Vyhledávací algoritmus - Search algorithm
Tento článek má několik problémů. Prosím pomozte vylepši to nebo diskutovat o těchto otázkách na internetu diskusní stránka. (Zjistěte, jak a kdy tyto zprávy ze šablony odebrat) (Zjistěte, jak a kdy odstranit tuto zprávu šablony)
|
v počítačová věda, a vyhledávací algoritmus je jakýkoli algoritmus který řeší problém s hledáním, jmenovitě k získání informací uložených v nějaké datové struktuře nebo vypočítaných v hledat prostor problémové domény, buď s diskrétní nebo spojité hodnoty. Mezi konkrétní aplikace vyhledávacích algoritmů patří:
- Problémy v kombinatorická optimalizace, jako:
- The problém s směrováním vozidla, forma problém s nejkratší cestou
- The batoh problém: Vzhledem k sadě položek, z nichž každá má váhu a hodnotu, určete počet jednotlivých položek, které chcete zahrnout do kolekce, takže celková váha je menší nebo rovna danému limitu a celková hodnota je co největší.
- The problém s plánováním sestry
- Problémy v spokojenost s omezením, jako:
- The problém s vybarvováním mapy
- Vyplnění a sudoku nebo křížovka
- v herní teorie a hlavně kombinatorická teorie her, výběr nejlepšího tahu pro další (například u minmax algoritmus)
- Nalezení kombinace nebo hesla z celé sady možností
- Factoring celé číslo (důležitý problém v kryptografie )
- Optimalizace průmyslového procesu, jako je a chemická reakce změnou parametrů procesu (jako je teplota, tlak a pH)
- Načítání záznamu z a databáze
- Nalezení maximální nebo minimální hodnoty v a seznam nebo pole
- Kontrola, zda je daná hodnota přítomna v sadě hodnot
Klasické problémy s vyhledáváním popsané výše a webové vyhledávání jsou oba problémy v vyhledávání informací, ale jsou obecně studovány jako samostatná podpole a jsou řešeny a hodnoceny odlišně. Problémy s webovým vyhledáváním se obecně zaměřují na filtrování a hledání dokumentů, které jsou nejvíce relevantní pro lidské dotazy. Klasické vyhledávací algoritmy se obvykle vyhodnocují podle toho, jak rychle mohou najít řešení a zda je zaručeno, že toto řešení bude optimální. Ačkoli algoritmy pro načítání informací musí být rychlé, kvalita hodnocení je důležitější, stejně jako to, zda byly vynechány dobré výsledky a zahrnuty špatné výsledky.
Vhodný vyhledávací algoritmus často závisí na datové struktuře, která se prohledává, a může také zahrnovat předchozí znalosti o datech. Některé databázové struktury jsou speciálně konstruovány tak, aby byly vyhledávací algoritmy rychlejší nebo efektivnější, například a vyhledávací strom, hash mapa nebo index databáze. [1][2]
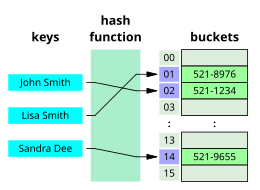
Vyhledávací algoritmy lze klasifikovat na základě jejich mechanismu vyhledávání. Lineární vyhledávání Algoritmy lineárně kontrolují každý záznam, který je spojen s cílovým klíčem.[3] Binární nebo poloviční intervalové vyhledávání, opakovaně zaměřte na střed struktury vyhledávání a rozdělte prostor pro vyhledávání na polovinu. Algoritmy srovnávacího vyhledávání se zlepšují při lineárním vyhledávání postupným odstraňováním záznamů na základě porovnání klíčů, dokud není nalezen cílový záznam, a lze je použít na datové struktury v definovaném pořadí.[4] Algoritmy digitálního vyhledávání fungují na základě vlastností číslic v datových strukturách, které používají numerické klávesy.[5] Konečně, hashování přímo mapuje klíče na záznamy na základě a hashovací funkce.[6] Hledání mimo lineární vyhledávání vyžaduje, aby byla data nějakým způsobem tříděna.
Algoritmy jsou často hodnoceny jejich výpočetní složitost nebo maximální teoretická doba běhu. Například binární vyhledávací funkce mají maximální složitost Ó(log n)nebo logaritmický čas. To znamená, že maximální počet operací potřebných k nalezení cíle vyhledávání je logaritmická funkce velikosti vyhledávacího prostoru.
Třídy
Pro virtuální vyhledávací prostory
Algoritmy pro prohledávání virtuálních prostor se používají v problém spokojenosti s omezením, kde cílem je najít soubor přiřazení hodnot určitým proměnným, které uspokojí konkrétní matematiku rovnice a nerovnice / rovnosti. Používají se také, když je cílem najít přiřazení proměnné, které bude maximalizovat nebo minimalizovat určitá funkce těchto proměnných. Algoritmy pro tyto problémy zahrnují základní vyhledávání hrubou silou (nazývané také „naivní“ nebo „neinformované“ vyhledávání) a různé heuristika které se snaží využít dílčích znalostí o struktuře tohoto prostoru, jako je lineární relaxace, generování omezení a šíření omezení.
Důležitou podtřídou jsou místní vyhledávání metody, které zobrazují prvky vyhledávaného prostoru jako vrcholy grafu s hranami definovanými sadou heuristik použitelných pro daný případ; a skenujte prostor pohybem od položky k položce podél okrajů, například podle nejstrmější sestup nebo nejlepší první kritérium, nebo v a stochastické vyhledávání. Tato kategorie zahrnuje širokou škálu obecných metaheuristické metody, jako je simulované žíhání, tabu vyhledávání, A-týmy a genetické programování, které konkrétním způsobem kombinují libovolnou heuristiku.
Tato třída zahrnuje také různé algoritmy pro vyhledávání stromů, které zobrazují prvky jako vrcholy a strom a projít stromem v nějakém zvláštním pořadí. Mezi příklady těchto metod patří vyčerpávající metody, jako jsou hloubkové vyhledávání a vyhledávání na šířku, stejně jako různé heuristické hledat prořezávání stromu metody jako ustoupit a větev a svázaný. Na rozdíl od obecné metaheuristiky, která v nejlepším případě funguje pouze v pravděpodobnostním smyslu, je zaručeno, že mnoho z těchto metod vyhledávání stromů najde přesné nebo optimální řešení, pokud bude mít dostatek času. Tomu se říká "úplnost ".
Další důležitou podtřídou jsou algoritmy pro zkoumání herní strom her pro více hráčů, například šachy nebo vrhcáby, jehož uzly se skládají ze všech možných herních situací, které by mohly z aktuální situace vyplývat. Cílem těchto problémů je najít tah, který poskytuje největší šanci na výhru, s přihlédnutím ke všem možným tahům soupeře (soupeřů). Podobné problémy nastávají, když lidé nebo stroje musí dělat postupná rozhodnutí, jejichž výsledky nejsou zcela pod kontrolou člověka, například v robot vedení nebo v marketing, finanční nebo válečný strategické plánování. Tento druh problému - kombinatorické vyhledávání - byl rozsáhle studován v kontextu umělá inteligence. Příklady algoritmů pro tuto třídu jsou algoritmus minimax, prořezávání alfa – beta a Algoritmus * a jeho varianty.
Pro dílčí struktury dané struktury
Název „kombinatorické vyhledávání“ se obecně používá pro algoritmy, které hledají konkrétní podstrukturu daného diskrétní struktura, například graf, a tětiva konečný skupina, a tak dále. Termín kombinatorická optimalizace se obvykle používá, když je cílem najít substrukturu s maximální (nebo minimální) hodnotou některého parametru. (Vzhledem k tomu, že podstruktura je v počítači obvykle představována množinou celočíselných proměnných s omezeními, lze na tyto problémy pohlížet jako na speciální případy uspokojení omezení nebo diskrétní optimalizace; jsou však obvykle formulovány a řešeny v abstraktnějším prostředí, kde interní reprezentace není výslovně uvedena.)
Důležitou a rozsáhle studovanou podtřídou jsou grafové algoritmy, zejména přechod grafu algoritmy pro vyhledání konkrétních dílčích struktur v daném grafu - například podgrafy, cesty, obvody atd. Mezi příklady patří Dijkstrův algoritmus, Kruskalův algoritmus, algoritmus nejbližšího souseda, a Primův algoritmus.
Další důležitou podtřídou této kategorie jsou algoritmy prohledávání řetězců, které hledají vzory v řetězcích. Dva slavné příklady jsou Boyer – Moore a Knuth – Morris – Prattovy algoritmy a několik algoritmů založených na příponový strom datová struktura.
Vyhledejte maximum funkce
V roce 1953 americký statistik Jack Kiefer vymyslel Fibonacciho vyhledávání který lze použít k nalezení maxima unimodální funkce a má mnoho dalších aplikací v počítačové vědě.
Pro kvantové počítače
Existují také metody vyhledávání určené pro kvantové počítače, jako Groverův algoritmus, které jsou teoreticky rychlejší než lineární vyhledávání nebo vyhledávání hrubou silou i bez pomoci datových struktur nebo heuristiky.
Viz také
- Zpětná indukce
- Paměť adresovatelná obsahu Hardware
- Dvoufázový vývoj - Proces, který řídí samoorganizaci v rámci komplexních adaptivních systémů
- Problém lineárního vyhledávání
- Žádný oběd zdarma při hledání a optimalizaci - Cena řešení, zprůměrovaná na všechny problémy ve třídě, je stejná pro jakoukoli metodu řešení
- Doporučující systém - Systém filtrování informací, který předpovídá preference uživatelů, také používá statistické metody k seřazení výsledků ve velmi velkých souborech dat
- Vyhledávač (výpočetní)
- Hledat hru
- Algoritmus výběru
- Řešitel
- Algoritmus řazení - Algoritmus, který uspořádává seznamy v pořadí nezbytném pro provádění určitých vyhledávacích algoritmů
- Webový vyhledávač
Kategorie:
- Kategorie: Vyhledávací algoritmy
Reference
Citace
- ^ Beame & Fich 2002, str. 39.
- ^ Knuth 1998, §6.5 („Načtení sekundárních klíčů“).
- ^ Knuth 1998, §6.1 („Sekvenční vyhledávání“).
- ^ Knuth 1998, §6.2 ("Hledání podle srovnání klíčů").
- ^ Knuth 1998, §6.3 (Digitální vyhledávání).
- ^ Knuth 1998, §6.4, (Hashing).
Bibliografie
Knihy
- Knuth, Donald (1998). Třídění a vyhledávání. Umění počítačového programování. 3 (2. vyd.). Reading, MA: Addison-Wesley Professional.CS1 maint: ref = harv (odkaz)
Články
- Schmittou, Thomas; Schmittou, Faith E. (01.08.2002). „Optimální hranice pro problém předchůdce a související problémy“. Journal of Computer and System Sciences. 65 (1): 38–72. doi:10.1006 / jcss.2002.1822.CS1 maint: ref = harv (odkaz)