Skupinové testování - Group testing
v statistika a kombinatorická matematika, skupinové testování je jakýkoli postup, který rozdělí úkol identifikovat určité objekty do testů na skupinách položek, spíše než na jednotlivých. Nejprve studoval Robert Dorfman v roce 1943 je skupinové testování relativně novým oborem aplikované matematiky, který lze aplikovat na širokou škálu praktických aplikací a je dnes aktivní oblastí výzkumu.
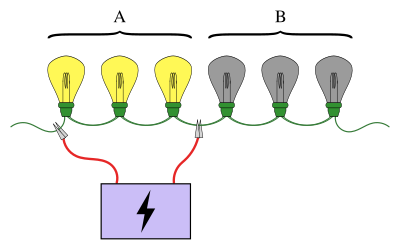
Známý příklad skupinového testování zahrnuje řetězec žárovek zapojených do série, kde je známo, že právě jedna z žárovek je rozbitá. Cílem je najít rozbitou žárovku pomocí nejmenšího počtu testů (přičemž zkouškou je test, kdy jsou některé z těchto žárovek připojeny k napájecímu zdroji). Jednoduchým přístupem je otestovat každou žárovku zvlášť. Pokud však existuje velké množství žárovek, bylo by mnohem efektivnější sloučit žárovky do skupin. Například připojením první poloviny žárovek najednou lze určit, ve které polovině je poškozená žárovka, což vylučuje polovinu žárovek pouze v jednom testu.
Schémata pro provádění skupinového testování mohou být jednoduchá nebo složitá a testy v každé fázi se mohou lišit. Schémata, ve kterých testy pro další fázi závisí na výsledcích předchozích fází, se nazývají adaptivní postupy, zatímco jsou volána schémata navržená tak, aby byly předem známy všechny testy neadaptivní postupy. Struktura schématu testů zapojených do neadaptivního postupu je známá jako a sdružování design.
Skupinové testování má mnoho aplikací, včetně statistik, biologie, počítačové vědy, medicíny, strojírenství a kybernetické bezpečnosti. Moderní zájem o tyto testovací schémata znovu vzbudil Projekt lidského genomu.[1]
Základní popis a pojmy
Na rozdíl od mnoha oblastí matematiky lze počátky skupinového testování vysledovat až k jediné zprávě[2] napsal jedna osoba: Robert Dorfman.[3] Motivace vznikla během druhé světové války, kdy Služba veřejného zdraví USA a Selektivní služba pustil se do velkého projektu, aby všechny vyřadil syfilitický muži vyvolali indukci. Testování jedince na syfilis zahrnuje odebrání vzorku krve z nich a následnou analýzu vzorku, aby se určila přítomnost nebo nepřítomnost syfilisu. V té době bylo provedení tohoto testu nákladné a testování každého vojáka jednotlivě by bylo velmi nákladné a neefektivní.[3]
Předpokládejme, že existují vojáků, tato metoda testování vede k samostatné testy. Pokud je infikována velká část lidí, byla by tato metoda rozumná. V mnohem pravděpodobnějším případě, že je infikována jen velmi malá část mužů, lze dosáhnout mnohem efektivnějšího schématu testování. Realizace efektivnějšího testovacího schématu závisí na následující vlastnosti: vojáci mohou být sdruženi do skupin a v každé skupině mohou být vzorky krve kombinovány dohromady. Kombinovaný vzorek lze poté otestovat a zkontrolovat, zda alespoň jeden voják ve skupině má syfilis. Toto je ústřední myšlenka skupinového testování. Pokud má jeden nebo více vojáků v této skupině syfilis, je test zbytečný (je třeba provést více testů, aby se zjistilo, o jaké vojáky se jednalo). Na druhou stranu, pokud nikdo v bazénu nemá syfilis, uloží se mnoho testů, protože každý voják v této skupině může být vyloučen pouze jedním testem.[3]

Položky, které způsobí, že skupina bude mít pozitivní test, se obecně nazývají vadné položky (to jsou rozbité žárovky, syfilitičtí muži atd.). Celkový počet položek je často označen jako a představuje počet defektů, pokud se předpokládá, že jsou známy.[3]

Klasifikace problémů skupinového testování
Existují dvě nezávislé klasifikace problémů se skupinovým testováním; každý problém se skupinovým testováním je buď adaptivní nebo neadaptivní a je pravděpodobnostní nebo kombinatorický.[3]
V pravděpodobnostních modelech se předpokládá, že vadné položky některé následují rozdělení pravděpodobnosti a cílem je minimalizovat očekávaný počet testů potřebných k identifikaci vadnosti každé položky. Na druhou stranu je u kombinatorického skupinového testování cílem minimalizovat počet testů potřebných v „nejhorším scénáři“ - tj. Vytvořit algoritmus minmax - a nepředpokládá se žádná znalost rozdělení závad.[3]
Druhá klasifikace, adaptivita, se týká toho, jaké informace lze použít při výběru položek, které se mají seskupit do testu. Obecně platí, že výběr položek, které se mají testovat, může záviset na výsledcích předchozích testů, jako ve výše uvedeném problému žárovky. An algoritmus který pokračuje provedením testu a poté pomocí výsledku (a všech minulých výsledků) k rozhodnutí, který další test provést, se nazývá adaptivní. Naopak v neadaptivních algoritmech jsou všechny testy rozhodnuty předem. Tuto myšlenku lze zobecnit na vícestupňové algoritmy, kde jsou testy rozděleny do fází a o každém testu v další fázi je třeba rozhodnout předem, pouze s vědomím výsledků testů v předchozích fázích. Ačkoli adaptivní algoritmy nabízejí mnohem větší svobodu v Je známo, že algoritmy adaptivního testování skupin se oproti neadaptivním nezlepšují o více než konstantní faktor v počtu testů potřebných k identifikaci sady vadných položek.[4][3] Kromě toho jsou v praxi často neadaptivní metody užitečné, protože je možné pokračovat v následných testech, aniž by byly nejprve analyzovány výsledky všech předchozích testů, což umožňuje efektivní distribuci testovacího procesu.
Variace a rozšíření
Existuje mnoho způsobů, jak rozšířit problém skupinového testování. Jeden z nejdůležitějších se nazývá hlučný skupinové testování a zabývá se velkým předpokladem původního problému: že testování je bezchybné. Problém se skupinovým testováním se nazývá hlučný, když existuje nějaká šance, že výsledek skupinového testu je chybný (např. Vyjde pozitivní, když test neobsahuje žádné vady). The Bernoulliho šumový model předpokládá, že tato pravděpodobnost je nějaká konstanta, , ale obecně to může záviset na skutečném počtu defektů v testu a počtu testovaných položek.[5] Například účinek ředění lze modelovat tak, že pozitivní výsledek je pravděpodobnější, když je v testu více defektů (nebo více defektů jako zlomek testovaného počtu).[6] Hlučný algoritmus bude mít vždy nenulovou pravděpodobnost chyby (tj. Nesprávného označení položky).

Skupinové testování lze rozšířit zvážením scénářů, ve kterých existují více než dva možné výsledky testu. Výsledky může mít například test a , což odpovídá neexistenci vad, jedné vadě nebo neznámému počtu vad větší než jedna. Obecněji je možné považovat soubor výsledků testu za pro některé .[3]




Dalším rozšířením je uvažovat o geometrických omezeních, na kterých lze sady testovat. Výše uvedený problém s žárovkou je příkladem tohoto druhu omezení: lze testovat pouze žárovky, které se objevují postupně. Podobně mohou být položky uspořádány do kruhu nebo obecně do sítě, kde jsou testy k dispozici cesty v grafu. Dalším druhem geometrického omezení by byl maximální počet položek, které lze testovat ve skupině,[A] nebo velikosti skupin možná budou muset být sudé atd. Podobným způsobem může být užitečné vzít v úvahu omezení, že se daná položka může objevit pouze v určitém počtu testů.[3]
Existuje nekonečné množství způsobů, jak pokračovat v remixování základního vzorce skupinového testování. Následující zpracování poskytne představu o některých exotičtějších variantách. V modelu „dobrý – průměrný – špatný“ je každá položka jednou z hodnot „dobrá“, „průměrná“ nebo „špatná“ a výsledkem testu je typ „nejhorší“ položky ve skupině. Při testování prahové skupiny je výsledek testu pozitivní, pokud je počet vadných položek ve skupině větší než nějaká prahová hodnota nebo poměr.[7] Skupinové testování s inhibitory je variantou s aplikacemi v molekulární biologii. Zde existuje třetí třída položek zvaná inhibitory a výsledek testu je pozitivní, pokud obsahuje alespoň jeden vadný a žádné inhibitory.[8]
Historie a vývoj
Vynález a počáteční pokrok
Koncept skupinového testování poprvé představil Robert Dorfman v roce 1943 v krátké zprávě[2] publikováno v sekci Poznámky v Annals of Mathematical Statistics.[3][b] Zpráva Dorfmana - stejně jako u všech raných prací na skupinovém testování - se zaměřila na pravděpodobnostní problém a zaměřila se na využití nové myšlenky skupinového testování ke snížení očekávaného počtu testů potřebných k vyřazení všech syfilitických mužů v dané skupině vojáků. Metoda byla jednoduchá: rozdělte vojáky do skupin dané velikosti a pomocí individuálního testování (testování položek ve skupinách velikosti jedna) u pozitivních skupin vyhledejte infikované. Dorfman shrnul optimální velikosti skupin pro tuto strategii proti míře prevalence defektů v populaci.[2]
Po roce 1943 zůstalo skupinové testování po řadu let do značné míry nedotčeno. V roce 1957 pak Sterrett vylepšil Dorfmanův postup.[10] Tento novější proces začíná opětovným provedením individuálního testování na pozitivních skupinách, ale zastaví se, jakmile je zjištěn defekt. Poté jsou zbývající položky ve skupině testovány společně, protože je velmi pravděpodobné, že žádný z nich není vadný.
První důkladné zpracování skupinových testů poskytli Sobel a Groll ve své formativní práci na toto téma z roku 1959.[11] Popsali pět nových postupů - kromě zobecnění pro případ, kdy je míra prevalence neznámá - a pro nejoptimálnější poskytli explicitní vzorec pro očekávaný počet testů, které bude používat. Příspěvek také vytvořil spojení mezi skupinovým testováním a teorie informace poprvé, stejně jako diskuse o několika zevšeobecněních problému skupinového testování a poskytnutí některých nových aplikací teorie.
Kombinatorické skupinové testování
Skupinové testování bylo poprvé studováno v kombinatorickém kontextu Li v roce 1962,[12] se zavedením Li - fázový algoritmus.[3] Li navrhl rozšíření Dorfmanova „dvoustupňového algoritmu“ na libovolný počet stupňů, které nevyžadovaly více než je třeba zaručeně najít testy nebo méně vad mezi Myšlenkou bylo odstranit všechny položky v negativních testech a rozdělit zbývající položky do skupin, jak tomu bylo u počátečního fondu. To se mělo udělat před provedením individuálního testování.



Kombinatorické skupinové testování bylo později podrobněji studováno Katonou v roce 1973.[13] Katona představila maticová reprezentace neadaptivního skupinového testování a vytvořil postup pro zjištění defektu u neadaptivního 1-defektního případu ne více než testy, které se také ukázaly jako optimální.

Obecně je nalezení optimálních algoritmů pro adaptivní kombinatorické skupinové testování obtížné a přestože výpočetní složitost skupinového testování nebylo stanoveno, předpokládá se, že je tvrdý v nějaké třídě složitosti.[3] K důležitému průlomu však došlo v roce 1972, kdy byl zaveden zobecněný algoritmus binárního dělení.[14] Zobecněný algoritmus binárního dělení funguje provedením a binární vyhledávání na skupinách, které testují pozitivně, a je to jednoduchý algoritmus, který shledá jednu vadnou za ne více než informace-dolní hranice počet testů.
Ve scénářích, kde existují dva nebo více defektů, generalizovaný algoritmus binárního dělení stále produkuje téměř optimální výsledky, které vyžadují maximálně testy nad dolní mezí informací kde je počet vad.[14] V roce 2013 provedl Allemann značná vylepšení, čímž se požadovaný počet testů snížil na méně než nad dolní mezí informací, když a .[15] Toho bylo dosaženo změnou binárního vyhledávání v algoritmu binárního dělení na komplexní sadu subalgoritmů s překrývajícími se testovacími skupinami. Jako takový byl problém adaptivního kombinatorického skupinového testování - se známým počtem nebo horní mezí počtu defektů - v podstatě vyřešen, s malým prostorem pro další zlepšení.




Existuje otevřená otázka, kdy je individuální testování minmax. Hu, Hwang a Wang v roce 1981 ukázali, že individuální testování je minmax, když , a že to není minmax, když .[16] V současné době se předpokládá, že tato hranice je ostrá: to znamená, že individuální testování je minmax právě tehdy .[17][C] Určitého pokroku dosáhli v roce 2000 Ricccio a Colbourn, kteří to ukázali ve velkém , individuální testování je minmax, když .[18]




Neadaptivní a pravděpodobnostní testování
Jedním z klíčových poznatků v neadaptivním skupinovém testování je, že významného zisku lze dosáhnout odstraněním požadavku, aby byl postup skupinového testování jistý, že uspěje („kombinatorický“ problém), ale spíše mu dovoluje mít určité nízké, ale ne - nulová pravděpodobnost nesprávného označení každé položky („pravděpodobnostní“ problém). Je známo, že jak se počet vadných položek blíží celkovému počtu položek, vyžadují přesná kombinatorická řešení podstatně více testů než pravděpodobnostní řešení - dokonce i pravděpodobnostní řešení umožňující pouze asymptoticky malá pravděpodobnost chyby.[4][d]
V tomto duchu, Chan et al. (2011) COMP, pravděpodobnostní algoritmus, který nevyžaduje více než testy najít vady v položky s pravděpodobností chyby nejvýše .[5] To je v rámci konstantního faktoru dolní mez.[4]



Chan et al. (2011) také poskytli zobecnění COMP na jednoduchý hlučný model a podobně vytvořili explicitní vázaný výkon, který byl opět pouze konstantou (v závislosti na pravděpodobnosti neúspěšného testu) nad odpovídající dolní mezí.[4][5] Obecně je počet zkoušek požadovaných v případě Bernoulliho šumu o konstantní faktor větší než v případě bezhlučného případu.[5]
Aldridge, Baldassini a Johnson (2014) vytvořili rozšíření algoritmu COMP, které přidalo další kroky po zpracování.[19] Ukázali, že výkon tohoto nového algoritmu, tzv DD, striktně překračuje to COMP a toto DD je „v zásadě optimální“ ve scénářích, kde porovnáním s hypotetickým algoritmem, který definuje přiměřené optimum. Výkon tohoto hypotetického algoritmu naznačuje, že existuje prostor pro zlepšení, když , a také navrhnout, jak velké zlepšení by to mohlo být.[19]


Formalizace testování kombinatorické skupiny
Tato část formálně definuje pojmy a pojmy týkající se skupinového testování.
- The vstupní vektor, , je definován jako binární vektor délky (to znamená, ), s j-tá položka, která se volá vadný kdyby a jen kdyby . Jakákoli nezávadná položka se dále nazývá „dobrá“ položka.



je určen k popisu (neznámé) sady vadných položek. Klíčová vlastnost je to, že je implicitní vstup. To znamená, že neexistuje žádná přímá znalost toho, o co jde jsou jiné než ty, které lze odvodit pomocí několika sérií „testů“. To vede k další definici.

- Nechat být vstupním vektorem. Sada, se nazývá a test. Když je testování tichý, výsledek testu je pozitivní když existuje takhle a výsledek je negativní v opačném případě.


Cílem skupinového testování je proto přijít s metodou výběru „krátké“ série testů, které to umožní bude stanoveno, buď přesně, nebo s vysokou mírou jistoty.
- Algoritmus skupinového testování prý dělá chyba pokud položku nesprávně označí (tj. označí jakoukoli vadnou položku jako nezávadnou nebo naopak). Tohle je ne totéž jako výsledek nesprávného skupinového testu. Algoritmus se nazývá nulová chyba pokud je pravděpodobnost, že udělá chybu, nulová.[E]
- označuje minimální počet testů potřebných k nalezení vždy defekty mezi položky s nulovou pravděpodobností chyby jakýmkoli algoritmem skupinového testování. Pro stejnou veličinu, ale s omezením, že algoritmus je neadaptivní, notace se používá.


Obecné hranice
Protože je vždy možné uchýlit se k individuálnímu testování nastavením pro každého , musí to tak být . Jelikož jakýkoli neadaptivní testovací postup lze zapsat jako adaptivní algoritmus pouhým provedením všech testů bez ohledu na jejich výsledek, . Konečně, když , existuje alespoň jedna položka, jejíž vadnost musí být stanovena (alespoň jednou zkouškou) atd .






Souhrnně (při předpokladu ), .[F]

Informace dolní mez
Dolní hranici počtu potřebných testů lze popsat pomocí pojmu ukázkový prostor, označeno , což je jednoduše soubor možných umístění vad. Pro jakýkoli problém s testováním skupiny s ukázkovým prostorem a jakýkoli algoritmus pro testování skupin, lze to ukázat , kde je minimální počet zkoušek požadovaných k identifikaci všech vad s nulovou pravděpodobností chyby. Tomu se říká informace dolní mez.[3] Tato vazba je odvozena ze skutečnosti, že po každém testu je rozdělena do dvou nesouvislých podmnožin, z nichž každá odpovídá jednomu ze dvou možných výsledků testu.



Samotná dolní mez informací je však obvykle nedosažitelná, a to i pro malé problémy.[3] Je to proto, že rozdělení není libovolný, protože musí být proveditelný nějakým testem.
Ve skutečnosti lze dolní mez informací zobecnit na případ, kdy existuje nenulová pravděpodobnost, že algoritmus udělá chybu. V této formě nám věta dává horní hranici pravděpodobnosti úspěchu na základě počtu testů. Pro jakýkoli algoritmus skupinového testování, který funguje testy, pravděpodobnost úspěchu, , splňuje . To lze posílit na: .[5][20]



Reprezentace neadaptivních algoritmů


Algoritmy pro neadaptivní skupinové testování se skládají ze dvou odlišných fází. Nejprve se rozhodne, kolik testů provést a které položky zahrnout do každého testu. Ve druhé fázi, často nazývané krok dekódování, se analyzují výsledky každého skupinového testu, aby se určilo, které položky budou pravděpodobně vadné. První fáze je obvykle kódována v matici následujícím způsobem.[5]
- Předpokládejme neadaptivní postup testování skupiny pro položky se skládá z testů pro některé . The testovací matice pro toto schéma je binární matice, , kde kdyby a jen kdyby (a jinak je nula).





Každý sloupec tedy představuje položku a každý řádek představuje test s a v položka označující, že test zahrnoval položka a označující opak.





Stejně jako vektor (délky ), který popisuje neznámou vadnou množinu, je běžné zavést vektor výsledků, který popisuje výsledky každého testu.
- Nechat je počet testů provedených neadaptivním algoritmem. The vektor výsledků, , je binární vektor délky (to znamená, ) takové, že právě tehdy, pokud je výsledkem test byl pozitivní (tj. obsahoval alespoň jeden vadný).[G]



S těmito definicemi lze neadaptivní problém přejmenovat následujícím způsobem: nejprve je vybrána testovací matice, , po kterém vektor je vrácen. Pak je problém analyzovat najít nějaký odhad pro .

V nejjednodušším hlučném případě, kde je stálá pravděpodobnost, , že skupinový test bude mít chybný výsledek, vezme se v úvahu náhodný binární vektor, , kde každý záznam má pravděpodobnost bytí , a je v opačném případě. Vrácený vektor je pak , s obvyklým doplňkem na (ekvivalentně je to elementární XOR úkon). Hlučný algoritmus musí odhadnout použitím (tj. bez přímé znalosti ).[5]




Meze pro neadaptivní algoritmy
Maticová reprezentace umožňuje dokázat určité hranice při neadaptivním skupinovém testování. Tento přístup odráží to, co existuje u mnoha deterministických návrhů - jsou uvažovány oddělitelné matice, jak je definováno níže.[3]
- Binární matice, , je nazýván -oddělitelný pokud každý booleovský součet (logický OR) libovolného jeho sloupců je odlišný. Navíc notace -oddělitelný označuje, že každý součet některého z až do z sloupce jsou odlišné. (To není totéž jako bytost -oddělitelné pro každého .)



Když je testovací matice, vlastnost bytí -oddělitelné (-separable) je ekvivalentní schopnosti rozlišovat mezi (až) vady. Nezaručuje však, že to bude jednoduché. Silnější vlastnost, tzv -disjunctness dělá.
- Binární matice, je nazýván -disjunct pokud booleovský součet nějakého sloupce neobsahuje žádný další sloupec. (V této souvislosti se říká, že sloupec A obsahuje sloupec B, pokud pro každý index, kde B má 1, má A také 1.)
Užitečná vlastnost -disjunct testování matic je to, že až defektů, každá nezávadná položka se objeví alespoň v jednom testu, jehož výsledek je negativní. To znamená, že pro nalezení defektů existuje jednoduchý postup: stačí odstranit všechny položky, které se objeví v negativním testu.
Používání vlastností -oddělitelné a -disjunct matice následující mohou být ukázány pro problém identifikace defekty mezi celkem položek.[4]
- Počet testů potřebných pro asymptoticky malý průměrný pravděpodobnost chybových stupnic jako .
- Počet testů potřebných pro asymptoticky malý maximum pravděpodobnost chybových stupnic jako .
- Počet testů potřebných pro a nula pravděpodobnost chybových stupnic jako .



Zobecněný algoritmus binárního dělení




Zobecněný algoritmus binárního dělení je v zásadě optimální algoritmus adaptivního testování skupin, který najde nebo méně vad mezi položky takto:[3][14]
- Li , vyzkoušejte položky jednotlivě. Jinak nastavte a .
- Vyzkoušejte skupinu velikosti . Pokud je výsledek negativní, je každá položka ve skupině prohlášena za nezávadnou; soubor a přejděte ke kroku 1. Jinak použijte a binární vyhledávání identifikovat jedno vadné a nespecifikované číslo, volané nezávadných položek; soubor a . Přejděte na krok 1.








Zobecněný algoritmus binárního rozdělení nevyžaduje více než testy kde.[3]


Pro velké, lze to ukázat ,[3] který se příznivě srovnává s testy požadované pro Li - fázový algoritmus. Ve skutečnosti je zobecněný algoritmus binárního dělení blízký optimálnímu v následujícím smyslu. Když lze to ukázat , kde je informace dolní mez.[3][14]






Neadaptivní algoritmy
Neadaptivní algoritmy pro testování skupin mají tendenci předpokládat, že je znám počet defektů nebo alespoň jejich dobrá horní hranice.[5] Toto množství je označeno v této části. Pokud nejsou známy žádné hranice, existují neadaptivní algoritmy s nízkou složitostí dotazů, které mohou pomoci odhadnout .[21]
Pronásledování kombinatorickým ortogonálním párováním (COMP)

Combinatorial Orthogonal Matching Pursuit neboli COMP je jednoduchý neadaptivní algoritmus pro testování skupin, který tvoří základ složitějších algoritmů, které následují v této části.
Nejprve je vybrána každá položka testovací matice i.i.d. být s pravděpodobností a v opačném případě.

Krok dekódování pokračuje po sloupcích (tj. Po položkách). Pokud je každý test, ve kterém se položka objeví, pozitivní, pak je položka prohlášena za vadnou; jinak se předpokládá, že položka není vadná. Nebo ekvivalentně, pokud se položka objeví v testu, jehož výsledek je negativní, je položka prohlášena za nezávadnou; jinak se předpokládá, že je vadný. Důležitou vlastností tohoto algoritmu je, že nikdy nevytváří falešné negativy, ačkoli falešně pozitivní nastane, když všechna místa s těmi v j-tý sloupec (odpovídá nezávadnému zboží j) jsou „skryty“ ostatními sloupci odpovídajícími vadným položkám.
Algoritmus COMP nevyžaduje více než testy, jejichž pravděpodobnost chyby je menší nebo rovna .[5] To je v rámci konstantního faktoru dolní meze pro průměrnou pravděpodobnost chyby výše.

V hlučném případě uvolní požadavek v původním algoritmu COMP, aby množina pozic těch v libovolném sloupci odpovídající kladné položce budou zcela obsaženy v sadě umístění jedniček ve vektoru výsledků. Místo toho jeden umožňuje určitý počet „neshod“ - tento počet nesouladů závisí jak na počtu jednotek v každém sloupci, tak také na parametru šumu, . Tento hlučný algoritmus COMP nevyžaduje více než testy k dosažení maximální pravděpodobnosti chyby .[5]

Určité vady (DD)
Metoda definitivních defektů (DD) je rozšířením algoritmu COMP, který se pokouší odstranit jakékoli falešné poplachy. Ukázalo se, že výkonnostní záruky pro DD přísně překračují záruky COMP.[19]
Krok dekódování využívá užitečnou vlastnost algoritmu COMP: že každá položka, kterou COMP deklaruje jako nezávadnou, je určitě nezávadná (to znamená, že neexistují žádné falešné negativy). Postupuje následovně.
- Nejprve je spuštěn algoritmus COMP a odstraněny všechny závady, které detekuje. Všechny zbývající položky jsou nyní „pravděpodobně vadné“.
- Algoritmus dále zkoumá všechny pozitivní testy. Pokud se položka v testu objeví jako jediná „možná vadná“, pak musí být vadná, takže algoritmus ji prohlásí za vadnou.
- Předpokládá se, že všechny ostatní položky nejsou vadné. Odůvodnění tohoto posledního kroku vychází z předpokladu, že počet defektů je mnohem menší než celkový počet položek.
Všimněte si, že kroky 1 a 2 nikdy neudělají chybu, takže algoritmus může udělat chybu, pouze pokud deklaruje vadnou položku za nezávadnou. Algoritmus DD tedy může vytvářet pouze falešné negativy.
Sekvenční COMP (SCOMP)
SCOMP (Sequential COMP) je algoritmus, který využívá skutečnosti, že DD nedělá chyby až do posledního kroku, kdy se předpokládá, že zbývající položky nejsou vadné. Nechť je soubor deklarovaných vad . Pozitivní test se nazývá vysvětleno podle pokud obsahuje alespoň jednu položku v systému Windows . Klíčovým poznatkem u SCOMP je, že sada defektů nalezená DD nemusí vysvětlovat každý pozitivní test a že každý nevysvětlený test musí obsahovat skrytý defekt.

Algoritmus probíhá následovně.
- Proveďte kroky 1 a 2 algoritmu DD, které chcete získat , počáteční odhad pro soubor defektů.
- Li vysvětluje každý pozitivní test, ukončete algoritmus: je konečný odhad pro soubor defektů.
- Pokud existují nějaké nevysvětlené testy, najděte „možný defekt“, který se objeví v největším počtu nevysvětlených testů, a prohlédněte jej jako defektní (tj. Přidejte jej do sady ). Přejděte na krok 2.
V simulacích se ukázalo, že SCOMP funguje téměř optimálně.[19]
Ukázkové aplikace
Obecnost teorie skupinového testování ji propůjčuje mnoha různým aplikacím, včetně screeningu klonů, lokalizace elektrických zkratů;[3] vysokorychlostní počítačové sítě;[22] lékařské vyšetření, vyhledávání množství, statistiky;[16] strojové učení, sekvenování DNA;[23] kryptografie;[24][25] a datová forenzní.[26] Tato část poskytuje stručný přehled malého výběru těchto aplikací.
Kanály pro více přístupů

A kanál více přístupů je komunikační kanál, který spojuje mnoho uživatelů najednou. Každý uživatel může poslouchat a vysílat na kanálu, ale pokud vysílá více než jeden uživatel současně, signály se srazí a sníží se na nesrozumitelný šum. Kanály pro více procesů jsou důležité pro různé aplikace v reálném světě, zejména bezdrátové počítačové sítě a telefonní sítě.[27]
Prominentním problémem u kanálů s více přístupy je, jak přiřadit přenosové časy uživatelům, aby se jejich zprávy nekolidovaly. Jednoduchou metodou je poskytnout každému uživateli svůj vlastní časový úsek, ve kterém má vysílat, což vyžaduje sloty. (Tomu se říká multiplexování s časovým dělením, nebo TDM.) To je však velmi neefektivní, protože přiřadí přenosové sloty uživatelům, kteří nemusí mít zprávu, a obvykle se předpokládá, že v daném okamžiku bude chtít vysílat pouze několik uživatelů - jinak multiaccess kanál není praktické na prvním místě.
V kontextu skupinového testování je tento problém obvykle řešen rozdělením času na „epochy“ následujícím způsobem.[3] Uživateli se říká „aktivní“, pokud má na začátku epochy zprávu. (If a message is generated during an epoch, the user only becomes active at the start of the next one.) An epoch ends when every active user has successfully transmitted their message. The problem is then to find all the active users in a given epoch, and schedule a time for them to transmit (if they have not already done so successfully). Here, a test on a set of users corresponds to those users attempting a transmission. The results of the test are the number of users that attempted to transmit, a , corresponding respectively to no active users, exactly one active user (message successful) or more than one active user (message collision). Therefore, using an adaptive group testing algorithm with outcomes , it can be determined which users wish to transmit in the epoch. Then, any user that has not yet made a successful transmission can now be assigned a slot to transmit, without wastefully assigning times to inactive users.


Machine learning and compressed sensing
Strojové učení is a field of computer science that has many software applications such as DNA classification, fraud detection and targeted advertising. One of the main subfields of machine learning is the 'learning by examples' problem, where the task is to approximate some unknown function when given its value at a number of specific points.[3] As outlined in this section, this function learning problem can be tackled with a group-testing approach.
In a simple version of the problem, there is some unknown function, kde , a (using logical arithmetic: addition is logical OR and multiplication is logical AND). Tady je ' sparse', which means that at most of its entries are . The aim is to construct an approximation to použitím point evaluations, where je co nejmenší.[4] (Exactly recovering corresponds to zero-error algorithms, whereas is approximated by algorithms that have a non-zero probability of error.)






In this problem, recovering is equivalent to finding . Navíc, if and only if there is some index, , kde . Thus this problem is analogous to a group-testing problem with defectives and total items. The entries of are the items, which are defective if they are , specifies a test, and a test is positive if and only if .[4]



In reality, one will often be interested in functions that are more complicated, such as , again where . Komprimované snímání, which is closely related to group testing, can be used to solve this problem.[4]

In compressed sensing, the goal is to reconstruct a signal, , by taking a number of measurements. These measurements are modelled as taking the dot product of with a chosen vector.[h] The aim is to use a small number of measurements, though this is typically not possible unless something is assumed about the signal. One such assumption (which is common[30][31]) is that only a small number of entries of jsou významný, meaning that they have a large magnitude. Since the measurements are dot products of , rovnice holds, where je matrix that describes the set of measurements that have been chosen and is the set of measurement results. This construction shows that compressed sensing is a kind of 'continuous' group testing.





The primary difficulty in compressed sensing is identifying which entries are significant.[30] Once that is done, there are a variety of methods to estimate the actual values of the entries.[32] This task of identification can be approached with a simple application of group testing. Here a group test produces a complex number: the sum of the entries that are tested. The outcome of a test is called positive if it produces a complex number with a large magnitude, which, given the assumption that the significant entries are sparse, indicates that at least one significant entry is contained in the test.
There are explicit deterministic constructions for this type of combinatorial search algorithm, requiring Měření.[33] However, as with group-testing, these are sub-optimal, and random constructions (such as COMP) can often recover sub-linearly in .[32]


Multiplex assay design for COVID19 testing
During a pandemic such as the COVID-19 outbreak in 2020, virus detection assays are sometimes run using nonadaptive group testing designs.[34][35] One example was provided by the Origami Assays project which released open source group testing designs to run on a laboratory standard 96 well plate.[36]

In a laboratory setting, one challenge of group testing is the construction of the mixtures can be time-consuming and difficult to do accurately by hand. Origami assays provided a workaround for this construction problem by providing paper templates to guide the technician on how to allocate patient samples across the test wells.[37]
Using the largest group testing designs (XL3) it was possible to test 1120 patient samples in 94 assay wells. If the true positive rate was low enough, then no additional testing was required.
Viz také: Seznam zemí implementujících strategii testování fondů proti COVID-19.
Data forensics
Data forensics is a field dedicated to finding methods for compiling digital evidence of a crime. Such crimes typically involve an adversary modifying the data, documents or databases of a victim, with examples including the altering of tax records, a virus hiding its presence, or an identity thief modifying personal data.[26]
A common tool in data forensics is the one-way cryptographic hash. This is a function that takes the data, and through a difficult-to-reverse procedure, produces a unique number called a hash.[i] Hashes, which are often much shorter than the data, allow us to check if the data has been changed without having to wastefully store complete copies of the information: the hash for the current data can be compared with a past hash to determine if any changes have occurred. An unfortunate property of this method is that, although it is easy to tell if the data has been modified, there is no way of determining how: that is, it is impossible to recover which part of the data has changed.[26]
One way to get around this limitation is to store more hashes – now of subsets of the data structure – to narrow down where the attack has occurred. However, to find the exact location of the attack with a naive approach, a hash would need to be stored for every datum in the structure, which would defeat the point of the hashes in the first place. (One may as well store a regular copy of the data.) Group testing can be used to dramatically reduce the number of hashes that need to be stored. A test becomes a comparison between the stored and current hashes, which is positive when there is a mismatch. This indicates that at least one edited datum (which is taken as defectiveness in this model) is contained in the group that generated the current hash.[26]
In fact, the amount of hashes needed is so low that they, along with the testing matrix they refer to, can even be stored within the organisational structure of the data itself. This means that as far as memory is concerned the test can be performed 'for free'. (This is true with the exception of a master-key/password that is used to secretly determine the hashing function.)[26]
Poznámky
- ^ The original problem that Dorfman studied was of this nature (although he did not account for this), since in practice, only a certain number of blood sera could be pooled before the testing procedure became unreliable. This was the main reason that Dorfman’s procedure was not applied at the time.[3]
- ^ However, as is often the case in mathematics, group testing has been subsequently re-invented multiple times since then, often in the context of applications. For example, Hayes independently came up with the idea to query groups of users in the context of multiaccess communication protocols in 1978.[9]
- ^ This is sometimes referred to as the Hu-Hwang-Wang conjecture.
- ^ The number of tests, , must scale as for deterministic designs, compared to for designs that allow arbitrarily small probabilities of error (as a ).[4]
- ^ One must be careful to distinguish between when a test reports a false result and when the group-testing procedure fails as a whole. It is both possible to make an error with no incorrect tests and to not make an error with some incorrect tests. Most modern combinatorial algorithms have some non-zero probability of error (even with no erroneous tests), since this significantly decreases the number of tests needed.
- ^ In fact it is possible to do much better. For example, Li's -stage algorithm gives an explicit construction were .
- ^ Alternativně lze definovat rovnicí , where multiplication is logické AND () and addition is logické NEBO (). Tady, will have a v poloze kdyby a jen kdyby a jsou oba pro všechny . That is, if and only if at least one defective item was included in the test.
- ^ This kind of measurement comes up in many applications. For example, certain kinds of digital camera[28] or MRI machines,[29] where time constraints require that only a small number of measurements are taken.
- ^ More formally hashes have a property called collision resistance, which is that the likelihood of the same hash resulting from different inputs is very low for data of an appropriate size. In practice, the chance that two different inputs might produce the same hash is often ignored.











Reference
Citace
- ^ Colbourn, Charles J.; Dinitz, Jeffrey H. (2007), Handbook of Combinatorial Designs (2nd ed.), Boca Raton: Chapman & Hall/ CRC, str. 574, Section 46: Pooling Designs, ISBN 978-1-58488-506-1
- ^ A b C Dorfman, Robert (December 1943), "The Detection of Defective Members of Large Populations", Annals of Mathematical Statistics, 14 (4): 436–440, doi:10.1214/aoms/1177731363, JSTOR 2235930
- ^ A b C d E F G h i j k l m n Ó p q r s t u proti w Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapur: World Scientific. ISBN 978-9810212933.
- ^ A b C d E F G h i Atia, George Kamal; Saligrama, Venkatesh (March 2012). "Boolean compressed sensing and noisy group testing". Transakce IEEE na teorii informací. 58 (3): 1880–1901. arXiv:0907.1061. doi:10.1109/TIT.2011.2178156.
- ^ A b C d E F G h i j Chun Lam Chan; Pak Hou Che; Jaggi, Sidharth; Saligrama, Venkatesh (1 September 2011), "2011 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton)", 49th Annual Allerton Conference on Communication, Control, and Computing, pp. 1832–1839, arXiv:1107.4540, doi:10.1109/Allerton.2011.6120391, ISBN 978-1-4577-1817-5
- ^ Hung, M.; Swallow, William H. (March 1999). "Robustness of Group Testing in the Estimation of Proportions". Biometrie. 55 (1): 231–237. doi:10.1111/j.0006-341X.1999.00231.x. PMID 11318160.
- ^ Chen, Hong-Bin; Fu, Hung-Lin (April 2009). "Nonadaptive algorithms for threshold group testing". Diskrétní aplikovaná matematika. 157 (7): 1581–1585. doi:10.1016/j.dam.2008.06.003.
- ^ De Bonis, Annalisa (20 July 2007). "New combinatorial structures with applications to efficient group testing with inhibitors". Journal of Combinatorial Optimization. 15 (1): 77–94. doi:10.1007/s10878-007-9085-1.
- ^ Hayes, J. (August 1978). "An adaptive technique for local distribution". Transakce IEEE na komunikaci. 26 (8): 1178–1186. doi:10.1109/TCOM.1978.1094204.
- ^ Sterrett, Andrew (December 1957). "On the detection of defective members of large populations". Annals of Mathematical Statistics. 28 (4): 1033–1036. doi:10.1214/aoms/1177706807.
- ^ Sobel, Milton; Groll, Phyllis A. (September 1959). "Group testing to eliminate efficiently all defectives in a binomial sample". Technický deník Bell System. 38 (5): 1179–1252. doi:10.1002/j.1538-7305.1959.tb03914.x.
- ^ Li, Chou Hsiung (June 1962). "A sequential method for screening experimental variables". Journal of the American Statistical Association. 57 (298): 455–477. doi:10.1080/01621459.1962.10480672.
- ^ Katona, Gyula O.H. (1973). "A survey of combinatorial theory". Combinatorial Search Problems. North-Holland, Amsterdam: 285–308.
- ^ A b C d Hwang, Frank K. (September 1972). "A method for detecting all defective members in a population by group testing". Journal of the American Statistical Association. 67 (339): 605–608. doi:10.2307/2284447. JSTOR 2284447.
- ^ Allemann, Andreas (2013). "An efficient algorithm for combinatorial group testing". Information Theory, Combinatorics, and Search Theory: 569–596.
- ^ A b Hu, M. C.; Hwang, F. K .; Wang, Ju Kwei (June 1981). "A Boundary Problem for Group Testing". SIAM Journal o algebraických a diskrétních metodách. 2 (2): 81–87. doi:10.1137/0602011.
- ^ Leu, Ming-Guang (28 October 2008). "A note on the Hu–Hwang–Wang conjecture for group testing". The ANZIAM Journal. 49 (4): 561. doi:10.1017/S1446181108000175.
- ^ Riccio, Laura; Colbourn, Charles J. (1 January 2000). "Sharper bounds in adaptive group testing". Taiwanský žurnál matematiky. 4 (4): 669–673. doi:10.11650/twjm/1500407300.
- ^ A b C d Aldridge, Matthew; Baldassini, Leonardo; Johnson, Oliver (June 2014). "Group Testing Algorithms: Bounds and Simulations". Transakce IEEE na teorii informací. 60 (6): 3671–3687. arXiv:1306.6438. doi:10.1109/TIT.2014.2314472.
- ^ Baldassini, L.; Johnson, O.; Aldridge, M. (1 July 2013), "2013 IEEE International Symposium on Information Theory", IEEE International Symposium on Information Theory, pp. 2676–2680, arXiv:1301.7023, CiteSeerX 10.1.1.768.8924, doi:10.1109/ISIT.2013.6620712, ISBN 978-1-4799-0446-4
- ^ Sobel, Milton; Elashoff, R. M. (1975). "Group testing with a new goal, estimation". Biometrika. 62 (1): 181–193. doi:10.1093/biomet/62.1.181. hdl:11299/199154.
- ^ Bar-Noy, A .; Hwang, F. K .; Kessler, I.; Kutten, S. (1 May 1992). A new competitive algorithm for group testing. Eleventh Annual Joint Conference of the IEEE Computer and Communications Societies. 2. pp. 786–793. doi:10.1109/INFCOM.1992.263516. ISBN 978-0-7803-0602-8.
- ^ Damaschke, Peter (2000). "Adaptive versus nonadaptive attribute-efficient learning". Strojové učení. 41 (2): 197–215. doi:10.1023/A:1007616604496.
- ^ Stinson, D. R.; van Trung, Tran; Wei, R (May 2000). "Secure frameproof codes, key distribution patterns, group testing algorithms and related structures". Journal of Statistical Planning and Inference. 86 (2): 595–617. CiteSeerX 10.1.1.54.6212. doi:10.1016/S0378-3758(99)00131-7.
- ^ Colbourn, C. J.; Dinitz, J. H.; Stinson, D. R. (1999). "Communications, Cryptography, and Networking". Průzkumy v kombinatorice. 3 (267): 37–41. doi:10.1007/BF01609873.
- ^ A b C d E Goodrich, Michael T .; Atallah, Mikhail J.; Tamassia, Roberto (7 June 2005). Indexing information for data forensics. Aplikovaná kryptografie a zabezpečení sítě. Přednášky z informatiky. 3531. pp. 206–221. CiteSeerX 10.1.1.158.6036. doi:10.1007/11496137_15. ISBN 978-3-540-26223-7.
- ^ Chlebus, B. S. (2001). "Randomized communication in radio networks". In: Pardalos, P. M.; Rajasekaran, S .; Reif, J .; Rolim, J. D. P. (Eds.), Handbook of Randomized Computing, Sv. I, p.401–456. Kluwer Academic Publishers, Dordrecht.
- ^ Takhar, D.; Laska, J. N .; Wakin, M. B.; Duarte, M. F .; Baron, D .; Sarvotham, S.; Kelly, K. F.; Baraniuk, R. G. (February 2006). "A new compressive imaging camera architecture using optical-domain compression". Electronic Imaging. Computational Imaging IV. 6065: 606509–606509–10. Bibcode:2006SPIE.6065...43T. CiteSeerX 10.1.1.114.7872. doi:10.1117/12.659602.
- ^ Candès, E. J. (2014). "Mathematics of sparsity (and a few other things)". Sborník příspěvků z mezinárodního kongresu matematiků. Soul, Jižní Korea.
- ^ A b Gilbert, A. C.; Iwen, M. A.; Strauss, M. J. (October 2008). "Group testing and sparse signal recovery". 42nd Asilomar Conference on Signals, Systems and Computers: 1059–1063. Institute of Electrical and Electronics Engineers.
- ^ Wright, S. J.; Nowak, R. D.; Figueiredo, M. A. T. (July 2009). "Sparse Reconstruction by Separable Approximation". Transakce IEEE při zpracování signálu. 57 (7): 2479–2493. Bibcode:2009ITSP...57.2479W. CiteSeerX 10.1.1.142.749. doi:10.1109/TSP.2009.2016892.
- ^ A b Berinde, R.; Gilbert, A. C.; Indyk, P .; Karloff, H.; Strauss, M. J. (September 2008). Combining geometry and combinatorics: A unified approach to sparse signal recovery. 46th Annual Allerton Conference on Communication, Control, and Computing. pp. 798–805. arXiv:0804.4666. doi:10.1109/ALLERTON.2008.4797639. ISBN 978-1-4244-2925-7.
- ^ Indyk, Piotr (1 January 2008). "Explicit Constructions for Compressed Sensing of Sparse Signals". Proceedings of the Nineteenth Annual ACM-SIAM Symposium on Discrete Algorithms: 30–33.
- ^ Austin, David. "AMS Feature Column — Pooling strategies for COVID-19 testing". Americká matematická společnost. Citováno 2020-10-03.
- ^ Prasanna, Dheeraj. "Tapestry pooling". tapestry-pooling.herokuapp.com. Citováno 2020-10-03.
- ^ „Origami Assays“. Origami Assays. 2. dubna 2020. Citováno 7. dubna 2020.
- ^ „Origami Assays“. Origami Assays. 2. dubna 2020. Citováno 7. dubna 2020.
Obecné odkazy
- Ding-Zhu, Du; Hwang, Frank K. (1993). Combinatorial group testing and its applications. Singapur: World Scientific. ISBN 978-9810212933.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2007), Lectures 7.
- Atri Rudra's course on Error Correcting Codes: Combinatorics, Algorithms, and Applications (Spring 2010), Lectures 10, 11, 28, 29
- Du, D., & Hwang, F. (2006). Pooling Designs and Nonadaptive Group Testing. Boston: Twayne Publishers.
- Aldridge, M., Johnson, O. and Scarlett, J. (2019), Group Testing: An Information Theory Perspective, Foundations and Trends® in Communications and Information Theory: Vol. 15: No. 3-4, pp 196-392. doi:10.1561/0100000099
- Ely Porat, Amir Rothschild: Explicit Non-adaptive Combinatorial Group Testing Schemes. ICALP (1) 2008: 748–759
- Kagan, Eugene; Ben-gal, Irad (2014), "A group testing algorithm with online informational learning", Transakce IIE, 46 (2): 164–184, doi:10.1080/0740817X.2013.803639, ISSN 0740-817X