Sklon jedna - Slope One - Wikipedia
Sklon jedna je rodina algoritmů používaných pro společné filtrování, představený v příspěvku z roku 2005 Danielem Lemire a Annou Maclachlan.[1] Pravděpodobně je to nejjednodušší forma netriviální filtrování spolupráce založené na položkách na základě hodnocení. Jejich jednoduchost usnadňuje jejich efektivní implementaci, zatímco jejich přesnost je často srovnatelná s komplikovanějšími a výpočetně nákladnými algoritmy.[1][2] Byly také použity jako stavební bloky pro vylepšení dalších algoritmů.[3][4][5][6][7][8][9] Jsou součástí hlavních open-source knihoven, jako jsou Apache Mahout a Easyrec.
Filtrování spolupráce na základě položek hodnocených zdrojů a nadměrné vybavení
Jsou-li k dispozici hodnocení položek, například v případě, že lidé dostanou možnost zdrojů hodnocení (například mezi 1 a 5), je cílem filtrování spolupráce předpovědět hodnocení jednoho jednotlivce na základě jeho minulých hodnocení a na ( velká) databáze hodnocení od ostatních uživatelů.
Příklad: Můžeme předpovědět hodnocení, které by jednotlivec přidělil novému albu Celine Dion vzhledem k tomu, že dal Beatles 5 z 5?
V této souvislosti filtrování spolupráce založené na položkách [10][11] předpovídá hodnocení jedné položky na základě hodnocení jiné položky, obvykle pomocí lineární regrese (). Pokud tedy existuje 1 000 položek, může se naučit až 1 000 000 lineárních regresí, a tedy až 2 000 000 regresorů. Tento přístup může trpět vážným nadměrné vybavení[1] pokud nevybereme pouze dvojice položek, pro které několik uživatelů hodnotilo obě položky.

Lepší alternativou může být naučit se jednodušší prediktor, jako je : experimenty ukazují, že tento jednodušší prediktor (nazývaný Slope One) někdy překonává[1] lineární regrese, přičemž má poloviční počet regresorů. Tento zjednodušený přístup také snižuje požadavky na úložiště a latenci.

Filtrování spolupráce založené na položkách je jen jednou z forem společné filtrování. Mezi další alternativy patří uživatelské filtrování spolupráce, kde jsou zajímavé vztahy mezi uživateli. Filtrování spolupráce založené na položkách je však obzvláště škálovatelné s ohledem na počet uživatelů.
Filtrování nákupních statistik na základě spolupráce
Hodnocení nedostáváme vždy: když uživatelé poskytnou pouze binární data (položka byla zakoupena nebo ne), pak Slope One a další algoritmus založený na hodnocení neplatí[Citace je zapotřebí ]. Mezi příklady filtrování spolupráce založeného na binárních položkách patří Amazon položka na položku patentovaný algoritmus[12] který počítá kosinus mezi binárními vektory představujícími nákupy v matici uživatelské položky.
Algoritmus Item-to-Item, který je prokazatelně jednodušší než dokonce Slope One, nabízí zajímavý referenční bod. Zvažte příklad.
| Zákazník | Položka 1 | Položka 2 | Položka 3 |
|---|---|---|---|
| John | Koupil to | Nekoupil jsem to | Koupil to |
| Označit | Nekoupil jsem to | Koupil to | Koupil to |
| Lucie | Nekoupil jsem to | Koupil to | Nekoupil jsem to |
V tomto případě je kosinus mezi položkami 1 a 2:
,

Kosinus mezi položkami 1 a 3 je:
,

Zatímco kosinus mezi položkami 2 a 3 je:
.

Uživatel, který navštíví položku 1, by proto obdržel položku 3 jako doporučení, uživatel navštěvující položku 2 by obdržel položku 3 jako doporučení, a nakonec by uživatel navštěvující položku 3 obdržel položku 1 (a poté položku 2) jako doporučení. Model k provedení doporučení používá jeden parametr na pár položek (kosinus). Proto, pokud existují n položek, až n (n-1) / 2 kosiny je třeba vypočítat a uložit.
Nakloňte se ke společnému filtrování hodnocených zdrojů
Drasticky snížit nadměrné vybavení, zlepšit výkon a usnadnit implementaci, Sklon jedna rodina snadno implementovatelných hodnocení založených na položkách společné filtrování byly navrženy algoritmy. V podstatě namísto použití lineární regrese z hodnocení jedné položky na hodnocení jiné položky (), používá jednodušší formu regrese s jediným volným parametrem (). Volný parametr je pak jednoduše průměrný rozdíl mezi hodnocením těchto dvou položek. Ukázalo se, že v některých případech je mnohem přesnější než lineární regrese,[1] a zabere to polovinu úložiště nebo méně.
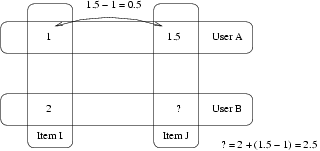
Příklad:
- Uživatel A dal 1 položce I a 1,5 položce J.
- Uživatel B dal 2 na položku I.
- Jak si myslíte, že uživatel B ohodnotil položku J?
- Odpověď Slope One zní 2,5 (1,5-1 + 2 = 2,5).
Pro realističtější příklad zvažte následující tabulku.
| Zákazník | Položka A | Položka B | Položka C |
|---|---|---|---|
| John | 5 | 3 | 2 |
| Označit | 3 | 4 | Nehodnotili to |
| Lucie | Nehodnotili to | 2 | 5 |
V tomto případě je průměrný rozdíl v hodnocení mezi položkami B a A (2 + (- 1)) / 2 = 0,5. Proto je položka A v průměru hodnocena nad položkou B o 0,5. Podobně je průměrný rozdíl mezi položkami C a A 3. Pokud se tedy pokusíme předpovědět hodnocení Lucy pro položku A pomocí jejího hodnocení pro položku B, dostaneme 2 + 0,5 = 2,5. Podobně, pokud se pokusíme předpovědět její hodnocení položky A pomocí jejího hodnocení položky C, dostaneme 5 + 3 = 8.
Pokud uživatel ohodnotil několik položek, předpovědi se jednoduše zkombinují pomocí váženého průměru, kde dobrou volbou pro váhu je počet uživatelů, kteří hodnotili obě položky. Ve výše uvedeném příkladu hodnotili John i Mark položky A a B, tedy váhu 2 a pouze John hodnotil obě položky A a C, tedy váhu 1, jak je uvedeno níže. předpovídali bychom následující hodnocení pro Lucy v položce A jako:

Proto, vzhledem k tomu n položek, k implementaci Slope One, vše, co je potřeba, je spočítat a uložit průměrné rozdíly a počet společných hodnocení pro každou z n2 páry položek.
Algoritmická složitost svahu jedna
Předpokládejme, že existují n položky, m uživatelé a N hodnocení. Výpočet průměrných rozdílů v hodnocení pro každou dvojici položek vyžaduje až n (n-1) / 2 skladovací jednotky a až m n2 časové kroky. Tato výpočetní vazba může být pesimistická: pokud předpokládáme, že uživatelé hodnotili až y položek, pak je možné vypočítat rozdíly maximálně n2+můj2. Pokud uživatel vstoupil X hodnocení, je třeba předpovědět jediné hodnocení X časové kroky a předvídání všech jeho chybějících hodnocení vyžaduje až (n-x)X časové kroky. Aktualizace databáze, když již uživatel vstoupil X hodnocení a zadá nové, vyžaduje X časové kroky.
Je možné snížit požadavky na úložiště rozdělením dat (viz Oddíl (databáze) ) nebo pomocí rozptýleného úložiště: dvojice položek, které nemají žádného (nebo jen málo) uživatelů, kteří mají coating, lze vynechat.
Poznámky pod čarou
- ^ A b C d E Daniel Lemire, Anna Maclachlan, Slope One Predictors for Online Rating-Based Collaborative Filtering, V SIAM Data Mining (SDM'05), Newport Beach, Kalifornie, 21. – 23. Dubna 2005.
- ^ Fidel Cacheda, Victor Carneiro, Diego Fernandez a Vreixo Formoso. 2011. Porovnání algoritmů filtrování spolupráce: Omezení současných technik a návrhů pro škálovatelné, vysoce výkonné systémy doporučení. ACM Trans. Web 5, 1, článek 2
- ^ Pu Wang, HongWu Ye, Personalizovaný doporučující algoritmus kombinující schéma prvního svazku a uživatelské filtrování založené na spolupráci, IIS '09, 2009.
- ^ DeJia Zhang, Algoritmus doporučení pro společné filtrování založený na položkách využívající vyhlazení schématu jednoho schématu, ISECS '09, 2009.
- ^ Min Gaoa, Zhongfu Wub a Feng Jiang, Userrank pro doporučení pro filtrování spolupráce založené na položkách, Information Processing Letters Volume 111, číslo 9, 1. dubna 2011, str. 440-446.
- ^ Mi, Zhenzhen a Xu, Congfu, Algoritmus doporučení kombinující metodu shlukování a schéma Slope One, Lecture Notes in Computer Science 6840, 2012, str. 160-167.
- ^ Danilo Menezes, Anisio Lacerda, Leila Silva, Adriano Veloso a Nivio Ziviani. 2013. Vážené svahy, jeden prediktor se vrátil. Ve sborníku z 22. mezinárodní konference o World Wide Web Companion (WWW '13 Companion). Řídící výbor pro mezinárodní konference na webu, Republika a kanton Ženeva, Švýcarsko, 967-972.
- ^ Sun, Z., Luo, N., Kuang, W., Jeden personalizovaný doporučovací systém v reálném čase založený na algoritmu Slope One, FSKD 2011, 3, čl. Ne. 6019830, 2012, s. 1826-1830.
- ^ Gao, M., Wu, Z., Personalizované kontextové filtrování založené na spolupráci založené na neuronové síti a svahu jedna, LNCS 5738, 2009, str. 109-116
- ^ Slobodan Vucetic, Zoran Obradovic: Kolaborativní filtrování pomocí regresního přístupu. Knowl. Inf. Syst. 7 (1): 1-22 (2005)
- ^ Badrul M. Sarwar, George Karypis, Joseph A. Konstan, John Riedl: Algoritmy doporučení pro filtrování spolupráce založené na položkách. WWW 2001: 285-295
- ^ Greg Linden, Brent Smith, Jeremy York, „Doporučení Amazon.com: Filtrování jednotlivých položek,“ IEEE Internet Computing, sv. 07, č. 1, str. 76-80, leden / únor 2003