohled na lokalitu s aplikacemi pro zjišťování odlehlých míst, videa a sítí". Těžba dat a vyhledávání znalostí. 28: 190–237. doi:10.1007 / s10618-012-0300-z. S2CID 19036098.
- ^ Lazarevic, A .; Ozgur, A .; Ertoz, L .; Srivastava, J .; Kumar, V. (2003). „Srovnávací studie schémat detekce anomálií při detekci narušení sítě“ (PDF). Proc. 3. mezinárodní konference SIAM o dolování dat: 25–36. Archivovány od originál (PDF) dne 17.7.2013. Citováno 2010-05-14.CS1 maint: používá parametr autoři (odkaz)
- ^ Campos, Guilherme O .; Zimek, Arthur; Sander, Jörg; Campello, Ricardo J. G. B .; Micenková, Barbora; Schubert, Erich; Souhlas, Ira; Houle, Michael E. (2016). "O vyhodnocení odhalování odlehlých hodnot bez dohledu: opatření, datové soubory a empirická studie". Těžba dat a vyhledávání znalostí. 30 (4): 891–927. doi:10.1007 / s10618-015-0444-8. ISSN 1384-5810. S2CID 1952214.
- ^ Lazarevic, A .; Kumar, V. (2005). Msgstr "Pytlování funkcí pro detekci odlehlých hodnot". Proc. 11. mezinárodní konference ACM SIGKDD o získávání znalostí v dolování dat: 157–166. doi:10.1145/1081870.1081891. ISBN 159593135X. S2CID 2054204.
- ^ Zimek, A .; Campello, R. J. G. B .; Sander, J. R. (2014). Msgstr "Soubory pro nekontrolovanou detekci odlehlých hodnot". Informační bulletin průzkumů ACM SIGKDD. 15: 11–22. doi:10.1145/2594473.2594476. S2CID 8065347.
- ^ Kriegel, H.-P.; Kröger, P .; Schubert, E .; Zimek, A. (2009). LoOP: Pravděpodobnosti lokálních odlehlých hodnot (PDF). Sborník z 18. konference ACM o řízení informací a znalostí. CIKM '09. 1649–1652. doi:10.1145/1645953.1646195. ISBN 978-1-60558-512-3.
- ^ Kriegel, H. P.; Kröger, P .; Schubert, E .; Zimek, A. (2011). Interpretace a sjednocení odlehlých skóre. Sborník příspěvků z mezinárodní konference SIAM 2011 o dolování dat. s. 13–24. CiteSeerX 10.1.1.232.2719. doi:10.1137/1.9781611972818.2. ISBN 978-0-89871-992-5.
- ^ Schubert, E .; Wojdanowski, R .; Zimek, A .; Kriegel, H. P. (2012). O hodnocení odlehlých hodnocení a odlehlých skóre. Sborník mezinárodní konference SIAM z roku 2012 o dolování dat. 1047–1058. CiteSeerX 10.1.1.300.7205. doi:10.1137/1.9781611972825.90. ISBN 978-1-61197-232-0.