Střídavý rozhodovací strom - Alternating decision tree - Wikipedia
An střídavý rozhodovací strom (ADTree) je a strojové učení metoda klasifikace. Zobecňuje to rozhodovací stromy a má spojení s posílení.
ADTree se skládá ze střídání rozhodovacích uzlů, které určují podmínku predikátu, a predikčních uzlů, které obsahují jedno číslo. Instance je klasifikována podle ADTree sledováním všech cest, pro které jsou všechny rozhodovací uzly pravdivé, a sečtením všech předpovědních uzlů, které jsou procházeny.
Dějiny
ADTrees byly zavedeny Yoav Freund a Llew Mason.[1] Algoritmus, jak byl předložen, však měl několik typografických chyb. Vyjasnění a optimalizace později představili Bernhard Pfahringer, Geoffrey Holmes a Richard Kirkby.[2] Implementace jsou k dispozici v Weka a JBoost.
Motivace
Originál posílení obvykle používané algoritmy rozhodovací pařezy nebo rozhodovací stromy jako slabé hypotézy. Jako příklad posílení rozhodovací pařezy kreativní sada vážené rozhodovací pařezy (kde je počet podporujících iterací), které poté hlasují o konečné klasifikaci podle jejich váhy. Jednotlivé rozhodovací pařezy jsou váženy podle jejich schopnosti klasifikovat data.

Posílení jednoduchého studenta vede k nestrukturované sadě hypotézy, takže je těžké odvodit korelace mezi atributy. Střídavé rozhodovací stromy zavádějí strukturu do souboru hypotéz tím, že vyžadují, aby vytvářely hypotézu, která byla vytvořena v dřívější iteraci. Výsledný soubor hypotéz lze vizualizovat ve stromu na základě vztahu mezi hypotézou a jejím „rodičem“.
Další důležitou vlastností posílených algoritmů je, že se datům dává jiný rozdělení při každé iteraci. Instanci, které jsou nesprávně klasifikovány, se přidělí větší váha, zatímco přesně klasifikovaným instancím se přidělí snížená váha.
Střídavá struktura rozhodovacího stromu
Střídavý rozhodovací strom se skládá z rozhodovacích uzlů a predikčních uzlů. Rozhodovací uzly určit podmínku predikátu. Predikční uzly obsahovat jedno číslo. ADTrees mají vždy predikční uzly jako root i listy. Instance je klasifikována pomocí ADTree sledováním všech cest, pro které jsou všechny rozhodovací uzly pravdivé, a sečtením všech předpovědních uzlů, které jsou procházeny. To se liší od binárních klasifikačních stromů, jako je CART (Klasifikační a regresní strom ) nebo C4.5 ve kterém instance sleduje pouze jednu cestu stromem.
Příklad
Následující strom byl sestaven pomocí JBoost na datové sadě spambase[3] (k dispozici v úložišti strojového učení UCI).[4] V tomto příkladu je spam kódován jako 1 a běžný e-mail je kódován jako −1.
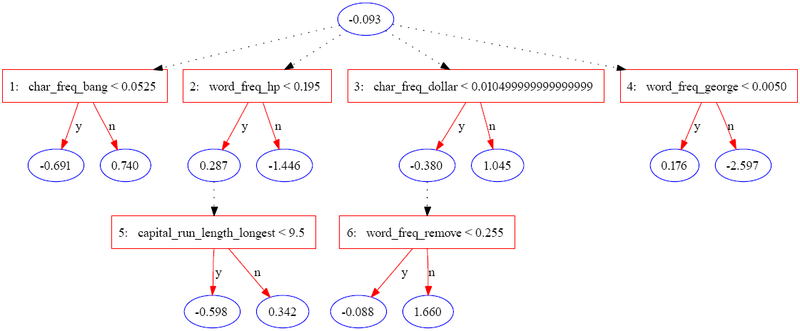
Následující tabulka obsahuje část informací pro jednu instanci.
| Vlastnosti | Hodnota |
|---|---|
| char_freq_bang | 0.08 |
| word_freq_hp | 0.4 |
| capital_run_length_longest | 4 |
| char_freq_dollar | 0 |
| word_freq_remove | 0.9 |
| word_freq_george | 0 |
| Další funkce | ... |
Instance je hodnocena součtem všech predikčních uzlů, kterými prochází. V případě výše uvedené instance se skóre vypočítá jako
| Opakování | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| Hodnoty instance | N / A | .08 < .052 = F | .4 < .195 = F | 0 < .01 = t | 0 < 0.005 = t | N / A | .9 < .225 = F |
| Předpověď | -0.093 | 0.74 | -1.446 | -0.38 | 0.176 | 0 | 1.66 |
Konečné skóre 0.657 je pozitivní, takže instance je klasifikována jako spam. Velikost hodnoty je mírou spolehlivosti v predikci. Původní autoři uvádějí tři potenciální úrovně interpretace sady atributů identifikovaných ADTree:
- Jednotlivé uzly lze hodnotit podle jejich vlastní prediktivní schopnosti.
- Sady uzlů na stejné cestě lze interpretovat tak, že mají společný efekt
- Strom lze interpretovat jako celek.
Při interpretaci jednotlivých uzlů je třeba postupovat opatrně, protože skóre odrážejí váhu dat v každé iteraci.
Popis algoritmu
Vstupy do algoritmu střídavého rozhodovacího stromu jsou:
- Sada vstupů kde je vektor atributů a je buď -1 nebo 1. Vstupy se také nazývají instance.
- Sada závaží odpovídající každé instanci.




Základním prvkem algoritmu ADTree je pravidlo. Singlerule se skládá z předběžné podmínky, podmínky a dvou skóre. Podmínka je predikátem formy „atribut
1 -li (předpoklad) 2 -li (podmínka) 3 vrátit se score_one4 jiný5 vrátit se score_two6 skončit, pokud7 jiný8 vrátit se 09 skončit, pokud
Algoritmus také vyžaduje několik pomocných funkcí:
- vrací součet vah všech pozitivně označených příkladů, které splňují predikát
- vrací součet vah všech negativně označených příkladů, které splňují predikát
- vrací součet vah všech příkladů, které splňují predikát




Algoritmus je následující:
1 funkce ad_tree2 vstup Sada m tréninkové instance3 4 wi = 1/m pro všechny i5 6 R0 = pravidlo se skóre A a 0, podmínka „true“ a podmínka „true“. 7 8 soubor všech možných podmínek9 pro 10 získejte hodnoty které minimalizují 11 12 13 14 Rj = nové pravidlo s podmínkou p, podmínka Ca váhy A1 a A215 16 konec pro17 vrátit se sada Rj










Sada roste o dvě předpoklady v každé iteraci a je možné odvodit stromovou strukturu sady pravidel pomocí poznámky o předpokladech použitých v každém následném pravidle.

empirické výsledky
Obrázek 6 v původním papíru[1] ukazuje, že ADTrees jsou typicky stejně robustní jako zesílené rozhodovací stromy a zesílené rozhodovací pařezy. Ekvivalentní přesnosti lze obvykle dosáhnout mnohem jednodušší stromovou strukturou než rekurzivní algoritmy dělení.
Reference
- ^ A b Yoav Freund a Llew Mason. Algoritmus alternačního rozhodovacího stromu. Sborník ze 16. mezinárodní konference o strojovém učení, strany 124-133 (1999)
- ^ Bernhard Pfahringer, Geoffrey Holmes a Richard Kirkby. Optimalizace indukce střídavých rozhodovacích stromů. Sborník příspěvků z páté tichomořské a asijské konference o pokroku v získávání znalostí a dolování dat. 2001, str. 477-487
- ^ „Úložiště strojového učení UCI“. Ics.uci.edu. Citováno 2012-03-16.
- ^ „Úložiště strojového učení UCI“. Ics.uci.edu. Citováno 2012-03-16.
externí odkazy
- Úvod do Boosting a ADTrees (Má mnoho grafických příkladů střídání rozhodovacích stromů v praxi).
- JBoost software implementující ADTrees.