Shlukování datového proudu - Data stream clustering - Wikipedia
v počítačová věda, shlukování datového proudu je definován jako shlukování dat, která přicházejí nepřetržitě, jako jsou telefonní záznamy, multimediální data, finanční transakce atd. Shlukování datových toků je obvykle studováno jako a streamovací algoritmus a cílem je, vzhledem k posloupnosti bodů, vybudovat dobré shlukování proudu pomocí malého množství paměti a času.
Dějiny
Shlukování datových proudů v poslední době přitahuje pozornost nově vznikajících aplikací, které zahrnují velké množství datových proudů. Pro shlukování, k-prostředky je široce používaná heuristika, ale byly také vyvinuty alternativní algoritmy, jako např k-medoidy, LÉK a populární[Citace je zapotřebí ] BŘÍZA. U datových toků se jeden z prvních výsledků objevil v roce 1980[1] ale model byl formován v roce 1998.[2]
Definice
Problém shlukování datových proudů je definován jako:
Vstup: posloupnost n body v metrickém prostoru a celé číslo k.
Výstup: k centra v souboru n body tak, aby se minimalizoval součet vzdáleností od datových bodů k jejich nejbližším centrům klastru.
Toto je streamovaná verze problému k-medián.
Algoritmy
PROUD
STREAM je algoritmus pro shlukování datových toků, který popsali Guha, Mishra, Motwani a O'Callaghan[3] který dosahuje a aproximace konstantního faktoru pro problém k-Median v jednom průchodu a za použití malého prostoru.
Teorém — STREAM může vyřešit k-Median problém v datovém proudu v jednom průchodu, s časem Ó(n1+E) a prostor θ(nε) až na faktor 2O (1 /E), kde n počet bodů a .

Abychom pochopili STREAM, je prvním krokem ukázat, že shlukování může probíhat na malém prostoru (nezáleží na počtu průchodů). Small-Space je a algoritmus rozděl a panuj který rozděluje data, S, do kousky, shluky každý z nich (pomocí kznamená) a poté seskupí získaná centra.

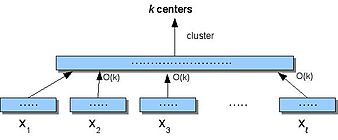
Algoritmus malého prostoru (S)
- Rozdělit S do nesouvislé kousky .
- Pro každého i, najít centra v Xi. Přiřadit každý bod v Xi do nejbližšího centra.
- Nechat X' být centra získaná v (2), kde každé centrum C je vážen počtem přidělených bodů.
- Klastr X' najít k centra.



Kde, pokud v kroku 2 spustíme bicriteria -aproximační algoritmus který vystupuje nanejvýš ak mediány s náklady maximálně b krát optimální řešení k-Median a v kroku 4 spustíme a C-aproximační algoritmus, pak je aproximační faktor algoritmu Small-Space () . Můžeme také zobecnit Small-Space tak, že se rekurzivně nazývá i krát na postupně menší sadě vážených center a dosahuje konstantní přibližné hodnoty faktoru k k-mediánský problém.


Problém malého prostoru spočívá v počtu podmnožin že rozdělujeme S do je omezený, protože musí ukládat do paměti mezilehlé mediány X. Takže když M je velikost paměti, musíme rozdělit S do podmnožiny takové, že se každá podmnožina vejde do paměti, () a tak, aby vážený centra se vejdou také do paměti, . Ale takový nemusí vždy existovat.



Algoritmus STREAM řeší problém ukládání středních mediánů a dosahuje lepších požadavků na čas a prostor. Algoritmus funguje následovně:[3]
- Zadejte první m body; pomocí randomizovaného algoritmu uvedeného v[3] snížit je na (řekněme 2k) body.
- Opakujte výše uvedené, dokud jsme neviděli m2/(2k) původních datových bodů. Nyní máme m střední mediány.
- Používat místní vyhledávání algoritmus, seskupte je m mediány první úrovně do 2k mediánů druhé úrovně a pokračovat.
- Obecně platí, že nanejvýš m úroveň-i mediánů a na vidění m, generovat 2k úroveň-i+ 1 mediánů, přičemž váha nového mediánu je součtem hmotností středních mediánů, které mu byly přiřazeny.
- Když jsme viděli všechny původní datové body, shlukujeme všechny mezilehlé mediány k konečné mediány pomocí primitivního duálního algoritmu.[4]
Další algoritmy
Další dobře známé algoritmy používané pro shlukování datových proudů jsou:
- BŘÍZA:[5] vytváří hierarchickou datovou strukturu k postupnému shlukování příchozích bodů pomocí dostupné paměti a minimalizaci požadovaného množství I / O. Složitost algoritmu je protože jeden průchod stačí k získání dobrého shlukování (výsledky však lze zlepšit povolením několika průchodů).
- PAVUČINA:[6][7] je přírůstková klastrová technika, která udržuje a hierarchické shlukování model v podobě a klasifikační strom. Pro každý nový bod COBWEB sestupuje stromem, aktualizuje uzly podél cesty a hledá nejlepší uzel, na který se bod umístí (pomocí funkce užitkové kategorie ).
- C2ICM:[8] staví strukturu shlukování plochých oddílů výběrem některých objektů jako klastrových semen / iniciátorů a semenu, které poskytuje nejvyšší pokrytí, je přiřazeno jiné semeno, přidání nových objektů může zavést nová semena a zfalšovat některá stávající stará semena, během přírůstkového seskupování nové objekty a členové padělaných shluků jsou přiřazeni k jednomu ze stávajících nových / starých semen.
- CluStream:[9] používá mikroklastry, které jsou časovým rozšířením BŘÍZA [5] vektor funkcí klastru, aby mohl rozhodnout, zda lze mikroklastr nově vytvořit, sloučit nebo zapomenout na základě analýzy čtverce a lineárního součtu aktuálních datových bodů a časových značek mikroklastrů a poté v kterémkoli bodě čas je možné generovat makroklastry seskupením těchto mikroklasterů pomocí offline clusterovacího algoritmu K-prostředky, čímž se získá konečný výsledek shlukování.

Reference
- ^ Munro, J .; Paterson, M. (1980). „Výběr a třídění s omezeným úložištěm“. Teoretická informatika. 12 (3): 315–323. doi:10.1016/0304-3975(80)90061-4.
- ^ Henzinger, M .; Raghavan, P .; Rajagopalan, S. (srpen 1998). "Výpočet na datových tocích". Digital Equipment Corporation. TR-1998-011. CiteSeerX 10.1.1.19.9554.
- ^ A b C Guha, S .; Mishra, N .; Motwani, R .; O'Callaghan, L. (2000). "Shlukování datových toků". Sborník z výročního sympozia o základech informatiky: 359–366. CiteSeerX 10.1.1.32.1927. doi:10.1109 / SFCS.2000.892124. ISBN 0-7695-0850-2.
- ^ Jain, K .; Vazirani, V. (1999). Algoritmy primární-duální aproximace pro metrické umístění zařízení a k-mediánové problémy. Proc. FOCS. Focs '99. s. 2–. ISBN 9780769504094.
- ^ A b Zhang, T .; Ramakrishnan, R .; Linvy, M. (1996). "BIRCH: Efektivní metoda shlukování dat pro velmi velké databáze". Sborník konferencí ACM SIGMOD o správě dat. 25 (2): 103–114. doi:10.1145/235968.233324.
- ^ Fisher, D. H. (1987). „Získávání znalostí prostřednictvím postupného koncepčního shlukování“. Strojové učení. 2 (2): 139–172. doi:10.1023 / A: 1022852608280.
- ^ Fisher, D. H. (1996). "Iterativní optimalizace a zjednodušení hierarchických shluků". Journal of AI Research. 4. arXiv:cs / 9604103. Bibcode:1996cs ........ 4103F. CiteSeerX 10.1.1.6.9914.
- ^ Can, F. (1993). "Inkrementální shlukování pro dynamické zpracování informací". Transakce ACM v informačních systémech. 11 (2): 143–164. doi:10.1145/130226.134466.
- ^ Aggarwal, Charu C .; Yu, Philip S .; Han, Jiawei; Wang, Jianyong (2003). „Rámec pro shlukování vyvíjejících se datových toků“ (PDF). Proceedings 2003 VLDB Conference: 81–92. doi:10.1016 / B978-012722442-8 / 50016-1.