Segmentace objektů - Object co-segmentation

v počítačové vidění, segmentace objektů je zvláštní případ segmentace obrazu, který je definován jako společné segmentování sémanticky podobných objektů ve více obrazech nebo videozáznamech[2][3].
Výzvy
Často je náročné extrahovat segmentační masky cíle / objektu z hlučné sbírky obrazů nebo videozáznamů, která zahrnuje objevování objektů spolu s segmentace. A hlučná sbírka znamená, že objekt / cíl je sporadicky přítomen v sadě obrazů nebo objekt / cíl mizí přerušovaně v celém sledovaném videu. Rané metody[4][5] obvykle zahrnují reprezentace na střední úrovni, jako např návrhy objektů.
Metody založené na dynamických Markovových sítích

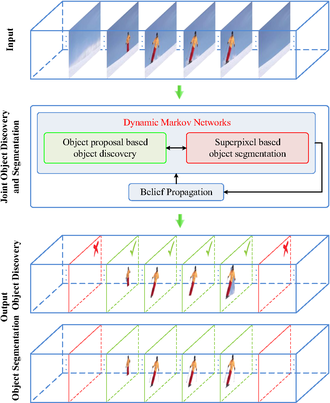
Metoda společného objevování a společné segmentace založená na vázané dynamice Markovovy sítě byl nedávno navržen[1], který požaduje významné zlepšení odolnosti proti irelevantním / hlučným video snímkům.
Na rozdíl od předchozích snah, které pohodlně předpokládají konzistentní přítomnost cílových objektů v celém vstupním videu, tento dvojitý dynamický algoritmus založený na Markovově síti současně provádí jak detekční, tak segmentační úkoly se dvěma příslušnými Markovovými sítěmi společně aktualizovanými prostřednictvím šíření víry.
Konkrétně je Markovova síť zodpovědná za segmentaci inicializována superpixely a poskytuje informace o svém Markovově protějšku odpovědném za úlohu detekce objektů. Naopak Markovova síť zodpovědná za detekci vytváří graf návrhu objektu se vstupy včetně prostoročasových segmentačních trubek.
Metody založené na grafovém řezu
Výřez grafu optimalizace je oblíbeným nástrojem v oblasti počítačového vidění, zejména v dřívějších dobách segmentace obrazu aplikace. Jako rozšíření pravidelných řezů grafů je navrženo víceúrovňové řezání hypergrafu[6] zohlednit složitější korespondence vyššího řádu mezi skupinami videí nad rámec typických párových korelací.
S takovým rozšířením hypergrafu lze do výpočtu hyperedge bez problémů začlenit více modalit korespondence, včetně vzhledu na nízké úrovni, výběžku, koherentního pohybu a prvků na vysoké úrovni, jako jsou oblasti objektů. Kromě toho jako hlavní výhoda oproti společný výskyt založený přístup, hypergraf implicitně zachovává složitější korespondenci mezi svými vrcholy, přičemž váhy hyperedge jsou pohodlně počítány rozklad vlastních čísel z Laplaciánské matice.
Metody založené na CNN / LSTM


v lokalizace akce aplikace, segmentace objektů je také implementován jako segmentová trubice časoprostorový detektor[7]. Inspirován nedávnými snahami o lokalizaci časoprostorových akcí s tubety (sekvence ohraničujících rámečků), Le et al. představuje nový časoprostorový akční lokalizační detektor Segment-tube, který se skládá ze sekvencí segmentačních masek po jednotlivých snímcích. Tento detektor segmentové trubice může dočasně určit počáteční / koncový rámec každé kategorie akcí v přítomnosti předcházejících / následných interferenčních akcí v neřízených videích. Současně detektor segmentových trubek produkuje segmentační masky na jednotlivé rámečky namísto ohraničujících rámečků, které nabízejí tubetům vynikající prostorovou přesnost. Toho je dosaženo střídáním iterativní optimalizace mezi lokalizací časové akce a segmentací prostorové akce.
Navrhovaný detektor segmentové trubice je znázorněn na vývojovém diagramu vpravo. Ukázkovým vstupem je neoříznuté video obsahující všechny snímky ve videu párového krasobruslení, přičemž pouze část těchto snímků patří do příslušné kategorie (např. DeathSpirals). Tato metoda byla inicializována segmentací obrazu na základě salience na jednotlivých rámcích a nejprve provede krok lokalizace časové akce s kaskádovým 3D CNN a LSTM, a určuje počáteční a koncový rámec cílové akce pomocí strategie hrubého k jemnému. Následně detektor segmentových trubek zpřesní prostorovou segmentaci na snímek pomocí řez grafu zaměřením na relevantní rámce identifikované krokem lokalizace časové akce. Optimalizace střídá iterativní způsob lokalizace časové akce a segmentace prostorové akce. Po praktické konvergenci jsou konečné výsledky prostoroprostorové lokalizace akce získány ve formátu posloupnosti segmentačních masek na jednotlivé snímky (spodní řada ve vývojovém diagramu) s přesnými počátečními / koncovými snímky.
Viz také
- Segmentace obrazu
- Detekce objektů
- Analýza obsahu videa
- Analýza obrazu
- Digitální zpracování obrazu
- Rozpoznávání aktivity
- Počítačové vidění
- Konvoluční neuronová síť
- Dlouhodobá krátkodobá paměť
Reference
- ^ A b C d Liu, Ziyi; Wang, Le; Hua, Gang; Zhang, Qilin; Niu, Zhenxing; Wu, Ying; Zheng, Nanning (2018). „Společný objev a segmentace videoobjektů propojenými dynamickými Markovovými sítěmi“ (PDF). Transakce IEEE na zpracování obrazu. 27 (12): 5840–5853. Bibcode:2018ITIP ... 27.5840L. doi:10.1109 / tip.2018.2859622. ISSN 1057-7149. PMID 30059300. S2CID 51867241.
- ^ Vicente, Sara; Rother, Carsten; Kolmogorov, Vladimir (2011). Kosegmentace objektů. IEEE. doi:10.1109 / cvpr.2011.5995530. ISBN 978-1-4577-0394-2.
- ^ Chen, Ding-Jie; Chen, Hwann-Tzong; Chang, Long-Wen (2012). Kosegmentace videa. New York, New York, USA: ACM Press. doi:10.1145/2393347.2396317. ISBN 978-1-4503-1089-5.
- ^ Lee, Yong Jae; Kim, Jaechul; Grauman, Kristen (2011). Klíčové segmenty pro segmentaci videoobjektů. IEEE. doi:10.1109 / iccv.2011.6126471. ISBN 978-1-4577-1102-2.
- ^ Ma, Tianyang; Latecki, Longin Jan. Kliky s maximální hmotností s omezeními mutexu pro segmentaci video objektů. IEEE CVPR 2012. doi:10.1109 / CVPR.2012.6247735.
- ^ Wang, Le; Lv, Xin; Zhang, Qilin; Niu, Zhenxing; Zheng, Nanning; Hua, Gang (2020). "Cosegmentace objektů v hlučných videích s víceúrovňovým hypergrafem" (PDF). Transakce IEEE na multimédiích. IEEE: 1. doi:10,1109 / tmm.2020.2995266. ISSN 1520-9210.
- ^ A b C Wang, Le; Duan, Xuhuan; Zhang, Qilin; Niu, Zhenxing; Hua, Gang; Zheng, Nanning (2018-05-22). „Segment-Tube: Spatio-Temporal Action Localization in Unntrimmed Videos with Per-Frame Segmentation“ (PDF). Senzory. MDPI AG. 18 (5): 1657. doi:10,3390 / s18051657. ISSN 1424-8220. PMC 5982167. PMID 29789447.
 Materiál byl zkopírován z tohoto zdroje, který je k dispozici pod a Mezinárodní licence Creative Commons Attribution 4.0.
Materiál byl zkopírován z tohoto zdroje, který je k dispozici pod a Mezinárodní licence Creative Commons Attribution 4.0.