Algoritmus zapomínající na mezipaměť - Cache-oblivious algorithm - Wikipedia
v výpočetní, a algoritmus bez paměti cache (nebo cache-transcendentní algoritmus) je algoritmus navržen tak, aby využíval výhody a Mezipaměť CPU aniž byste měli velikost mezipaměti (nebo délku řádky mezipaměti atd.) jako explicitní parametr. An optimální algoritmus vynechávající mezipaměť je algoritmus zapomínající na mezipaměť, který optimálně využívá mezipaměť (v asymptotické smysl, ignorující konstantní faktory). Algoritmus ignorující mezipaměť je tedy navržen tak, aby fungoval dobře, bez úprav, na více počítačích s různými velikostmi mezipaměti nebo pro hierarchie paměti s různými úrovněmi mezipaměti, které mají různé velikosti. Algoritmy vynechávající mezipaměť jsou porovnány s explicitními blokování, jako v optimalizace smyčkového hnízda, který explicitně rozdělí problém na bloky, které jsou optimálně dimenzovány pro danou mezipaměť.
Jsou známy optimální algoritmy, které nepotřebují mezipaměť násobení matic, transpozice matice, třídění a několik dalších problémů. Některé obecnější algoritmy, například Cooley – Tukey FFT, jsou za určitých voleb parametrů optimálně zapomínáni na mezipaměť. Protože tyto algoritmy jsou optimální pouze v asymptotickém smyslu (ignorování konstantních faktorů), může být vyžadováno další ladění specifické pro stroj, aby se získal téměř optimální výkon v absolutním smyslu. Cílem algoritmů ignorujících mezipaměť je snížit množství takového ladění, které je požadováno.
Algoritmus bez paměti cache obvykle pracuje a rekurzivní algoritmus rozděl a panuj, kde je problém rozdělen na menší a menší dílčí problémy. Nakonec jeden dosáhne velikosti dílčího problému, který se vejde do mezipaměti, bez ohledu na velikost mezipaměti. Například optimální násobení matice vynechávající mezipaměť se získá rekurzivním rozdělením každé matice na čtyři dílčí matice, které se mají znásobit, vynásobením dílčích matic v nejdříve do hloubky móda. Při ladění konkrétního stroje lze použít a hybridní algoritmus který používá blokování vyladěné pro konkrétní velikosti mezipaměti na spodní úrovni, ale jinak používá algoritmus vynechání mezipaměti.
Dějiny
Myšlenka (a název) algoritmů vynechávajících mezipaměť byla vytvořena pomocí Charles E. Leiserson již v roce 1996 a poprvé publikováno Harald Prokop ve své diplomové práci na Massachusetts Institute of Technology v roce 1999.[1] Bylo mnoho předchůdců, obvykle analyzujících konkrétní problémy; tyto jsou podrobně diskutovány v Frigo et al. 1999. První citované příklady zahrnují Singleton 1969 pro rekurzivní rychlou Fourierovu transformaci, podobné myšlenky v Aggarwal et al. 1987, Frigo 1996 pro množení matic a rozklad LU a Todd Veldhuizen 1996 pro maticové algoritmy v Blitz ++ knihovna.
Idealizovaný model mezipaměti
Algoritmy zapomínající na mezipaměť se obvykle analyzují pomocí idealizovaného modelu mezipaměti, někdy nazývaného mezipaměťový model. Tento model je mnohem snazší analyzovat než vlastnosti skutečné mezipaměti (které mají komplikovanou asociativitu, zásady nahrazování atd.), Ale v mnoha případech je prokazatelně v konstantním faktoru výkonu realističtější mezipaměti. Je to jiné než model externí paměti protože algoritmy ignorující mezipaměť neznají velikost bloku nebo mezipaměti velikost.
Zejména model nevyžadující mezipaměť je abstraktní stroj (tj. teoretický model výpočtu ). Je to podobné jako u Model stroje RAM který nahrazuje Turingův stroj nekonečná páska s nekonečným polem. Ke každému umístění v poli lze přistupovat čas, podobný paměť s náhodným přístupem na skutečném počítači. Na rozdíl od modelu stroje RAM zavádí také mezipaměť: druhou úroveň úložiště mezi RAM a CPU. Další rozdíly mezi těmito dvěma modely jsou uvedeny níže. V modelu zapomínajícím na mezipaměť:

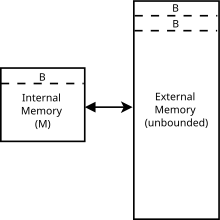


- Paměť je rozdělena do bloků každý objekt
- Náklad nebo obchod mezi hlavní paměť a registr CPU nyní může být obsluhován z mezipaměti.
- Pokud nelze z paměti cache obsluhovat zátěž nebo obchod, nazývá se to a miss miss.
- Chybějící mezipaměť vede k načtení jednoho bloku z hlavní paměti do mezipaměti. Jmenovitě, pokud se CPU pokusí o přístup ke slovu a je řádek obsahující , pak je načten do mezipaměti. Pokud byla mezipaměť dříve plná, bude řádek také vystěhován (viz zásady nahrazování níže).
- Mezipaměť má objekty, kde . Toto je také známé jako vysoký předpoklad mezipaměti.
- Mezipaměť je plně asociativní: každý řádek lze načíst do libovolného místa v mezipaměti.[2]
- Zásady nahrazování jsou optimální. Jinými slovy se předpokládá, že mezipaměti bude během provádění algoritmu dána celá posloupnost přístupů do paměti. Pokud potřebuje vystěhovat linku najednou , prozkoumá svoji posloupnost budoucích požadavků a vystěhuje linku, která je v budoucnu nejvzdálenější. To lze v praxi napodobit pomocí Nejméně uživaný v poslední době politika, která se ukázala být v malém konstantním faktoru offline optimální strategie nahrazení[3][4]





Abychom změřili složitost algoritmu, který se spouští v modelu zapomínajícím na mezipaměť, změříme počet chybí mezipaměť že algoritmus zažívá. Protože model zachycuje skutečnost, že přístup k prvkům v mezipaměti je mnohem rychlejší než přístup k věcem hlavní paměť, provozní doba algoritmu je definován pouze počtem přenosů paměti mezi mezipamětí a hlavní pamětí. To je podobné jako model externí paměti, což jsou všechny výše uvedené funkce, ale algoritmy ignorující mezipaměť jsou nezávislé na parametrech mezipaměti ( a ).[5] Výhodou takového algoritmu je to, že to, co je efektivní na stroji, který pamatuje mezipaměť, bude pravděpodobně efektivní napříč mnoha skutečnými stroji bez jemného doladění konkrétních parametrů skutečného stroje. Pro mnoho problémů bude optimální algoritmus vynechávající mezipaměť optimální také pro stroj s více než dvěma hierarchie paměti úrovně.[3]
Příklady

Například je možné navrhnout variantu rozvinuté propojené seznamy který pamatuje mezipaměť a umožňuje procházení seznamu N prvky v čas, kde B je velikost mezipaměti v prvcích.[Citace je zapotřebí ] Pro pevné B, tohle je čas. Výhodou algoritmu však je, že může škálovat, aby využil výhod větších velikostí řádků mezipaměti (větší hodnoty B).


Nejjednodušší algoritmus zapomínající na mezipaměť uvedený v Frigo et al. je na místě maticová transpozice úkon (místní algoritmy byly také navrženy pro transpozici, ale jsou mnohem komplikovanější pro jiné než čtvercové matice). Dáno m×n pole A a n×m pole B, chtěli bychom uložit transpozici A v B. Naivní řešení prochází jedním polem v pořadí hlavních a druhým v hlavním sloupci. Výsledkem je, že když jsou matice velké, dostaneme mezipaměť miss na každém kroku sloupcového přechodu. Celkový počet zmeškaných mezipaměti je .

Algoritmus zapomínající na mezipaměť má optimální složitost práce a optimální složitost mezipaměti . Základní myšlenkou je snížit transpozici dvou velkých matic do transpozice malých (sub) matic. Děláme to dělením matic na polovinu podél jejich větší dimenze, dokud nebudeme muset provést transpozici matice, která se vejde do mezipaměti. Protože algoritmus nezná velikost mezipaměti, matice se budou i po tomto bodě rekurzivně dělit i nadále, ale tyto další členění budou v mezipaměti. Jednou rozměry m a n jsou dostatečně malé, takže vstup pole velikosti a výstupní pole velikosti aby se vešly do mezipaměti, výsledkem bude procházení hlavních řádků i hlavních sloupců pracovat a chybí mezipaměť. Použitím tohoto přístupu rozděl a panuj můžeme dosáhnout stejné úrovně složitosti pro celkovou matici.





(V zásadě lze pokračovat v dělení matic, dokud není dosaženo základního případu o velikosti 1 × 1, ale v praxi se používá větší základní případ (např. 16 × 16), aby amortizovat režie rekurzivních volání podprogramu.)
Většina algoritmů ignorujících mezipaměť se spoléhá na přístup rozděl a panuj. Snižují problém, takže se nakonec vejde do mezipaměti bez ohledu na to, jak malá je mezipaměť, a ukončí rekurzi v malé velikosti určené režií volání funkce a podobnými optimalizacemi nesouvisejícími s mezipamětí a poté použijí nějaký efektivní přístup do mezipaměti vzor sloučit výsledky těchto malých, vyřešených problémů.
Jako externí třídění v model externí paměti, třídění bez paměti je možné ve dvou variantách: trychtýř, který se podobá Sloučit třídění, a cache-lhostejná distribuce řazení, který se podobá quicksort. Stejně jako jejich protějšky z externí paměti oba dosahují a provozní doba z , který odpovídá a dolní mez a je tedy asymptoticky optimální.[5]

Viz také
Reference
- ^ Harald Prokop. Cache-Oblivious Algorithms. Diplomová práce, MIT. 1999.
- ^ Kumar, Piyush. „Algoritmy bez paměti cache“. Algoritmy pro hierarchie paměti. LNCS 2625. Springer Verlag: 193–212. CiteSeerX 10.1.1.150.5426.
- ^ A b Frigo, M .; Leiserson, C. E.; Prokop, H.; Ramachandran, S. (1999). Algoritmy zapomínající na mezipaměť (PDF). Proc. IEEE Symp. o základech informatiky (FOCS). str. 285–297.
- ^ Daniel Sleator, Robert Tarjan. Amortizovaná účinnost pravidel aktualizace seznamu a stránkování. v Komunikace ACM, Svazek 28, číslo 2, s. 202-208. Únor 1985.
- ^ A b Erik Demaine. Algoritmy a datové struktury vynechávající mezipaměť, in Lecture Notes from the EEF Summer School on Massive Data Sets, BRICS, University of Aarhus, Denmark, June 27 - July 1, 2002.