OCRopus - OCRopus
 | |
| Vývojáři | Thomas Breuel, DFKI |
|---|---|
| První vydání | 9. dubna 2007[1] |
| Stabilní uvolnění | 1.3.3 / 16. prosince 2017 |
| Úložiště | |
| Napsáno | C ++ a Krajta |
| Operační systém | FreeBSD, Linux, Mac OS X |
| Typ | Optické rozpoznávání znaků |
| Licence | Licence Apache v2.0 |
| webová stránka | github |
OCRopus je volný, uvolnit analýza dokumentů a optické rozpoznávání znaků (OCR) systém uvolněn pod Licence Apache v2.0 s velmi modulárním designem rozhraní příkazového řádku.
OCRopus je vyvíjen pod vedením Thomase Breuela z Německé výzkumné středisko pro umělou inteligenci v Kaiserslautern, Německo a byla sponzorována společností Google.
Popis
OCRopus byl speciálně navržen pro použití ve velkých objemech digitalizace projekty knih, jako např Knihy Google, Internetový archiv nebo knihovny. Je třeba podporovat velké množství jazyků a písem.[2] Lze jej však také použít pro stolní a kancelářské aplikace nebo pro aplikace pro zrakově postižené.
Hlavní součásti OCRopus jsou tvořeny:
Pro tyto komponenty je k dispozici jeden nebo více skriptů. The modulární přístup umožňuje použití jednotlivých pracovních toků a výměnu jednotlivých kroků.
Ve výchozím nastavení je OCRopus vybaven modelem pro anglické texty a modelem pro text v Fraktur. Tyto modely odkazují na skript a jsou do značné míry nezávislé na skutečném jazyce.[3] Nové znaky nebo jazykové varianty lze procvičovat buď nové, nebo navíc.
Poslední rozpoznávání textu je založeno na rekurentní neuronové sítě (LSTM ) a nevyžaduje jazykový model. To umožňuje trénovat jazykově nezávislé modely, u nichž byly současně prokázány dobré výsledky rozpoznávání angličtiny, němčiny a francouzštiny.[4] Navíc k Latinské písmo, existují výsledky pro další skripty, jako např Sanskrt, Urdu, Devanagari a řecký.
Velmi dobré míry detekce lze dosáhnout vhodným tréninkem. Toto mimořádné úsilí se vyplatí zejména u obtížných dokumentů nebo skriptů, které dnes již nejsou běžné a na které se jiný software OCR nezaměřuje.[5][6]
Dějiny
Dne 9. dubna 2007 byl OCRopus vyhlášen jako projekt sponzorovaný společností Google, jehož cílem je vývoj pokročilých technologií OCR.[1] Financování bylo poskytováno na dobu tří let a pokrývalo zejména doktorské a postdoktorské pozice v DFKI a University of Kaiserslautern. Na oplátku byl OCRopus také použit pro automatické rozpoznávání textu v Vyhledávání knih Google.[7] Licencování na základě licence s otevřeným zdrojovým kódem bylo uděláno hned od začátku, aby se usnadnila spolupráce mezi průmyslovým a akademickým výzkumem.[8] OCRopus získal další financování od Andrew W. Mellon Foundation a BMBF.[9]
První alfa verze 0.1 byla vydána 22. října 2007 a od prosince 2007 do května 2009 následovalo několik předběžných verzí, které v březnu 2010 dosáhly stabilní verze 0.4.4.[10] Software byl původně vyvinut v C ++, Krajta a Lua s Džem jako vybudovat systém. Kompletní refaktorování zdrojového kódu v Pythonových modulech bylo hotovo a vydáno ve verzi 0.5 (červen 2012).[11]
Zpočátku, Tesseract byl použit jako jediný modul pro rozpoznávání textu. Od roku 2009 (verze 0.4) byl Tesseract podporován pouze jako plugin. Místo toho byl použit samostatně vyvinutý rozpoznávač textu (také segmentový).[12] Tento rozpoznávač byl poté použit společně s OpenFST[13] pro jazykové modelování po kroku rozpoznávání. Od roku 2013 další uznání s rekurentní neuronové sítě (LSTM ), který je s vydáním verze 1.0 v listopadu 2014 jediným rozpoznávačem.[14][15]
Zdrojový kód je spravován přes GitHub a je udržována a vyvíjena komunitou vývojářů.[16] Aktuální verze OCRopus je 1.3.3 (prosinec 2017).[17]
Používání
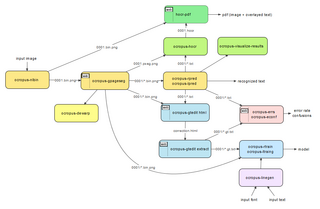
OCRopus lze použít z příkazového řádku. Po instalaci jej lze vyvolat zadáním vstupních obrazů. Výstup rozpoznaného textu do standardní výstup přímo nebo jej napište jako hOCR (HTML -na základě) kód do souborů, ze kterých je pak možné jej transformovat do prohledávatelného PDF. Pokud je zapotřebí přesnější ovládání, lze na příkazovém řádku zadat možnosti pro provedení konkrétních operací (např. Rozpoznání jednoho řádku).[18]
Příklad volání OCRopus k rozpoznání textu v obrázku:
# provést testy binarizationocropus-nlbin / ersch.png -o kniha # provést analýzu rozložení stránky knihaococropus-gpageseg / 0001.bin.png # provést rozpoznání textového řádku (s modelem fraktur) modely ocropus-rpred -m / fraktur.pyrnn.gz kniha / 0001 / *. bin.png # generovat výstup HTML kniha oropus-hocr / 0001.bin.png -o kniha / 0001.htmlDalší nástroje se soustředí na tréninkovou část OCRopus. Existují modely OCRopus pro extrakci textu ze skriptů latinky, řečtiny, cyrilice a indiky.[19]
Reference
- ^ A b Breuel, Thomas (9. dubna 2007). „Oznámení OCRopus Open Source OCR systému“. Blog vývojářů Google. Citováno 29. prosince 2017.
- ^ Breuel, Thomas (2009). Nedávný pokrok v systému OCRopus OCR. Sborník z mezinárodního semináře o vícejazyčném OCR. MOCR '09. New York, NY, USA: ACM. 2: 1–2: 10. doi:10.1145/1577802.1577805. ISBN 9781605586984.
- ^ „Modely“. ocropy wiki. Citováno 5. ledna 2018.
- ^ Ul-Hasan, Adnan; Breuel, Thomas M. (2013). Můžeme pomocí sítí LSTM vytvářet jazykově nezávislé OCR?. Sborník ze 4. mezinárodního workshopu o vícejazyčném OCR. MOCR '13. New York, NY, USA: ACM. str. 9: 1–9: 5. doi:10.1145/2505377.2505394. ISBN 9781450321143.
- ^ Springmann, Uwe (1. prosince 2016). „OCR für alte Drucke“. Informatik-Spektrum (v němčině). 39 (6): 459–462. doi:10.1007 / s00287-016-1004-3. ISSN 0170-6012.
- ^ Simistira, F .; Ul-Hassan, A .; Papavassiliou, V .; Gatos, B .; Katsouros, V .; Liwicki, M. (srpen 2015). Rozpoznávání historických řeckých polytonických skriptů pomocí sítí LSTM. 13. mezinárodní konference o analýze a uznávání dokumentů 2015 (ICDAR). str. 766–770. doi:10.1109 / icdar.2015.7333865. ISBN 978-1-4799-1805-8.
- ^ „Výzkumný projekt OCRopus“. www.dfki.de. Citováno 5. ledna 2018.
- ^ Breuel, Thomas M. (28. ledna 2008). Msgstr "Otevřený OCR systém OCRopus". Sborník Svazek 6815, Rozpoznávání a načítání dokumentů XV. Rozpoznávání a načítání dokumentů XV. 6815: 68150F – 68150F – 15. Bibcode:2008SPIE.6815E..0FB. CiteSeerX 10.1.1.99.8505. doi:10.1117/12.783598.
- ^ „web projektu ocropus“. Hosting projektu Google. Leden 2019. Archivovány od originál dne 24. prosince 2012.
- ^ "Starší verze - ocropy". GitHub. Citováno 5. ledna 2018.
- ^ „OCRopus 0,5“. Skupiny Google. 2. června 2012.
- ^ OCRopus se ve výchozím nastavení ani nepřipojuje k Tesseractu.
- ^ Oficiální web OpenFST.
- ^ „ocropy - vydání v1.0“. GitHub. 2. listopadu 2014. Citováno 5. ledna 2018.
- ^ Breuel, T. M .; Ul-Hasan, A .; Al-Azawi, M. A .; Shafait, F. (srpen 2013). Vysoce výkonné OCR pro tištěnou angličtinu a fraktur pomocí sítí LSTM. 2013 12. mezinárodní konference o analýze a uznávání dokumentů. str. 683–687. doi:10.1109 / icdar.2013.140. ISBN 978-0-7695-4999-6.
- ^ „ocropy: Pythonovské nástroje pro analýzu dokumentů a OCR“, GitHub, vyvoláno 5. ledna 2018
- ^ „Uvolňuje okropii“. GitHub. Citováno 5. ledna 2018.
- ^ „ocropy wiki“. GitHub. Citováno 30. prosince 2017.
- ^ „modely okropie“. GitHub. Citováno 13. března 2018.
externí odkazy
- ocropy na GitHub
- Ocropy wiki na GitHubu
- Publikační server IUPR (články za mnoha algoritmy používanými v OCRopus)