Webový prohledávač - Web crawler

A Webový prohledávač, někdy nazývané a pavouk nebo spiderbot a často zkráceno na prohledávač, je Internetový robot který systematicky prochází Celosvětová Síť, obvykle za účelem Webové indexování (web spidering).
Webové vyhledávače a některé další webové stránky k aktualizaci svého softwaru pro procházení nebo spiderování webu Webový obsah nebo indexy webového obsahu jiných stránek. Webové prohledávače kopírují stránky ke zpracování vyhledávačem, který indexy stažené stránky, aby uživatelé mohli vyhledávat efektivněji.
Prohledávače spotřebovávají zdroje v navštívených systémech a často navštěvují weby bez schválení. Problémy s plánem, načtením a „zdvořilostí“ vstupují do hry při přístupu k velkým sbírkám stránek. Existují mechanismy pro veřejné weby, které si nepřejí procházení, aby to agentovi procházení oznámil. Například včetně a robots.txt soubor může požádat roboti indexovat pouze části webu nebo vůbec nic.
Počet internetových stránek je extrémně vysoký; dokonce ani největší prohledávače nedosahují úplného indexu. Z tohoto důvodu se vyhledávače snažily poskytovat relevantní výsledky vyhledávání v prvních letech World Wide Web, před rokem 2000. Dnes jsou relevantní výsledky poskytovány téměř okamžitě.
Prohledávače mohou ověřovat hypertextové odkazy a HTML kód. Mohou být také použity pro škrábání webu (viz také programování založené na datech ).
Nomenklatura
Prohledávač webu je také známý jako pavouk,[1] an mravenec, an automatický indexátor,[2] nebo (v FOAF kontext softwaru) a Webový scutter.[3]
Přehled
Webový prohledávač začíná seznamem URL navštívit, zavolal semena. Když prohledávač tyto adresy URL navštíví, identifikuje všechny hypertextové odkazy na stránkách a přidá je do seznamu adres URL k návštěvě, který se nazývá procházet hranice. URL z hranice jsou rekurzivně navštívil podle souboru zásad. Pokud prohledávač provádí archivaci webové stránky (nebo archivace webu ), kopíruje a ukládá průběžné informace. Archivy jsou obvykle uloženy takovým způsobem, že je lze prohlížet, číst a procházet, jako tomu bylo na živém webu, ale jsou uchovány jako „snímky“.[4]
Archiv je znám jako úložiště a je navržen k ukládání a správě sbírky webové stránky. Úložiště pouze ukládá HTML stránky a tyto stránky jsou uloženy jako odlišné soubory. Repozitář je podobný jakémukoli jinému systému, který ukládá data, jako je moderní databáze. Jediný rozdíl je v tom, že úložiště nepotřebuje všechny funkce nabízené databázovým systémem. Úložiště ukládá nejnovější verzi webové stránky načtenou prohledávačem.[5]
Velký objem znamená, že prohledávač může stáhnout pouze omezený počet webových stránek v daném čase, takže musí upřednostnit stahování. Vysoká míra změn může znamenat, že stránky již mohly být aktualizovány nebo dokonce smazány.
Počet možných procházených adres URL generovaných softwarem na straně serveru také znemožnil webovým prohledávačům vyhnout se načítání duplicitní obsah. Nekonečné kombinace HTTP ZÍSKAT Existují parametry (založené na URL), z nichž pouze malý výběr ve skutečnosti vrátí jedinečný obsah. Například jednoduchá online fotogalerie může uživatelům nabídnout tři možnosti, jak je uvedeno v HTTP ZÍSKEJTE parametry v adrese URL. Pokud existují čtyři způsoby třídění obrázků, tři možnosti miniatura velikost, dva formáty souborů a možnost zakázat obsah poskytovaný uživateli, pak ke stejné sadě obsahu lze přistupovat pomocí 48 různých adres URL, z nichž všechny mohou být na webu propojeny. Tento matematická kombinace vytváří problém pro prohledávače, protože pro získání jedinečného obsahu musí třídit nekonečné kombinace relativně malých skriptovaných změn.
Jako Edwards et al. poznamenal: „Vzhledem k tomu, že šířka pásma protože procházení není nekonečné ani bezplatné, stává se nezbytným procházet web nejen škálovatelným, ale účinným způsobem, pokud má být zachována přiměřená míra kvality nebo aktuálnosti. “[6] Prohledávač si musí v každém kroku pečlivě vybrat, které stránky má dále navštívit.
Zásady procházení
Chování webového prolézacího modulu je výsledkem kombinace zásad:[7]
- A politika výběru který uvádí stránky ke stažení,
- A zásady opětovné návštěvy který uvádí, kdy zkontrolovat změny na stránkách,
- A politika zdvořilosti který uvádí, jak se vyhnout přetížení Webové stránky.
- A politika paralelizace který uvádí, jak koordinovat distribuované webové prohledávače.
Zásady výběru
Vzhledem k aktuální velikosti webu pokrývají i velké vyhledávače pouze část veřejně dostupné části. Studie z roku 2009 ukázala dokonce rozsáhlou vyhledávače indexovat ne více než 40-70% indexovatelného webu;[8] předchozí studie od Steve Lawrence a Lee Giles ukázal, že ne indexován vyhledávač více než 16% webu v roce 1999.[9] Protože prohledávač stáhne vždy jen zlomek webové stránky, je velmi žádoucí, aby stažená část obsahovala nejrelevantnější stránky a ne jen náhodný vzorek webu.
To vyžaduje metriku důležitosti pro stanovení priorit webových stránek. Důležitost stránky je její funkcí vnitřní kvalita, její popularita, pokud jde o odkazy nebo návštěvy, a dokonce i její URL (to je případ vertikální vyhledávače omezeno na jednoho doména nejvyšší úrovně nebo vyhledávače omezené na pevný web). Návrh zásady dobrého výběru má další potíže: musí pracovat s částečnými informacemi, protože během procházení není známa celá sada webových stránek.
Junghoo Cho et al. provedl první studii o zásadách pro procházení plánování. Jejich datová sada byla 180 000 stránek procházených z stanford.edu doména, ve které byla simulace procházení provedena s různými strategiemi.[10] Testované metriky objednávání byly nejdříve na šířku, zpětný odkaz počet a částečné PageRank výpočty. Jedním ze závěrů bylo, že pokud prohledávač chce stáhnout stránky s vysokým Pagerankem brzy během procesu procházení, pak je lepší částečná strategie Pagerank, následovaná prvním šířkou a počtem zpětných odkazů. Tyto výsledky jsou však pouze pro jednu doménu. Cho také napsal svou doktorskou disertační práci ve Stanfordu o procházení webu.[11]
Najork a Wiener provedly skutečné procházení na 328 milionech stránek pomocí objednávání na šířku.[12] Zjistili, že procházení na první šířku zachycuje stránky s vysokým Pagerankem na začátku procházení (ale tuto strategii neporovnávali s jinými strategiemi). Autoři tohoto výsledku vysvětlili, že „nejdůležitější stránky mají mnoho odkazů na ně od mnoha hostitelů a tyto odkazy budou nalezeny brzy, bez ohledu na to, na kterém hostiteli nebo stránce procházení pochází.“
Abiteboul navrhl strategii procházení založenou na algoritmus s názvem OPIC (výpočet důležitosti online stránky).[13] V OPICu je každé stránce dán počáteční součet „hotovosti“, který je rovnoměrně rozdělen mezi stránky, na které ukazuje. Je to podobné výpočtu PageRank, ale je rychlejší a provádí se pouze v jednom kroku. Prohledávač řízený OPIC nejprve stáhne stránky na hranici procházení s vyššími částkami „hotovosti“. Pokusy byly provedeny na 100 000stránkovém syntetickém grafu s distribucí in-odkazů podle zákona o moci. Ve skutečném webu však nebylo srovnání s jinými strategiemi ani experimenty.
Boldi et al. použila simulaci na podmnožinách webu 40 milionů stránek z .to doména a 100 milionů stránek z procházení WebBase, testování nejdříve proti hloubce, náhodné řazení a vševědoucí strategie. Porovnání bylo založeno na tom, jak dobře se PageRank vypočítaný při částečném procházení přibližuje skutečné hodnotě PageRank. Překvapivě některé návštěvy, které velmi rychle akumulují hodnocení PageRank (nejvíce pozoruhodně první a vševědoucí návštěva), poskytují velmi špatné progresivní aproximace.[14][15]
Baeza-Yates et al. použila simulaci na dvou podmnožinách webu o 3 milionech stránek z .GR a .cl domény, testování několika strategií procházení.[16] Ukázali, že jak strategie OPIC, tak strategie využívající délku front na jednotlivé stránky jsou lepší než nejdříve na šířku procházení a že je také velmi efektivní použít předchozí procházení, pokud je k dispozici, k vedení aktuálního.
Daneshpajouh et al. navrhl komunitní algoritmus pro objevování dobrých semen.[17] Jejich metoda prochází webové stránky s vysokým hodnocením PageRank z různých komunit v menší iteraci ve srovnání s procházením počínaje náhodnými semeny. Pomocí této nové metody lze extrahovat dobré semeno z dříve procházeného webového grafu. Pomocí těchto semen může být nové procházení velmi účinné.
Omezení sledovaných odkazů
Prohledávač může chtít vyhledávat pouze stránky HTML a vyhýbat se všem ostatním Typy MIME. Aby mohl prohledávač požadovat pouze prostředky HTML, může před požadavkem na celý prostředek s požadavkem GET vytvořit požadavek HTTP HEAD k určení typu MIME webového prostředku. Aby se prohledávač vyhnul četným požadavkům HEAD, může prozkoumat adresu URL a požádat o zdroj, pouze pokud adresa URL končí určitými znaky, jako jsou .html, .htm, .asp, .aspx, .php, .jsp, .jspx nebo lomítko . Tato strategie může způsobit neúmyslné přeskočení mnoha webových zdrojů HTML.
Některé prohledávače se také mohou vyhnout požadavku na jakékoli zdroje, které mají a "?" v nich (jsou vyráběny dynamicky), aby se zabránilo pavoučí pasti to může způsobit, že prohledávač stáhne z webu nekonečný počet adres URL. Tato strategie je nespolehlivá, pokud web používá Přepisování URL pro zjednodušení jeho URL.
Normalizace URL
Prohledávače obvykle provádějí nějaký typ Normalizace URL aby se zabránilo procházení stejného zdroje více než jednou. Termín Normalizace URL, také zvaný Kanonizace URL, odkazuje na proces úpravy a standardizace adresy URL konzistentním způsobem. Existuje několik typů normalizace, které lze provést, včetně převodu adres URL na malá písmena, odstranění znaku „.“ a „..“ segmenty a přidání koncových lomítek do neprázdné komponenty cesty.[18]
Cesta stoupající procházení
Některé prohledávače mají v úmyslu stáhnout / nahrát co nejvíce zdrojů z konkrétní webové stránky. Tak pásově vzestupný prohledávač byl představen, který by vystoupil na každou cestu v každé adrese URL, kterou hodlá procházet.[19] Pokud je například zadána počáteční adresa URL http://llama.org/hamster/monkey/page.html, pokusí se procházet / křeček / opice /, / křeček / a /. Cothey zjistil, že prolézací modul stoupající po cestě byl velmi efektivní při hledání izolovaných zdrojů nebo zdrojů, u nichž by při běžném procházení nebyl nalezen žádný příchozí odkaz.
Cílené procházení
Důležitost stránky pro prohledávač lze také vyjádřit jako funkci podobnosti stránky s daným dotazem. Volají se webové prohledávače, které se pokoušejí stáhnout stránky, které jsou si navzájem podobné zaměřený prohledávač nebo aktuální prohledávače. Pojmy aktuální a cílené procházení byly poprvé představeny Filippo Menczer[20][21] a Soumen Chakrabarti et al.[22]
Hlavním problémem při cíleném procházení je to, že v kontextu webového prohledávače bychom chtěli být schopni předpovědět podobnost textu dané stránky s dotazem před samotným stažením stránky. Možným prediktorem je text ukotvení odkazů; to byl přístup, který zvolil Pinkerton[23] v prvním webovém prohledávači raných dob webu. Diligenti et al.[24] navrhnout použití úplného obsahu již navštívených stránek k vyvození podobnosti mezi hnacím dotazem a stránkami, které ještě nebyly navštíveny. Výkon cíleného procházení závisí hlavně na bohatosti odkazů v konkrétním prohledávaném tématu a zaměřené procházení se obvykle spoléhá na obecný webový vyhledávací stroj, který poskytuje výchozí body.
Akademicky zaměřený prohledávač
Příklad zaměřené prohledávače jsou akademické prohledávače, které procházejí volně přístupné akademické související dokumenty, například citeseerxbot, což je prohledávač CiteSeerX vyhledávač. Jiné akademické vyhledávače jsou Google Scholar a Microsoft Academic Search atd. Protože většina akademických prací je publikována v PDF formáty, takový druh prohledávače se zvláště zajímá o procházení PDF, PostScript soubory, Microsoft Word včetně jejich na zip formáty. Z tohoto důvodu jsou běžné prohledávače s otevřeným zdrojovým kódem, například Heritrix, je nutné upravit tak, aby odfiltroval ostatní Typy MIME nebo middleware se používá k extrakci těchto dokumentů a jejich importu do zaměřené databáze procházení a úložiště.[25] Určit, zda jsou tyto dokumenty akademické nebo ne, je náročné a může procesu procházení přidat značné režijní náklady, takže se to provádí jako postup po procházení pomocí strojové učení nebo regulární výraz algoritmy. Tyto akademické dokumenty jsou obvykle získávány z domovských stránek fakult a studentů nebo z publikační stránky výzkumných ústavů. Protože akademické dokumenty zabírají na celých webových stránkách jen malou část, je pro zvýšení efektivity těchto webových prohledávačů důležitý dobrý výběr osiva.[26] Ostatní akademičtí prohledávači si mohou stáhnout prostý text a HTML soubory, které obsahují metadata akademických prací, jako jsou tituly, práce a abstrakty. Tím se zvyšuje celkový počet papírů, ale významná část nemusí poskytovat zdarma PDF stahování.
Sémanticky zaměřený prohledávač
Dalším typem zaměřených prohledávačů je sémanticky zaměřený prohledávač, který využívá doménové ontologie reprezentovat aktuální mapy a propojovat webové stránky s relevantními ontologickými koncepty pro účely výběru a kategorizace.[27] Kromě toho lze ontologie automaticky aktualizovat v procesu procházení. Dong a kol.[28] představil takový prolézací modul založený na ontologii a učení, který pomocí vektorového podpůrného stroje aktualizoval obsah ontologických konceptů při procházení webových stránek.
Zásady opakované návštěvy
Web má velmi dynamickou povahu a procházení zlomku webu může trvat týdny nebo měsíce. V době, kdy webový prohledávač dokončil procházení, mohlo dojít k mnoha událostem, včetně výtvorů, aktualizací a odstranění.
Z hlediska vyhledávače jsou náklady spojené s nedetekováním události, a tedy s neaktuální kopií prostředku. Nejpoužívanějšími nákladovými funkcemi jsou aktuálnost a věk.[29]
Svěžest: Toto je binární měřítko, které označuje, zda je místní kopie přesná nebo ne. Svěží stránka p v úložišti v čase t je definován jako:

Stáří: Toto je opatření, které označuje, jak zastaralá je místní kopie. Věk stránky p v úložišti, v čase t je definován jako:

Coffman et al. pracoval s definicí cíle webového prolézacího modulu, která je ekvivalentní s aktuálností, ale používají jiné znění: navrhují, aby prohledávač minimalizoval zlomek času, kdy stránky zůstávají zastaralé. Rovněž si všimli, že problém procházení webu lze modelovat jako systém dotazování s více frontami a jedním serverem, na kterém je webový prolézací server server a ve frontách jsou weby. Úpravy stránky jsou příchodem zákazníků a časy přepnutí představují interval mezi přístupy na stránku na jednom webu. Podle tohoto modelu je průměrná čekací doba pro zákazníka v systému dotazování ekvivalentní průměrnému věku webového prolézacího modulu.[30]
Cílem prohledávače je udržovat průměrnou aktuálnost stránek ve své kolekci na co nejvyšší úrovni nebo udržovat průměrný věk stránek na co nejnižší úrovni. Tyto cíle nejsou ekvivalentní: v prvním případě se prohledávač zajímá pouze o to, kolik stránek je zastaralých, zatímco v druhém případě se prohledávač zajímá o to, jak staré jsou místní kopie stránek.

Cho a Garcia-Molina studovali dvě jednoduché zásady opětovné návštěvy:[31]
- Jednotná zásada: Jedná se o opětovnou návštěvu všech stránek ve sbírce se stejnou frekvencí, bez ohledu na míru jejich změn.
- Zásada proporcionality: Jedná se o častější opakovanou návštěvu stránek, které se mění častěji. Frekvence návštěv je přímo úměrná (odhadované) frekvenci změn.
V obou případech lze opakované pořadí procházení stránek provést v náhodném nebo pevném pořadí.
Cho a Garcia-Molina prokázali překvapivý výsledek, že pokud jde o průměrnou svěžest, jednotná politika překonává proporcionální politiku jak v simulovaném webu, tak ve skutečném procházení webu. Důvodem je intuitivně to, že jelikož webové prohledávače mají omezený počet stránek, které mohou procházet v daném časovém rámci, (1) přidělí příliš mnoho nových procházení rychle se měnícím stránkám na úkor méně často se aktualizujících stránek a (2) svěžest rychle se měnících stránek trvá kratší dobu než méně často se měnící stránky. Jinými slovy, proporcionální politika přiděluje více zdrojů procházení často aktualizovaných stránek, ale z nich zažívá kratší celkovou dobu aktuálnosti.
Pro zlepšení svěžesti by měl prohledávač penalizovat prvky, které se příliš často mění.[32] Optimální politika opětovné návštěvy není jednotná ani přiměřená. Optimální metoda pro udržení vysoké průměrné čerstvosti zahrnuje ignorování stránek, které se příliš často mění, a optimální pro udržení nízkého průměrného věku je použití přístupových frekvencí, které se monotónně (a sublineárně) zvyšují s rychlostí změny každé stránky. V obou případech je optimální blíže k jednotné politice než k poměrné politice: jako Coffman et al. Všimněte si, že „aby se minimalizovala očekávaná doba zastarávání, měly by být přístupy ke konkrétní stránce udržovány v co nejrovnoměrnějším rozložení.“[30] Explicitní vzorce pro zásady opětovné návštěvy nejsou obecně dosažitelné, ale jsou získány číselně, protože závisí na distribuci změn stránky. Cho a Garcia-Molina ukazují, že exponenciální rozdělení je vhodné pro popis změn stránky,[32] zatímco Ipeirotis et al. ukázat, jak používat statistické nástroje k objevování parametrů, které ovlivňují toto rozdělení.[33] Všimněte si, že zde zvažované zásady opětovné návštěvy považují všechny stránky z hlediska kvality za homogenní („všechny stránky na webu mají stejnou hodnotu“), což není realistický scénář, takže další informace o kvalitě webových stránek by měly být zahrnuty k dosažení lepší zásady procházení.
Politika zdvořilosti
Prohledávače mohou načítat data mnohem rychleji a do větší hloubky než lidské vyhledávače, takže mohou mít ochromující dopad na výkon webu. Pokud jeden prolézací modul provádí více požadavků za sekundu nebo stahuje velké soubory, server může jen těžko držet krok s požadavky od více prohledávacích modulů.
Jak poznamenal Koster, použití webových prolézacích modulů je užitečné pro řadu úkolů, ale přichází s cenou pro obecnou komunitu.[34] Náklady na používání webových prolézacích modulů zahrnují:
- síťové zdroje, protože prohledávače vyžadují značnou šířku pásma a pracují s vysokou mírou paralelismu po dlouhou dobu;
- přetížení serveru, zejména pokud je frekvence přístupů na daný server příliš vysoká;
- špatně napsané prohledávače, které mohou selhat na serverech nebo směrovačích nebo které stránky se stahováním nemohou zpracovat; a
- osobní prohledávače, které, pokud jsou nasazeny příliš mnoha uživateli, mohou narušit sítě a webové servery.
Dílčím řešením těchto problémů je protokol o vyloučení robotů, známý také jako protokol robots.txt, což je standard, který správci označují, ke kterým částem jejich webových serverů by prohledávače neměly mít přístup.[35] Tato norma neobsahuje návrh na interval návštěv na stejném serveru, přestože je tento interval nejúčinnějším způsobem, jak se vyhnout přetížení serveru. Nedávno komerční vyhledávače jako Google, Zeptejte se Jeevese, MSN a Yahoo! Vyhledávání jsou schopni použít další parametr „Crawl-delay:“ v souboru robots.txt soubor, který udává počet sekund zpoždění mezi požadavky.
První navrhovaný interval mezi po sobě jdoucími načítáními stránek byl 60 sekund.[36] Pokud by se však stránky stahovaly v tomto tempu z webu s více než 100 000 stránkami přes perfektní spojení s nulovou latencí a nekonečnou šířkou pásma, trvalo by více než 2 měsíce, než by se stáhl pouze celý tento web; také by byl použit pouze zlomek prostředků z tohoto webového serveru. To se nezdá přijatelné.
Cho používá 10 sekund jako interval pro přístupy,[31] a prohledávač WIRE používá jako výchozí 15 sekund.[37] Prohledávač MercatorWeb se řídí zásadou adaptivní zdvořilosti: pokud to trvalo t sekund na stažení dokumentu z daného serveru, prohledávač čeká 10t sekund před stažením další stránky.[38] Kopr et al. použijte 1 sekundu.[39]
Pro ty, kteří používají webové prohledávače pro výzkumné účely, je nutná podrobnější analýza nákladů a přínosů a při rozhodování o tom, kam se procházet a jak rychle procházet, je třeba vzít v úvahu etické aspekty.[40]
Neoficiální důkazy z přístupových protokolů ukazují, že intervaly přístupu od známých prolézacích modulů se pohybují mezi 20 sekundami a 3–4 minutami. Stojí za povšimnutí, že i když jsou velmi zdvořilí a přijímají veškerá ochranná opatření, aby nedocházelo k přetížení webových serverů, dostávají se určité stížnosti od správců webových serverů. Brin a Strana Všimněte si, že: „... provozování prohledávače, který se připojuje k více než půl milionu serverů (...), generuje slušné množství e-mailů a telefonních hovorů. Z důvodu velkého počtu lidí, kteří přicházejí online, vždy existují ti, kteří nevědí, co je to prohledávač, protože toto je první, co viděli. “[41]
Zásada paralelizace
A paralelní crawler je prohledávač, který spouští více procesů paralelně. Cílem je maximalizovat rychlost stahování a zároveň minimalizovat režii z paralelizace a vyhnout se opakovanému stahování stejné stránky. Aby se zabránilo opakovanému stahování stejné stránky, vyžaduje systém procházení zásady pro přiřazování nových adres URL zjištěných během procesu procházení, protože stejnou adresu URL mohou najít dva různé procesy procházení.
Architektury
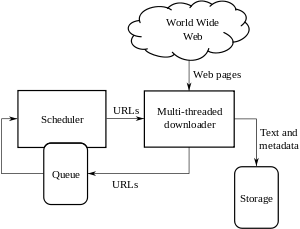
Prohledávač musí mít nejen dobrou strategii procházení, jak je uvedeno v předchozích částech, ale měl by mít také vysoce optimalizovanou architekturu.
Shkapenyuk a Suel poznamenali, že:[42]
I když je poměrně snadné vytvořit pomalý prohledávač, který na krátkou dobu stáhne několik stránek za sekundu, budování vysoce výkonného systému, který dokáže stahovat stovky milionů stránek během několika týdnů, představuje v návrhu systému řadu výzev, Účinnost I / O a sítě a robustnost a správa.
Webové prohledávače jsou ústřední součástí vyhledávačů a podrobnosti o jejich algoritmech a architektuře jsou uchovávány jako obchodní tajemství. Při publikování návrhů prohledávače často dochází k důležitému nedostatku podrobností, který ostatním brání v reprodukci díla. Objevují se také obavy z „spamování vyhledávače ", které brání velkým vyhledávačům ve zveřejnění jejich algoritmů hodnocení.
Bezpečnostní
Zatímco většina majitelů webových stránek se snaží o to, aby jejich stránky byly indexovány co nejširší, aby v nich bylo silné zastoupení vyhledávače, procházení webu může mít také nezamýšlené důsledky a vést k a kompromis nebo únik dat pokud vyhledávač indexuje zdroje, které by neměly být veřejně dostupné, nebo stránky odhalující potenciálně zranitelné verze softwaru.
Kromě standardu zabezpečení webových aplikací doporučení vlastníci webových stránek mohou snížit své vystavení příležitostným hackerům tím, že vyhledávacím strojům povolí indexovat pouze veřejné části svých webových stránek (pomocí robots.txt ) a výslovně jim blokuje indexování transakčních částí (přihlašovací stránky, soukromé stránky atd.).
Identifikace prohledávače
Webové prohledávače se obvykle identifikují na webovém serveru pomocí Uživatelský agent pole an HTTP žádost. Správci webových stránek obvykle zkoumají své Webové servery 'Přihlaste se a pomocí pole User Agent určete, které prohledávače webový server navštívily a jak často. Pole user agent může obsahovat a URL kde může správce webu zjistit více informací o prohledávači. Zkoumání protokolu webového serveru je zdlouhavý úkol, a proto někteří správci používají nástroje k identifikaci, sledování a ověřování webových prolézacích modulů. Spamboty a další škodlivé webové prohledávače pravděpodobně neumístí identifikační informace do pole uživatelského agenta, nebo mohou maskovat svou identitu jako prohlížeč nebo jiný známý prohledávač.
Je důležité, aby se prohledávače webu identifikovaly, aby mohli správci webových stránek v případě potřeby kontaktovat vlastníka. V některých případech mohou být prohledávače náhodně uvězněny v a pásová past nebo mohou přetížit webový server s požadavky a vlastník musí zastavit prohledávač. Identifikace je také užitečná pro správce, kteří mají zájem vědět, kdy mohou očekávat, že jejich webové stránky budou indexovány konkrétním vyhledávač.
Procházení hlubokého webu
Obrovské množství webových stránek leží v hluboký nebo neviditelný web.[43] Tyto stránky jsou obvykle přístupné pouze zadáním dotazů do databáze a běžné prohledávače tyto stránky nemohou najít, pokud na ně nejsou odkazy, které na ně odkazují. Google Soubory Sitemap protokol a mod oai[44] jsou určeny k umožnění objevování těchto hlubokých webových zdrojů.
Hluboké procházení webu také znásobuje počet procházených webových odkazů. Některé prohledávače přijímají pouze některé adresy URL <a href="URL"> formulář. V některých případech, například Googlebot „Procházení webu se provádí u veškerého textu obsaženého v hypertextovém obsahu, značkách nebo textu.
K cílení na hluboký webový obsah lze přijmout strategické přístupy. S technikou zvanou škrábání obrazovky, speciální software lze přizpůsobit tak, aby automaticky a opakovaně vyhledával daný webový formulář se záměrem agregovat výsledná data. Takový software lze použít k překlenutí více webových formulářů napříč několika webovými stránkami. Data extrahovaná z výsledků jednoho odeslání webového formuláře mohou být přijata a použita jako vstup do jiného webového formuláře, čímž je zajištěna kontinuita přes Deep Web způsobem, který u tradičních webových prohledávačů není možný.[45]
Stránky postaveny na AJAX patří mezi ty, které způsobují problémy webovým prohledávačům. Google navrhl formát volání AJAX, který jejich robot dokáže rozpoznat a indexovat.[46]
Předpětí webového prohledávače
Nedávná studie založená na rozsáhlé analýze souborů robots.txt ukázala, že určité webové prohledávače byly upřednostňovány před ostatními, přičemž nejvýhodnějším webovým prohledávačem byl Googlebot.[47]
Vizuální a programové prohledávače
Na webu je k dispozici řada produktů „vizuální webové škrabky / prohledávače“, které budou procházet stránky a strukturovat data do sloupců a řádků podle požadavků uživatelů. Jedním z hlavních rozdílů mezi klasickým a vizuálním prolézacím modulem je úroveň programovacích schopností potřebných k nastavení prolézacího modulu. Nejnovější generace „vizuálních škrabek“ odstraňuje většinu programátorských dovedností potřebných k tomu, aby bylo možné programovat a zahájit procházení za účelem škrábání webových dat.
Metoda vizuálního škrábání / procházení se spoléhá na to, že uživatel „naučí“ část technologie prohledávače, která poté sleduje vzory v polostrukturovaných zdrojích dat. Dominantní metodou pro výuku vizuálního prohledávače je zvýraznění dat v prohlížeči a školení sloupců a řádků. I když tato technologie není nová, byla to například základna Needlebase, kterou koupil Google (jako součást větší akvizice laboratoří ITA[48]), v této oblasti pokračují růst a investice ze strany investorů a koncových uživatelů.[49]
Příklady
tento článek může obsahovat nerozlišující, nadměrnýnebo irelevantní příklady. (Květen 2012) |
Následuje seznam publikovaných architektur prolézacích modulů pro prohledávače pro obecné účely (kromě zaměřených webových prolézacích modulů) se stručným popisem, který zahrnuje názvy jednotlivých komponent a vynikající funkce:
- Bingbot je název společnosti Microsoft Bing webový prohledávač. Nahradilo to Msnbot.
- Baiduspider je Baidu webový prohledávač.
- Googlebot je popsán podrobně, ale odkaz je pouze o rané verzi jeho architektury, která byla napsána v C ++ a Krajta. Prohledávač byl integrován do procesu indexování, protože syntaktická analýza textu byla prováděna pro fulltextové indexování a také pro extrakci URL. Existuje server URL, který odesílá seznamy adres URL, které mají být načteny několika procesy procházení. Během analýzy byly nalezené adresy URL předány serveru URL, který zkontroloval, zda byla adresa URL dříve viděna. Pokud ne, byla adresa URL přidána do fronty serveru URL.
- SortSite
- Swiftbot je Swiftype webový prohledávač.
- WebCrawler byl použit k vytvoření prvního veřejně dostupného fulltextového indexu podmnožiny webu. Bylo založeno na lib-WWW ke stahování stránek a dalším programu pro analýzu a objednávání adres URL pro první průzkum webového grafu. Rovněž zahrnoval prohledávač v reálném čase, který sledoval odkazy na základě podobnosti textu ukotvení s poskytnutým dotazem.
- Webová fontána je distribuovaný, modulární prohledávač podobný Mercatoru, ale napsaný v C ++.
- World Wide Web červ byl prohledávač používaný k vytvoření jednoduchého rejstříku názvů dokumentů a adres URL. Rejstřík lze prohledávat pomocí grep Unix příkaz.
- Xenon je webový prohledávač používaný vládními daňovými úřady k odhalování podvodů.[50][51]
- Yahoo! Slurp bylo jméno Yahoo! Hledejte v prohledávači, dokud Yahoo! smluvně s Microsoft použít Bingbot namísto.
Open-source prohledávače
- Frontera je implementace rámce pro procházení webu procházet hranice komponenta a poskytující primitiva pro škálovatelnost pro aplikace webového prolézacího modulu.
- GNU Wget je příkazový řádek - provozovaný prohledávač napsaný v C a propuštěn pod GPL. Obvykle se používá k zrcadlení webů a serverů FTP.
- GRUB je open source distribuovaný prohledávací prohledávač, který Hledání na Wikia slouží k procházení webu.
- Heritrix je Internetový archiv Prohledávač archivní kvality navržený pro archivaci pravidelných snímků velké části webu. Bylo to napsáno Jáva.
- ht: // Dig obsahuje ve svém indexovacím modulu webový prohledávač.
- HTTrack používá webový prohledávač k vytvoření zrcadla webové stránky pro offline prohlížení. Je napsán v C a propuštěn pod GPL.
- mnoGoSearch je prohledávač, indexátor a vyhledávač napsaný v jazyce C a licencovaný pod GPL (* Pouze stroje NIX)
- Sběratel HTTP Norconex je webový pavouk nebo prohledávač napsaný v Jáva, jehož cílem je usnadnit život integrátorům a vývojářům Enterprise Search (s licencí pod Licence Apache ).
- Apache Nutch je vysoce rozšiřitelný a škálovatelný webový prohledávač napsaný v Javě a vydaný pod Licence Apache. Je to založeno na Apache Hadoop a lze je použít s Apache Solr nebo Elasticsearch.
- Otevřete vyhledávací server je verze softwaru pro vyhledávače a webové prohledávače pod GPL.
- PHP-prohledávač je jednoduchý PHP a MySQL založený prohledávač vydaný pod Licence BSD.
- Škrábaný, rámec open source webcrawler, napsaný v pythonu (licencován pod BSD ).
- Hledá, bezplatný distribuovaný vyhledávač (s licencí pod AGPL ).
- StormCrawler, sbírka zdrojů pro vytváření škálovatelných webových prohledávačů s nízkou latencí Apache Storm (Licence Apache ).
- Robot tkWWW, prohledávač založený na tkWWW webový prohlížeč (s licencí pod GPL ).
- Xapian, vyhledávací modul prohledávače napsaný v jazyce C ++.
- YaCy, bezplatný distribuovaný vyhledávač založený na principech sítí peer-to-peer (licencováno pod GPL ).
- Trandoshan, bezplatný open source distribuovaný webový prohledávač určený pro deep-web.
Viz také
- Automatické indexování
- Gnutella crawler
- Archivace webu
- Webgraf
- Software pro zrcadlení webových stránek
- Škrábání vyhledávače
- Škrábání webu
Reference
- ^ Spetka, Scott. „Robot TkWWW: Beyond Browsing“. NCSA. Archivovány od originál dne 3. září 2004. Citováno 21. listopadu 2010.
- ^ Kobayashi, M. & Takeda, K. (2000). Msgstr "Načítání informací na webu". ACM Computing Surveys. 32 (2): 144–173. CiteSeerX 10.1.1.126.6094. doi:10.1145/358923.358934. S2CID 3710903.
- ^ Vidět definice scutteru na wiki projektu FOAF Project
- ^ Masanès, Julien (15. února 2007). Archivace webu. Springer. p. 1. ISBN 978-3-54046332-0. Citováno 24. dubna 2014.
- ^ Patil, Yugandhara; Patil, Sonal (2016). "Recenze webových prohledávačů se specifikací a fungováním" (PDF). International Journal of Advanced Research in Computer and Communication Engineering. 5 (1): 4.
- ^ Edwards, J., McCurley, K. S. a Tomlin, J. A. (2001). Msgstr "Adaptivní model pro optimalizaci výkonu přírůstkového webového prohledávače". Sborník z desáté mezinárodní konference o World Wide Web - WWW '01. Ve sborníku z desáté konference o World Wide Web. 106–113. CiteSeerX 10.1.1.1018.1506. doi:10.1145/371920.371960. ISBN 978-1581133486. S2CID 10316730.CS1 maint: více jmen: seznam autorů (odkaz)
- ^ Castillo, Carlos (2004). Efektivní procházení webu (Disertační práce). University of Chile. Citováno 3. srpna 2010.
- ^ A. Rackové; A. Signori (2005). „Indexovatelný web má více než 11,5 miliardy stránek“. Stopy a plakáty zvláštního zájmu ze 14. mezinárodní konference na webu. Stiskněte ACM. str. 902–903. doi:10.1145/1062745.1062789.
- ^ Steve Lawrence; C. Lee Giles (8. července 1999). "Přístup k informacím na webu". Příroda. 400 (6740): 107–9. Bibcode:1999 Natur.400..107L. doi:10.1038/21987. PMID 10428673. S2CID 4347646.
- ^ Cho, J .; Garcia-Molina, H .; Page, L. (duben 1998). „Efektivní procházení prostřednictvím objednávání adres URL“. Sedmá mezinárodní konference na webu. Brisbane, Austrálie. doi:10.1142/3725. ISBN 978-981-02-3400-3. Citováno 23. března 2009.
- ^ Cho, Junghoo, „Procházení webu: zjišťování a údržba rozsáhlých webových dat“, Disertační práce, Katedra výpočetní techniky, Stanford University, listopad 2001
- ^ Marc Najork a Janet L. Wiener. Procházení na šířku poskytuje stránky vysoké kvality. Ve sborníku z desáté konference o World Wide Web, strany 114–118, Hong Kong, květen 2001. Elsevier Science.
- ^ Serge Abiteboul; Mihai Preda; Gregory Cobena (2003). „Adaptivní online výpočet důležitosti stránky“. Sborník z 12. mezinárodní konference o World Wide Web. Budapest, Hungary: ACM. pp. 280–290. doi:10.1145/775152.775192. ISBN 1-58113-680-3. Citováno 22. března 2009.
- ^ Paolo Boldi; Bruno Codenotti; Massimo Santini; Sebastiano Vigna (2004). "UbiCrawler: a scalable fully distributed Web crawler" (PDF). Software: Praxe a zkušenosti. 34 (8): 711–726. CiteSeerX 10.1.1.2.5538. doi:10.1002/spe.587. Citováno 23. března 2009.
- ^ Paolo Boldi; Massimo Santini; Sebastiano Vigna (2004). "Do Your Worst to Make the Best: Paradoxical Effects in PageRank Incremental Computations" (PDF). Algorithms and Models for the Web-Graph. Přednášky z informatiky. 3243. pp. 168–180. doi:10.1007/978-3-540-30216-2_14. ISBN 978-3-540-23427-2. Citováno 23. března 2009.
- ^ Baeza-Yates, R., Castillo, C., Marin, M. and Rodriguez, A. (2005). Crawling a Country: Better Strategies than Breadth-First for Web Page Ordering. In Proceedings of the Industrial and Practical Experience track of the 14th conference on World Wide Web, pages 864–872, Chiba, Japan. ACM Press.
- ^ Shervin Daneshpajouh, Mojtaba Mohammadi Nasiri, Mohammad Ghodsi, A Fast Community Based Algorithm for Generating Crawler Seeds Set, In proceeding of 4th International Conference on Web Information Systems and Technologies (Webist -2008), Funchal, Portugal, May 2008.
- ^ Pant, Gautam; Srinivasan, Padmini; Menczer, Filippo (2004). "Crawling the Web" (PDF). In Levene, Mark; Poulovassilis, Alexandra (eds.). Web Dynamics: Adapting to Change in Content, Size, Topology and Use. Springer. pp. 153–178. ISBN 978-3-540-40676-1.
- ^ Cothey, Viv (2004). "Web-crawling reliability" (PDF). Journal of the American Society for Information Science and Technology. 55 (14): 1228–1238. CiteSeerX 10.1.1.117.185. doi:10.1002/asi.20078.
- ^ Menczer, F. (1997). ARACHNID: Adaptive Retrieval Agents Choosing Heuristic Neighborhoods for Information Discovery. In D. Fisher, ed., Machine Learning: Proceedings of the 14th International Conference (ICML97). Morgan Kaufmann
- ^ Menczer, F. and Belew, R.K. (1998). Adaptive Information Agents in Distributed Textual Environments. In K. Sycara and M. Wooldridge (eds.) Proc. 2nd Intl. Konf. on Autonomous Agents (Agents '98). ACM Press
- ^ Chakrabarti, Soumen; Van Den Berg, Martin; Dom, Byron (1999). "Focused crawling: A new approach to topic-specific Web resource discovery" (PDF). Počítačové sítě. 31 (11–16): 1623–1640. doi:10.1016/s1389-1286(99)00052-3. Archivovány od originál (PDF) dne 17. března 2004.
- ^ Pinkerton, B. (1994). Finding what people want: Experiences with the WebCrawler. In Proceedings of the First World Wide Web Conference, Geneva, Switzerland.
- ^ Diligenti, M., Coetzee, F., Lawrence, S., Giles, C. L., and Gori, M. (2000). Focused crawling using context graphs. In Proceedings of 26th International Conference on Very Large Databases (VLDB), pages 527-534, Cairo, Egypt.
- ^ Wu, Jian; Teregowda, Pradeep; Khabsa, Madian; Carman, Stephen; Jordan, Douglas; San Pedro Wandelmer, Jose; Lu, Xin; Mitra, Prasenjit; Giles, C. Lee (2012). "Web crawler middleware for search engine digital libraries". Proceedings of the twelfth international workshop on Web information and data management - WIDM '12. p. 57. doi:10.1145/2389936.2389949. ISBN 9781450317207. S2CID 18513666.
- ^ Wu, Jian; Teregowda, Pradeep; Ramírez, Juan Pablo Fernández; Mitra, Prasenjit; Zheng, Shuyi; Giles, C. Lee (2012). "The evolution of a crawling strategy for an academic document search engine". Proceedings of the 3rd Annual ACM Web Science Conference on - Web Sci '12. pp. 340–343. doi:10.1145/2380718.2380762. ISBN 9781450312288. S2CID 16718130.
- ^ Dong, Hai; Hussain, Farookh Khadeer; Chang, Elizabeth (2009). "State of the Art in Semantic Focused Crawlers". Computational Science and Its Applications – ICCSA 2009. Přednášky z informatiky. 5593. pp. 910–924. doi:10.1007/978-3-642-02457-3_74. hdl:20.500.11937/48288. ISBN 978-3-642-02456-6.
- ^ Dong, Hai; Hussain, Farookh Khadeer (2013). "SOF: A semi-supervised ontology-learning-based focused crawler". Concurrency and Computation: Practice and Experience. 25 (12): 1755–1770. doi:10.1002/cpe.2980. S2CID 205690364.
- ^ Junghoo Cho; Hector Garcia-Molina (2000). "Synchronizing a database to improve freshness" (PDF). Proceedings of the 2000 ACM SIGMOD international conference on Management of data. Dallas, Texas, United States: ACM. 117–128. doi:10.1145/342009.335391. ISBN 1-58113-217-4. Citováno 23. března 2009.
- ^ A b E. G. Coffman Jr; Zhen Liu; Richard R. Weber (1998). "Optimal robot scheduling for Web search engines". Journal of Scheduling. 1 (1): 15–29. CiteSeerX 10.1.1.36.6087. doi:10.1002/(SICI)1099-1425(199806)1:1<15::AID-JOS3>3.0.CO;2-K.
- ^ A b Cho, Junghoo; Garcia-Molina, Hector (2003). "Effective page refresh policies for Web crawlers". Transakce ACM v databázových systémech. 28 (4): 390–426. doi:10.1145/958942.958945. S2CID 147958.
- ^ A b Junghoo Cho; Hector Garcia-Molina (2003). "Estimating frequency of change". ACM Transactions on Internet Technology. 3 (3): 256–290. CiteSeerX 10.1.1.59.5877. doi:10.1145/857166.857170. S2CID 9362566.
- ^ Ipeirotis, P., Ntoulas, A., Cho, J., Gravano, L. (2005) Modeling and managing content changes in text databases. In Proceedings of the 21st IEEE International Conference on Data Engineering, pages 606-617, April 2005, Tokyo.
- ^ Koster, M. (1995). Robots in the web: threat or treat? ConneXions, 9(4).
- ^ Koster, M. (1996). A standard for robot exclusion.
- ^ Koster, M. (1993). Guidelines for robots writers.
- ^ Baeza-Yates, R. and Castillo, C. (2002). Balancing volume, quality and freshness in Web crawling. In Soft Computing Systems – Design, Management and Applications, pages 565–572, Santiago, Chile. IOS Press Amsterdam.
- ^ Heydon, Allan; Najork, Marc (26 June 1999). "Mercator: A Scalable, Extensible Web Crawler" (PDF). Archivovány od originál (PDF) dne 19. února 2006. Citováno 22. března 2009. Citovat deník vyžaduje
| deník =(Pomoc) - ^ Dill, S.; Kumar, R .; Mccurley, K. S.; Rajagopalan, S .; Sivakumar, D.; Tomkins, A. (2002). "Self-similarity in the web" (PDF). ACM Transactions on Internet Technology. 2 (3): 205–223. doi:10.1145/572326.572328. S2CID 6416041.
- ^ M. Thelwall; D. Stuart (2006). "Web crawling ethics revisited: Cost, privacy and denial of service". Journal of the American Society for Information Science and Technology. 57 (13): 1771–1779. doi:10.1002/asi.20388.
- ^ Brin, Sergey; Page, Lawrence (1998). "The anatomy of a large-scale hypertextual Web search engine". Computer Networks and ISDN Systems. 30 (1–7): 107–117. doi:10.1016/s0169-7552(98)00110-x.
- ^ Shkapenyuk, V. and Suel, T. (2002). Design and implementation of a high performance distributed web crawler. In Proceedings of the 18th International Conference on Data Engineering (ICDE), pages 357-368, San Jose, California. IEEE CS Press.
- ^ Shestakov, Denis (2008). Search Interfaces on the Web: Querying and Characterizing. TUCS Doctoral Dissertations 104, University of Turku
- ^ Michael L Nelson; Herbert Van de Sompel; Xiaoming Liu; Terry L Harrison; Nathan McFarland (24 March 2005). "mod_oai: An Apache Module for Metadata Harvesting": cs/0503069. arXiv:cs/0503069. Bibcode:2005cs........3069N. Citovat deník vyžaduje
| deník =(Pomoc) - ^ Shestakov, Denis; Bhowmick, Sourav S.; Lim, Ee-Peng (2005). "DEQUE: Querying the Deep Web" (PDF). Data & Knowledge Engineering. 52 (3): 273–311. doi:10.1016/s0169-023x(04)00107-7.
- ^ "AJAX crawling: Guide for webmasters and developers". Citováno 17. března 2013.
- ^ Sun, Yang (25 August 2008). "A COMPREHENSIVE STUDY OF THE REGULATION AND BEHAVIOR OF WEB CRAWLERS. The crawlers or web spiders are software robots that handle trace files and browse hundreds of billions of pages found on the Web. Usually, this is determined by tracking the keywords that make the searches of search engine users, a factor that varies second by second: according to Moz, only 30% of searches performed on search engines like Google, Bing or Yahoo! corresponds generic words and phrases. The remaining 70% are usually random". Citováno 11. srpna 2014. Citovat deník vyžaduje
| deník =(Pomoc) - ^ ITA Labs "ITA Labs Acquisition" 20 April 2011 1:28 AM
- ^ Crunchbase.com March 2014 "Crunch Base profile for import.io"
- ^ Norton, Quinn (25 January 2007). "Tax takers send in the spiders". Obchodní. Kabelové. Archivováno z původního dne 22. prosince 2016. Citováno 13. října 2017.
- ^ "Xenon web crawling initiative: privacy impact assessment (PIA) summary". Ottawa: Vláda Kanady. 11 April 2017. Archivováno z původního dne 25. září 2017. Citováno 13. října 2017.
Další čtení
- Cho, Junghoo, "Web Crawling Project", UCLA Computer Science Department.
- A History of Search Engines, z Wiley
- WIVET is a benchmarking project by OWASP, which aims to measure if a web crawler can identify all the hyperlinks in a target website.
- Shestakov, Denis, "Current Challenges in Web Crawling" a "Intelligent Web Crawling", slides for tutorials given at ICWE'13 and WI-IAT'13.