Dvojjazyčná interaktivní aktivace plus - Bilingual interactive activation plus
Dvojjazyčná interaktivní aktivace plus (BIA +) je model pro pochopení procesu bilingvní porozumění jazyku a skládá se ze dvou interaktivních subsystémů: subsystému identifikace slova a subsystému úkol / rozhodnutí.[1] Je nástupcem modelu Bilingual Interactive Activation (BIA) [2] který byl aktualizován v roce 2002 tak, aby zahrnoval fonologický a sémantický lexikální reprezentace, revidovat roli jazykových uzlů a specifikovat čistě dvojjazyčnou povahu zpracování dvojjazyčných jazyků.
Přehled
BIA + je jedním z mnoha modelů, které byly definovány na základě dat z psycholingvistické nebo behaviorální studie, které zkoumají, jak se manipuluje s jazyky dvojjazyčných jazyků během poslechu, čtení a mluvení každého z nich; BIA + však nyní podporuje neuroimaging data spojující tento model s neurálně inspirovanými, které se více zaměřují na oblasti mozku a mechanismy zapojené do těchto úkolů.
Dva základní nástroje těchto studií jsou: potenciál související s událostmi (ERP), který má vysoký časové rozlišení ale nízká prostorové rozlišení a funkční magnetická rezonance (fMRI), která má obvykle vysoké prostorové rozlišení a nízké časové rozlišení. Pokud se však tyto dvě metody použijí společně, mohou generovat úplnější obraz časového průběhu a interaktivity zpracování dvojjazyčných jazyků podle modelu BIA +.[1] Tyto metody je však třeba pečlivě zvážit, protože překrývající se oblasti aktivace v mozku neznamenají, že neexistuje funkční oddělení mezi těmito dvěma jazyky na úrovni neuronů nebo vyšších řádů.[3]
Modelové předpoklady[1]
- Rozlišování 2 subsystémů: identifikace slova vs. úkol / rozhodnutí
- Integrovaný lexikon
- Neselektivní přístup k lexikonu
- Paralelní přístup
- Časové zpoždění L2
- Kontrola úlohy / rozhodnutí zdola nahoru od identifikace slova
- Kontext v místním jazyce neovlivňuje identifikaci slova
- Kontext věty může ovlivnit identifikaci slova
- Globální jazykový kontext neovlivňuje identifikaci slov
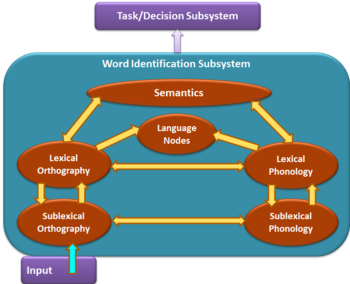
Rozlišování 2 subsystémů: identifikace slova vs. úkol / rozhodnutí
Podle modelu BIA + zobrazeného na obrázku vizuální vstup během identifikace slova aktivuje sublexical ortografický reprezentace, které současně aktivují jak pravopisný celoslovný lexikální, tak sublexický fonologický reprezentace. Celoslovná ortografická i fonologická reprezentace poté aktivují sémantická reprezentace a jazykové uzly, které označují příslušnost k určitému jazyku. Všechny tyto informace se poté použijí v subsystému úkol / rozhodnutí k provedení zbývající části úkolu. Tyto dva subsystémy jsou dále popsány předpoklady s nimi spojenými níže.
Subsystém identifikace slova
Integrovaný lexikon
Předpoklad integrovaného lexikonu popisuje interaktivitu vizuální reprezentace slova nebo slovních částí a pravopis, fonologický nebo sluchová složka jazykového zpracování a sémantický nebo významové a významové reprezentace slov.[4] Tato teorie byla testována na ortografických sousedech, slovech stejné délky, která se liší pouze jedním písmenem (např.BALL a FALL). Počet sousedů cílového a necílového jazyka ovlivnil zpracování cílového textu v primárním jazyce (L1) i v sekundárním jazyce (L2).[5] Tento křížový efekt sousedství měl odrážet koaktivaci slov bez ohledu na jazyk, do kterého patří, tj. Lexikální přístup, který je jazykově neselektivní. Cílový i necílový jazyk lze automaticky a nevědomě aktivovat i v čistě jednojazyčném režimu. To však neznamená, že nemusí existovat funkce jedinečné pro jeden jazyk (tj. Použití různých abeced) nebo že na sémantické úrovni neexistují žádné sdílené funkce.
Jazykové uzly / značky
Tento předpoklad uvádí, že jazykové uzly / značky existují, aby poskytovaly reprezentaci jazyka členství na základě informací z předcházejících ortografických a fonologických procesů ID slov. Podle modelu BIA + nemají tyto značky žádný vliv na reprezentaci slov na úrovni aktivace.[1] Zaměření aktivace těchto uzlů je postlexické: existence těchto uzlů umožňuje dvojjazyčným jednotlivcům, aby při zpracování jednoho ze svých jazyků nedostali příliš mnoho rušení z necílového jazyka.
Neselektivní / paralelní přístup
Paralelní přístup předpokládá, že jazyk je neselektivní a že obě potenciální možnosti slov jsou aktivovány v dvojjazyčném mozku, když jsou vystaveny stejnému podnětu. Bylo například zjištěno, že testovací subjekty čtou ve svém druhém jazyce nevědomě přeložit do jejich primárního jazyka.[6] N400 měření aktivace stimulační odezvy ukazují, že sémantická priming účinky byly pozorovány v obou jazycích a jednotlivec nemůže vědomě soustředit svou pozornost pouze na jeden jazyk, i když mu bylo řečeno, aby ignoroval druhý.[7]Tento neselektivní lexikální přístup k tomuto jazyku byl prokázán během sémantické aktivace napříč jazyky, ale také na ortografické a fonologické úrovni.
Časové zpoždění L2
Předpoklad časového zpoždění je založen na principu klidový potenciál aktivace, která odráží frekvenci používání slov dvojjazyčným způsobem, takže vysokofrekvenční slova korelují s aktivačními potenciály vysoké klidové úrovně a slova používaná s malou frekvencí korelují s nízkými klidovými aktivačními potenciály. Vysoký klidový potenciál je ten, který je méně záporný nebo blíží se nule, bodu aktivace, a proto potřebuje méně stimulů, aby se stal aktivovaným. Protože méně běžně používaná slova L2 mají aktivaci na nižší klidové úrovni, je pravděpodobné, že L1 bude aktivována před L2, jak je vidět na vzorcích N400 ERP.[8]
Tato klidová aktivace slov také odráží úroveň znalostí dvojjazyčných jazyků a jejich frekvenci používání těchto dvou jazyků. Když dvojjazyčný jazykové znalosti je nižší v L2 než L1, bude aktivace lexikálních reprezentací L2 dále odložena, protože je pro ovládání jazyka nutná rozsáhlejší nebo vyšší aktivace mozku.[4] Dvojjazyční lidé s nízkou i vysokou odborností mají paralelní aktivaci slovních reprezentací, avšak méně zdatný jazyk L2 se aktivuje pomaleji, což přispívá k předpokladu časového zpoždění.
Lokalizace slovní identifikace v mozku
Umístění mnoha úkolů zpracování identifikace slova byla stanovena studiemi fMRI. Načítání slov je lokalizováno v Brocova oblast z prefrontální kůra,[9] zatímco ukládání informací je lokalizováno v podřízenosti spánkové laloky Globálně se ukázalo, že stejné oblasti mozku jsou aktivovány napříč L1 a L2 u vysoce zdatných dvojjazyčných lidí. Některé jemné rozdíly mezi aktivacemi L1 a L2 se však objevují při testování méně zdatných dvojjazyků.
Subsystém úkol / rozhodnutí
Subsystém úkol / rozhodnutí modelu BIA + určuje, jaké akce je třeba provést pro danou úlohu na základě příslušných informací, které budou k dispozici po zpracování identifikace slova.[1] Tento subsystém zahrnuje mnoho výkonných procesů včetně monitorování a řízení souvisejících s prefrontální kůra.
Kontrola úlohy / rozhodnutí zdola nahoru od identifikace slova
Akční plány, které splňují daný úkol, provádí systém úkolů / rozhodování na základě aktivačních informací ze subsystému identifikace slova.[7] Studie, které testovaly dvojjazyčné jazyky s homografie ukázaly, že konflikty mezi čtením homografů v cílovém a necílovém jazyce stále vedly k rozdílu v aktivaci mezi nimi a kontrolou, což znamená, že dvojjazyční lidé nejsou schopni regulovat aktivaci v systému identifikace slov.[10] Akční plány systému úkolů / rozhodování proto nemají přímý vliv na aktivaci subsystému jazyka pro identifikaci slov.
Lokalizace úkolu / rozhodnutí v mozku
Nervové koreláty subsystému úkol / rozhodnutí se skládají z několika komponent, které se mapují na různé oblasti prefrontální kůry odpovědné za provádění řídících funkcí. Například bylo zjištěno, že obecné výkonné funkce přepínání jazyků aktivují přední cingulární kůra a dorsolaterální prefrontální kůra oblasti.,[11][12]
Překlad na druhé straně vyžaduje řízené akce v jazykových reprezentacích a byl spojen s levicí bazální ganglia,[12][13] Levá kádové jádro byla spojena s kontrolou používaného jazyka,[14] a vlevo uprostředprefrontální kůra je zodpovědný za sledování rušení a potlačování konkurenčních odpovědí mezi jazyky.,[13][15]
Příklad
Podle modelu BIA + překládá slovo dvojjazyčný jazyk s angličtinou jako primárním jazykem a španělštinou jako sekundárním jazykem reklama od španělštiny po angličtinu, nastává několik kroků. Dvojjazyčný by použil ortografické a fonologické podněty k odlišení tohoto slova od podobného anglického slova reklama. V tomto okamžiku však dvojjazyčný automaticky odvozuje sémantický význam slova, nejen pro správný španělský význam advertencia, který je Varování ale také pro španělský význam reklamy, který je publicidad.
Tyto informace by pak byly uloženy v dvojjazyčném jazyce pracovní paměť a používá se v systému úkolů / rozhodování k určení, který ze dvou překladů nejlépe vyhovuje danému úkolu. Protože původní pokyny měly překládat ze španělštiny do angličtiny, dvojjazyčný by vybral správný překlad reklama být Varování a ne reklama.
Rozdíly mezi předchůdci BIA + a BIA
Zatímco modely BIA + sdílejí několik podobností se svým předchůdcem, modelem BIA, existuje mezi nimi několik odlišných rozdílů. První a nejpozoruhodnější je čistě zdola nahoru povaha modelu BIA +, která předpokládá, že informace ze subsystému úkol / rozhodnutí nemohou ovlivnit subsystém identifikace slova, zatímco model BIA předpokládá, že tyto dva systémy mohou plně interagovat.
Zadruhé je to, že uzly jazykových členů modelu BIA + neovlivňují úrovně aktivace systému identifikace slov, zatímco hrají inhibiční role v modelu BIA.
Konečně by očekávání účastníků mohla potenciálně ovlivnit systém úkolů / rozhodování v modelu BIA +; model BIA však předpokládá, že neexistuje žádný silný vliv na stav aktivace slov na základě očekávání.[1]
Budoucnost
Model BIA + byl podporován mnoha kvantitativními neuroimaging studia, ale je třeba dokončit další výzkum, aby se model posílil jako průkopník v přijímaných modelech pro zpracování dvojjazyčných jazyků. V systému úkolů / rozhodování jsou součásti úkolu dobře definované (např. Překlad, přepínání jazyků), ale rozhodovací součásti podílející se na provádění těchto úkolů v subsystému jsou blíže neurčené. Vztah komponent v tomto subsystému vyžaduje další prozkoumání, aby bylo možné plně porozumět.
Vědci také zvažují použití magnetoencefalografie (MEG) v budoucích studiích. Tato technologie by spojila procesy prostorové aktivace s časovými vzory mozkové odezvy přesněji než současně s ohledem na data odezvy z ERP a fMRI, která jsou omezenější.
Studie nejen naznačují, že výkonné fungování dvojjazyčnosti přesahuje jazykový systém, ale dvojjazyčníci se také ukázali jako rychlejší zpracovatelé, kteří vykazují méně konfliktních účinků než jednojazyční v úlohách zaměřených na pozornost[16] Tento výzkum naznačuje, že mohou existovat určité vedlejší účinky učení se druhého jazyka na jiné oblasti kognitivních funkcí, které by mohly být prozkoumány.
Jedna teorie budoucího směru dál dvojjazyčné rozpoznávání slov je třeba vzít v úvahu vývojové aspekty dvojjazyčný lexikální přístup.[17] Většina studií zkoumala vysoce zdatné dvojjazyčné jazyky, ale jen málo z nich se zabývalo málo zdatnými dvojjazyčníky nebo dokonce studenty L2. Tento nový směr by měl přinést spoustu vzdělávacích aplikací.
Reference
- ^ A b C d E F van Heuven, W.J.B., Dijkstra, T., 2010. Porozumění jazyka v dvojjazyčném mozku: podpora fMRI a ERP pro psycholingvistické modely. Recenze výzkumu mozku 64, 104–122
- ^ Dijkstra, T., Van Heuven, W. J. B. a Grainger, J. (1998). Simulace křížové soutěže s dvojjazyčným interaktivním aktivačním modelem. Psychologica Belgica, 38, 177–196.
- ^ Hernandez, A., Li, P., MacWhinney, B., 2005. Vznik konkurenčního modulu v dvojjazyčnosti. Trends in Cognitive Sciences 9, 220–225
- ^ A b Briellmann, R.S., Saling, M.M., Connell, A.B., Waites, A.B., Abbott, D.F., Jackson G.D., 2004. Funkční studie MRI čtyřjazykových předmětů na vysoké úrovni. Mozková země. 89, 531–542
- ^ van Heuven, W. J. B., Dijkstra, T., Grainger, J., 1998. Ortografické efekty sousedství v dvojjazyčném rozpoznávání slov. Journal of Memory and Language 39, 458–483
- ^ Thierry, G., Wu, Y.J., 2007. Mozkový potenciál odhaluje nevědomý překlad během porozumění cizímu jazyku. Sborník Národní akademie věd. USA 104, 12530-12535
- ^ A b Martin, C.D., Dering, B., Thomas, E.M., Thierry, G., 2009. Mozkové potenciály odhalují sémantické primování v „aktivním“ i „nenavštěvovaném“ jazyce u raných dvojjazyčných jazyků. NeuroImage 47, 326–333
- ^ Moreno, E.M., Kutas, M., 2009. Zpracování sémantické anomálie ve dvou jazycích: elektrofyziologický průzkum španělsko-anglických dvojjazyčných jazyků v obou jazycích. Výzkum kognitivních mozků 22, 205–220
- ^ Thompson-Schill, S.L., D'Esposito, M., Aguirre, G.K., Farah, M.J., 1997. Role levé dolní parietální kůry při získávání sémantických znalostí: přehodnocení. Proceedings of the National Academy of Sciences of the United States of America 94, 14792-14797
- ^ van Heuven, W.J.B., Schriefers, H., Dijkstra, T. Hagoort, P., 2008. Jazykové konflikty v dvojjazyčném mozku. Cerebral Cortex 18, 458–483
- ^ Hernandez, A.E. 2009. Přepínání jazyků v dvojjazyčném mozku: co bude dál? Mozek a jazyk 109, 133–140
- ^ A b Price, C.J., Green, D.W., von Studnitz, R.1999. Funkční zobrazovací studie překladu a přepínání jazyků. Brain 122, 2221–2235
- ^ A b Lehtonen, M.H., Laine, M., Niemi, J., Thomsen, T., Vorobyev, V.A., Hugdhal, K., 2005. Mozkové koreláty překladu vět ve finsko-norských dvojjazycích. NeuroReport 16, 607–610
- ^ Crinion, J., Turner, R., Grogan, A., Hanakawa, T., Noppeney, U., Devlin, J.T., et al, 2006. Řízení jazyka v dvojjazyčném mozku. Science 312, 1537–1540
- ^ Rodriquez-Fornells, A., van der Lugt, A., Rotte, M., Britti, B., Heinze, HJ, Munte, TF, 2005. Druhý jazyk interferuje s produkcí slov v plynulých dvojjazycích: mozkový potenciál a funkční zobrazovací důkazy . Journal of Cognitive Neuroscience 17, 422–433
- ^ Costa, A., Hernandez, M., Sebastian-Galles, N., 2008. Bilingvismus pomáhá při řešení konfliktů: důkazy z úkolu ANT. Poznání 106, 59–86
- ^ Grainger, J., Midgley, K., & Holcomb, P.J. (2010). Přemýšlení o dvojjazyčném interaktivním aktivačním modelu z vývojové perspektivy (BIA-d). In M. Kail & M. Hickmann (Eds.), Language Acquisition across Linguistic and Cognitive Systems. New York: John Benjamins (s. 267–284).