Odběr vzorků řezu - Slice sampling
Odběr vzorků řezu je typ Markovský řetězec Monte Carlo algoritmus pro vzorkování pseudonáhodných čísel, tj. pro odebírání náhodných vzorků ze statistické distribuce. Metoda je založena na pozorování, že k odebrání vzorku a náhodná proměnná lze rovnoměrně vzorkovat z oblasti pod grafem funkce hustoty.[1][2][3]
Motivace
Předpokládejme, že chcete vybrat nějakou náhodnou proměnnou X s distribucí F(X). Předpokládejme, že následující je graf F(X). Výška F(X) odpovídá pravděpodobnosti v daném okamžiku.
Pokud byste měli rovnoměrně vzorkovat X, každá hodnota by měla stejnou pravděpodobnost vzorkování a vaše distribuce by měla formu F(X) = y pro některé y hodnota místo nějaké nejednotné funkce F(X). Namísto původní černé čáry by vaše nová distribuce vypadala spíše jako modrá čára.

Za účelem vzorkování X způsobem, který zachová distribuci F(X), je nutné použít některou techniku odběru vzorků, která zohledňuje různé pravděpodobnosti pro každý rozsah F(X).
Metoda
Odběr vzorků řezů ve své nejjednodušší formě odebírá vzorky rovnoměrně zpod křivky F(X), aniž byste museli odmítat jakékoli body, a to následovně:
- Vyberte počáteční hodnotu x0 pro který F(X0) > 0.
- Ukázka a y hodnota rovnoměrně mezi 0 a F(X0).
- Nakreslete vodorovnou čáru přes křivku y pozice.
- Ukázka bodu (X, y) z úseček v křivce.
- Opakujte postup od kroku 2 s novým X hodnota.
Motivací zde je, že jedním ze způsobů, jak vzorkovat bod rovnoměrně z libovolné křivky, je nejprve nakreslit tenké vodorovné řezy rovnoměrné výšky přes celou křivku. Poté můžeme vzorkovat bod v křivce náhodným výběrem řezu, který spadá na křivku nebo pod křivku v poloze x z předchozí iterace, a pak náhodně vybereme polohu x někde podél řezu. Použitím polohy x z předchozí iterace algoritmu z dlouhodobého hlediska vybereme řezy s pravděpodobnostmi úměrnými délkám jejich segmentů v křivce. Nejtěžší částí tohoto algoritmu je nalezení hran vodorovného řezu, což zahrnuje invertování funkce popisující distribuci, ze které se vzorkuje. To je obzvláště problematické pro multimodální distribuce, kde řez může sestávat z několika nespojitých částí. K překonání tohoto problému je často možné použít formu vzorkování odmítnutí, kdy vzorkujeme z většího řezu, o kterém je známo, že obsahuje dotyčný požadovaný řez, a poté zahodíme body mimo požadovaný řez. Tento algoritmus lze použít k vzorkování z oblasti pod žádný křivka, bez ohledu na to, zda se funkce integruje do 1. Ve skutečnosti škálování funkce konstantou nemá žádný vliv na vzorkované polohy x. To znamená, že algoritmus lze použít k vzorkování z distribuce, jejíž funkce hustoty pravděpodobnosti je známa pouze do konstanty (tj. jejíž normalizační konstanta není známo), což je běžné v výpočetní statistika.
Implementace
Vzorkování řezu dostane svůj název od prvního kroku: definování a plátek vzorkováním z pomocné proměnné . Tato proměnná je vzorkována z , kde je buď funkce hustoty pravděpodobnosti (PDF) ze dne X nebo je alespoň úměrný jeho PDF. To definuje plátek X kde . Jinými slovy, nyní se díváme na region X kde je hustota pravděpodobnosti alespoň . Pak další hodnota X je z tohoto řezu odebrán stejnoměrně. Nová hodnota je tedy odebrán vzorek X, a tak dále. To lze vizualizovat jako alternativní vzorkování polohy y a poté polohy x bodů v PDF, tedy Xjsou z požadované distribuce. The hodnoty nemají žádné zvláštní důsledky nebo interpretace mimo jejich užitečnost pro postup.

![[0, f (x)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/4aab098c7371ce16e69a2e14b79228f7dc47e547)


Pokud je k dispozici soubor PDF i jeho inverze a distribuce je unimodální, pak je nalezení řezu a vzorkování z něj jednoduché. Pokud tomu tak není, lze k nalezení oblasti, jejíž koncové body spadají mimo řez, použít postupný postup. Poté lze z řezu odebrat vzorek pomocí odmítnutí vzorkování. Různé postupy jsou popsány podrobně Nealem.[2]
Všimněte si, že na rozdíl od mnoha dostupných metod pro generování náhodných čísel z nejednotných distribucí budou náhodné variace generované přímo tímto přístupem vykazovat sériovou statistickou závislost. Je to proto, že k nakreslení dalšího vzorku definujeme řez na základě hodnoty F(X) pro aktuální vzorek.
Ve srovnání s jinými metodami
Slice sampling je metoda Markovova řetězce a jako taková slouží stejnému účelu jako Gibbsovo vzorkování a Metropolis. Na rozdíl od Metropolis není nutné ručně vyladit funkci kandidáta nebo standardní odchylku kandidáta.
Připomeňme, že Metropolis je citlivý na velikost kroku. Pokud je velikost kroku příliš malá náhodná procházka způsobuje pomalou dekorelaci. Pokud je velikost kroku příliš velká, je zde velká neúčinnost kvůli vysoké rychlosti odmítnutí.
Na rozdíl od Metropolisu vzorkování řezů automaticky upraví velikost kroku tak, aby odpovídala místnímu tvaru funkce hustoty. Implementace je prokazatelně jednodušší a efektivnější než vzorkování Gibbs nebo jednoduché aktualizace Metropolis.
Všimněte si, že na rozdíl od mnoha dostupných metod pro generování náhodných čísel z nejednotných distribucí budou náhodné variace generované přímo tímto přístupem vykazovat sériovou statistickou závislost. Jinými slovy, ne všechny body mají stejnou nezávislou pravděpodobnost výběru. Je to proto, že k nakreslení dalšího vzorku definujeme řez na základě hodnoty f (x) pro aktuální vzorek. Vygenerované vzorky však jsou markovian, a proto se od nich očekává dlouhodobá konvergence ke správné distribuci.
Slice Sampling vyžaduje, aby distribuce, která má být vzorkována, byla vyhodnotitelná. Jedním ze způsobů, jak tento požadavek uvolnit, je nahradit hodnotitelné rozdělení, které je úměrné skutečnému nevyčíslitelnému rozdělení.
Jednorozměrný případ
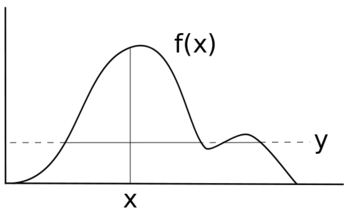
Chcete-li vybrat náhodnou proměnnou X s hustotou F(X) zavedeme pomocnou proměnnou Y a iterujte takto:
- Vzhledem k vzorku X vybíráme si y rovnoměrně náhodně z intervalu [0, F(X)];
- daný y vybíráme si X rovnoměrně náhodně ze sady .
- Ukázka X je získán ignorováním y hodnoty.

Naše pomocná proměnná Y představuje vodorovný „řez“ distribuce. Zbytek každé iterace je věnován vzorkování a X hodnota z řezu, která představuje hustotu uvažované oblasti.
V praxi je vzorkování z vodorovného řezu multimodální distribuce obtížné. Existuje napětí mezi získáním velké oblasti vzorkování a tím umožněním velkých pohybů v distribučním prostoru a získáním jednodušší oblasti vzorkování pro zvýšení účinnosti. Jednou z možností pro zjednodušení tohoto procesu je regionální expanze a kontrakce.
- Nejprve parametr šířky w se používá k definování oblasti obsahující dané 'x hodnota. Každý koncový bod této oblasti je testován, aby se zjistilo, zda leží mimo daný řez. Pokud ne, oblast se rozšíří v příslušných směrech o w až do konce oba koncové body leží mimo řez.
- Kandidátský vzorek je vybrán jednotně z této oblasti. Pokud kandidátský vzorek leží uvnitř řezu, je přijat jako nový vzorek. Pokud leží mimo řez, kandidátský bod se stane novou hranicí oblasti. Nový kandidátský vzorek je odebrán jednotně. Proces se opakuje, dokud kandidátský vzorek není v řezu. (Viz příklad pro vizuální příklad).




→
Vzorkování v rámci Gibbs
V Gibbsův vzorkovač, je třeba efektivně čerpat ze všech plně podmíněných distribucí. Když vzorkování z plně podmíněné hustoty není snadné, lze použít jedinou iteraci vzorkování řezu nebo algoritmus Metropolis-Hastings v rámci Gibbs ke vzorkování z dané proměnné. Pokud je hustota s úplnou podmíněností log-konkávní, efektivnější alternativou je použití adaptivní odmítnutí vzorkování (ARS) metody.[4][5] Pokud nelze použít techniky ARS (protože podmínka je plně logická, není logická), adaptivní odmítnutí algoritmů vzorkování Metropolis jsou často zaměstnáni.[6][7]
Vícerozměrné metody
Zacházení s každou proměnnou nezávisle
Vzorkování jednoho variabilního řezu lze použít v případě více proměnných opakovaným vzorkováním každé proměnné, jako v Gibbsově vzorkování. To vyžaduje, abychom mohli vypočítat pro každou komponentu funkce, která je úměrná .


Aby se zabránilo náhodnému chování při chůzi, lze k aktualizaci každé proměnné použít metody overrelaxation.[Citace je zapotřebí ] Overrelaxation zvolí novou hodnotu na opačné straně režimu od aktuální hodnoty, na rozdíl od výběru nové nezávislé hodnoty z distribuce, jak je to provedeno v Gibbsovi.
Vzorkování řezu hyperrektangle
Tato metoda přizpůsobuje jednorozměrný algoritmus vícerozměrnému případu nahrazením jednorozměrného hyperrektanglu w oblast použitá v originálu. Hyperrektangle H je inicializován na náhodnou pozici nad řezem. H je poté zmenšen, protože body z něj jsou odmítnuty.
Reflexní vzorkování řezu
Reflective slice sampling je technika k potlačení náhodného chování při chůzi, při které jsou následné kandidátní vzorky distribuce F(X) jsou udržovány v mezích řezu „odrážením“ směru vzorkování dovnitř směrem k řezu, jakmile dojde k zasažení hranice.
V tomto grafickém znázornění reflexního vzorkování tvar označuje hranice vzorkovacího řezu. Tečky označují počáteční a konečný bod vzorkovací chůze. Když vzorky narazí na hranice řezu, směr vzorkování se „odráží“ zpět do řezu.

Příklad
Zvažte jeden příklad proměnné. Předpokládejme, že naše skutečná distribuce je a normální distribuce se střední hodnotou 0 a směrodatnou odchylkou 3, . Tak:. Vrchol distribuce je zjevně na , na kterém místě .




- Nejprve nakreslíme jednotnou náhodnou hodnotu y z řady F(X), abychom mohli definovat naše řezy. F(X) se pohybuje od 0 do ~ 0,1330, takže stačí jakákoli hodnota mezi těmito dvěma extrémy. Předpokládejme, že to vezmeme y = 0,1. Problémem se stává způsob vzorkování bodů, které mají hodnoty y > 0.1.
- Dále nastavíme náš parametr šířky w které použijeme k rozšíření naší oblasti pozornosti. Tato hodnota je libovolná. Předpokládat w = 2.
- Dále potřebujeme počáteční hodnotu pro X. Kreslíme X z jednotné distribuce v doméně F(X) který splňuje F(X)> 0,1 (naše y parametr). Předpokládat X = 2. To funguje, protože F(2) = ~0.1065 > 0.1.[8]
- Protože X = 2 a w = 2, naše aktuální oblast zájmu je ohraničena (1, 3).
- Nyní je každý koncový bod této oblasti testován, aby se zjistilo, zda leží mimo daný řez. Naše pravá vazba leží mimo náš plátek (F(3) = ~ 0,0807 <0,1), ale levá hodnota není (F(1) = ~ 0,1258> 0,1). Levou vazbu rozšíříme přidáním w k ní, dokud nepřesáhne limit řezu. Po tomto procesu jsou nové hranice našeho zájmového regionu (−3, 3).
- Dále vezmeme jednotný vzorek uvnitř (−3, 3). Předpokládejme, že tento vzorek poskytuje x = -2,9. Ačkoli je tento vzorek v naší zájmové oblasti, neleží v našem řezu (f (2,9) = ~ 0,08334 <0,1), takže do tohoto bodu upravíme levou vazbu naší zájmové oblasti. Nyní vezmeme jednotný vzorek z (−2,9, 3). Předpokládejme, že tentokrát náš výtěžek získá x = 1, což je v našem řezu, a tím je přijatý výstup vzorku vzorkováním řezu. Měl náš nový X nebyl v našem řezu, pokračovali bychom v procesu zmenšování / převzorkování, dokud nebude platný X v mezích je nalezen.
Pokud nás zajímá vrchol distribuce, můžeme tento proces stále opakovat, protože nový bod odpovídá vyšší F(X) než původní bod.
Další příklad
Chcete-li ochutnat z normální distribuce nejdříve vybereme počáteční X—Řekněte 0. Po každém vzorku X vybíráme si y rovnoměrně náhodně od , který je ohraničen pdf z . Po každém y vzorek, který jsme vybrali X rovnoměrně náhodně od kde . Toto je plátek, kde .

![(0, e ^ {{- x ^ {2} / 2}} / {sqrt {2pi}}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/781bcb189d0d28e28cbaa780f87e24924df23b51)
![[-alfa, alfa]](https://wikimedia.org/api/rest_v1/media/math/render/svg/d6aaee8f359da96b8f4b1c02a27cbdadf9adf313)


Implementace v Macsyma jazyk je:
plátek(X) := blok([y, alfa], y:náhodný(exp(-X^2 / 2.0) / čtv(2.0 * dfloat(%pi))), alfa:čtv(-2.0 * ln(y * čtv(2.0 * dfloat(%pi)))), X:signum(náhodný()) * náhodný(alfa));Viz také
Reference
- ^ Damlen, P., Wakefield, J., & Walker, S. (1999). Gibbsovo vzorkování pro Bayesovské nekonjugované a hierarchické modely pomocí pomocných proměnných. Journal of the Royal Statistical Society, Series B (Statistical Methodology), 61 (2), 331-344, Chicago
- ^ A b Neal, Radford M. (2003). „Slice Sampling“. Annals of Statistics. 31 (3): 705–767. doi:10.1214 / aos / 1056562461. PAN 1994729. Zbl 1051.65007.
- ^ Bishop, Christopher (2006). „11.4: Vzorkování řezů“. Rozpoznávání vzorů a strojové učení. Springer. ISBN 978-0387310732.
- ^ Gilks, W. R .; Wild, P. (01.01.1992). "Adaptivní odmítnutí vzorkování pro vzorkování Gibbs". Journal of the Royal Statistical Society. Series C (Applied Statistics). 41 (2): 337–348. doi:10.2307/2347565. JSTOR 2347565.
- ^ Hörmann, Wolfgang (01.06.1995). "Technika odmítnutí pro vzorkování z T-konkávních distribucí". ACM Trans. Matematika. Softw. 21 (2): 182–193. CiteSeerX 10.1.1.56.6055. doi:10.1145/203082.203089. ISSN 0098-3500.
- ^ Gilks, W. R .; Best, N. G.; Tan, K. K. C. (01.01.1995). "Adaptive Rejection Metropolis Sampling within Gibbs Sampling". Journal of the Royal Statistical Society. Series C (Applied Statistics). 44 (4): 455–472. doi:10.2307/2986138. JSTOR 2986138.
- ^ Meyer, Renate; Cai, Bo; Perron, François (2008-03-15). "Adaptivní odmítnutí vzorkování metropole pomocí Lagrangeových interpolačních polynomů stupně 2". Výpočetní statistika a analýza dat. 52 (7): 3408–3423. doi:10.1016 / j.csda.2008.01.005.
- ^ Všimněte si, že pokud jsme nevěděli, jak vybrat X takhle F(X) > y, stále můžeme vybrat libovolnou náhodnou hodnotu pro X, vyhodnotit F(X) a použijeme to jako naši hodnotu y. y pouze inicializuje algoritmus; jak algoritmus postupuje, najde vyšší a vyšší hodnoty y.